IDENTIFYING THE GENETIC MATERIAL DR. A. TARAB DEPT. OF BIOCHEMISTRY HKMU
|
|
|
- Howard White
- 5 years ago
- Views:
Transcription
1 IDENTIFYING THE GENETIC MATERIAL DR. A. TARAB DEPT. OF BIOCHEMISTRY HKMU
2 EARLY HYPOTHESES Most people look somewhat like a mixture of their parents In general, certain traits are passed on from one generation to the next This genetic information must be stored somewhere in the cell, but just how or where eluded biologists for a long time
3 Eventually, microscopists noticed that during cell division, the sister chromatid pairs split, and each corresponding chromosome became part of a different daughter cell This phenomenon suggested to biologists that the chromosomes must in some way contain the genetic information, especially since cells which obtained an abnormal number of chromosomes failed to function
4 However, chemical analysis showed that the chromosomes were made of two major components DNA and protein DNA was, at the time, thought to be a much simpler molecule than proteins, which scientists knew came in many varieties and combinations
5 So, it seemed logical that they hypothesized that protein was the genetic material But by the late 1920s and 1930s, experimental evidence began to mount that DNA was in fact the bearer of genetic information
6 THE FAMOUS DNA EXPERIMENTS In 1928, an experiment completely unrelated to the field of genetics led to an astounding discovery about DNA Frederick Griffith, a bacteriologist, was trying to prepare a vaccine against pneumonia Streptococcus pneumoniae ( abbreviated S. pneumoniae) is a prokaryote (of the type commonly called a bacterium) that causes pneumonia
7 Griffith worked with two strains of S. pneumoniae the first strain is enclosed in a capsule composed of polysaccharides The capsule protects the bacterium from the body s defense systems This helps make the microorganism virulent (i.e able to cause disease) Because of the capsule, this strain of S. pneumoniae grows as smooth-edged (S) colonies when grown in a Petri dish
8 The second strain of S. pneumoniae lacks the polysaccharide capsule and does not cause disease When grown in a Petri dish, the second strain forms rough-edged (R) colonies Griffith first injected mice with a live strain of virulent bacteria, and not to anyone s surprise, all of those mice died
9 Then, he killed the virulent bacteria cells by heating them Mice injected with these heat-killed virulent bacteria did not die In another set of mice, Griffith injected a live non-virulent strain of bacteria, and these mice did not die The surprise came when Griffith injected a group of mice with both live non-virulent bacteria and heat-killed virulent bacteria
10 In that group, some of the mice died When Griffith examined those mice, he found that the live R bacteria had changed and became virulent S bacteria Griffith drew the conclusion that the genetic information in the heat-killed virulent bacteria survived the heating process and was somehow incorporated into the genetic material of the nonvirulent strain to cause them to become virulent
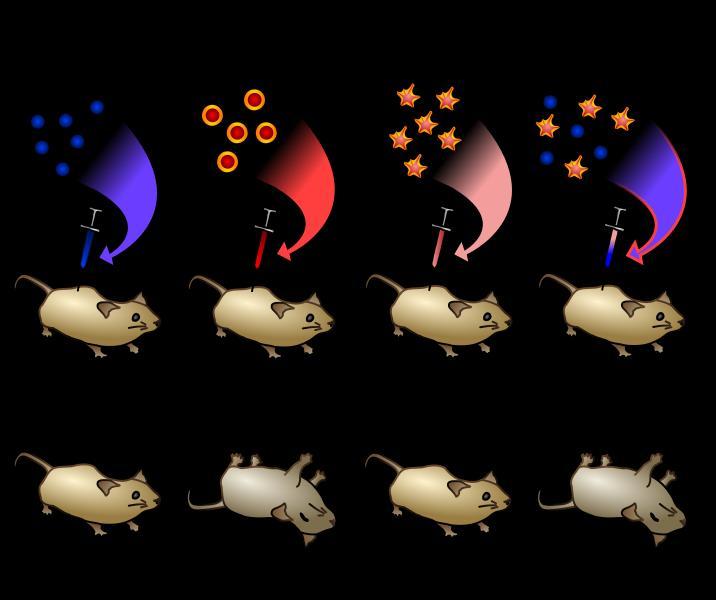
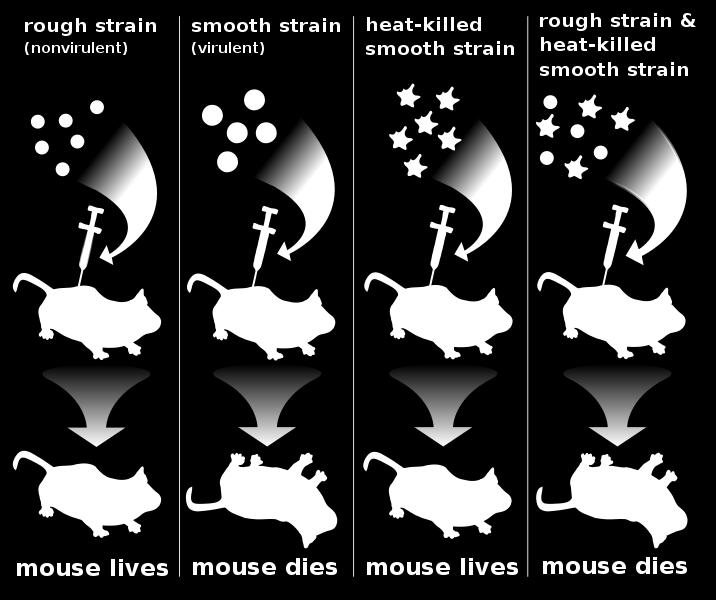
11
12 But Griffith knew that heat denatures protein, so he suggested that the genetic material must be something else However, his results did not specifically point to DNA as a possibility Griffith had discovered what is now called transformation Transformation is a change in genotype caused when cells take up foreign genetic material But the cause of transformation was not known at the time
13 Oswald Avery followed up on Griffith s experiments in the following decade Like Griffith, Avery first used heat to kill virulent bacteria He then extracted RNA, DNA, carbohydrates, lipids and proteins from these dead cells, all of which were considered to be possible candidates for the carriers of genetic information
14 Next, he added each type of molecule to a culture of live non-virulent bacteria to determine which was responsible for changing them into virulent bacteria as Griffith had observed Only the non-virulent cells which were given DNA from the dead virulent strain became virulent So Avery concluded that DNA must be the genetic material
15 Discovering DNA s Structure In 1949, Erwin Chargaff made an interesting observation about DNA Chargaff s data showed that for each organism he studied, the amount of adenine always equaled the amount of thymine (A = T) Likewise, the amount of guanine always equaled the amount of cytosine (G = C) However, the amount of adenine and thymine and of guanine and cytosine varied between different organisms
16 The significance of Chargaff s data became clear in the 1950s when scientists began using X-ray diffraction to study the structure of molecules In X-ray diffraction, a beam of X rays is directed at an object The X rays bounce of the object and are scattered in a pattern onto a piece of film By analyzing the complex patterns on the film, scientists can determine the structure of the molecule
17 In 1952, Maurice Wilkins and Rosalind Franklin developed high quality X-ray diffraction photographs of strands of DNA These photographs suggested that the DNA molecule resembled a tightly coiled helix and was composed of two or three chains of nucleotides In 1953, James Watson and Francis Crick used this information, along with their knowledge of chemical bonding, to come up with the solution

18 X-ray diffraction photograph of a hydrated DNA fiber The central cross is diagnostic of a helical structure The strong arcs on the meridian arise from the stack of nucleotide bases, which are 3.4 Å apart


19 James Watson and Francis Crick
20 Watson and Crick determined that a DNA molecule is a double helix two strands twisted around each other, like a winding staircase Each strand is made of linked nucleotides A nucleotide consists of a phosphate group, a five-carbon sugar (deoxyribose in DNA and ribose in RNA), and a nitrogenous base bonded together
, per turn. (a) Schematic representation, showing dimensions of the helix. (b) Stick representation showing the backbone and stacking of the bases.")
21 Watson-Crick model for the The original model proposed by Watson and Crick had 10 base pairs, or 34 Å (3.4 nm), per turn of the helix; subsequent measurements revealed 10.5 base pairs, or 36 Å (3.6 nm), per turn. (a) Schematic representation, showing dimensions of the helix. (b) Stick representation showing the backbone and stacking of the bases. (c) Space-filling model. structure of DNA
22 Exploring a DNA chain The sugars in the backbone The backbone of DNA is based on a repeated pattern of a sugar group and a phosphate group The full name of DNA, deoxyribonucleic acid, gives you the name of the sugar present deoxyribose

23 Deoxyribose Deoxyribose is a modified form of another sugar called ribose Deoxyribose, as the name might suggest, is ribose which has lost an oxygen atom - "de-oxy"


24 Ribose is the sugar in the backbone of RNA, ribonucleic acid Ribose

25 Numbering of carbon atoms
26 You will notice that each of the numbers has a small dash by it - 3' or 5', for example If you just had ribose or deoxyribose on its own, that wouldn't be necessary, but in DNA and RNA these sugars are attached to other ring compounds
27 The carbons in the sugars are given the little dashes so that they can be distinguished from any numbers given to atoms in the other rings You read 3' or 5' as "3-prime" or "5-prime"

28 Attaching a phosphate group The other repeating part of the DNA backbone is a phosphate group A phosphate group is attached to the sugar molecule in place of the OH group on the 5 carbon
29 Each nucleotide in a DNA molecule has one of four nitrogenous bases: adenine, guanine, thymine and cytosine The first two are called purine bases because their structure consists of two rings of atoms The latter two are known as pyrimidine bases, since they have a single ring of atoms RNA has three of the same nucleotides, but instead of thymine, RNA has uracil another pyrimidine base

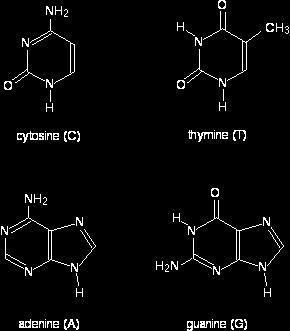
30
31 The nitrogen and hydrogen atoms shown in blue on each molecule show where these molecules join on to the deoxyribose In each case, the hydrogen is lost together with the -OH group on the 1' carbon atom of the sugar This is a condensation reaction - two molecules joining together with the loss of a small one (not necessarily water).

32 The final piece we need to add before we can build a DNA strand is one of the four complicated bases cytosine, thymine, adenine and guanine These bases attach in place of the OH group on the 1 carbon atom in the sugar ring What we have produced is known as a nucleotide Attaching a base


33 For example, here is what the nucleotide containing cytosine would look like

34 Joining the nucleotides in a DNA A DNA strand is simply a string of nucleotides joined together The phosphate group on one nucleotide links to the 3 carbon atom of the sugar of another one In the process, a molecule of water is lost a condensation reaction strand
35 Building a DNA chain Joining up lots of nucleotides gives you a part of a DNA chain The diagram below is a bit from the middle of a chain Notice that the individual bases have been identified by the first letters of the base names. (A = adenine, etc)
36 Notice also that there are two different sizes of base Adenine and guanine are bigger because they both have two rings Cytosine and thymine only have one ring each

37 DNA strand

38 Joining the two DNA chains If you look at this carefully, you will see that an adenine on one chain is always paired with a thymine on the second chain And a guanine on one chain is always paired with a cytosine on the other one together
39 The first thing to notice is that a smaller base is always paired with a bigger one The effect of this is to keep the two chains at a fixed distance from each other all the way along But, more than this, the pairing has to be exactly...
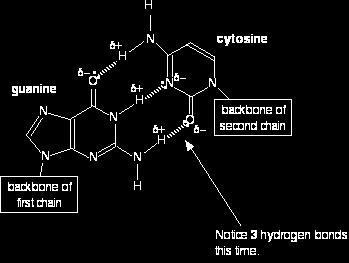
40 adenine (A) pairs with thymine (T); guanine (G) pairs with cytosine (C) That is because these particular pairs fit exactly to form very effective hydrogen bonds with each other It is these hydrogen bonds which hold the two chains together

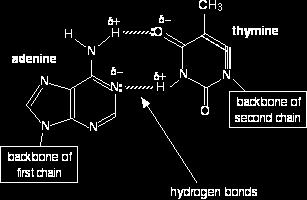
41 The A T base pair

42 The C G base pair

43 A final structure for DNA showing the important bits
44 Notice that the two chains run in opposite directions, and the right-hand chain is essentially upside-down You will also notice that the ends of these bits of chain are labbeled with 3' and 5 If you followed the left-hand chain to its very end at the top, you would have a phosphate group attached to the 5' carbon in the deoxyribose ring
45 If you followed it all the way to the other end, you would have an -OH group attached to the 3' carbon In the second chain, the top end has a 3' carbon, and the bottom end a 5'
46 Note how the DNA resembles a ladder twisted like a spiral staircase The sugar-phosphate backbones are similar to the side rails of a ladder The paired nitrogen bases are similar to the rungs of the ladder The nitrogen bases face each other The double helix is held together by weak hydrogen bonds between the pairs of bases
47 Structures of the base pairs proposed by Watson and Crick
48 Pairing between bases Watson and Crick determined that a purine on one strand of DNA is always paired with a pyrimidine on the opposite strand More specifically, an adenine on one strand always pairs with a thymine on the opposite strand, and a guanine on one strand always pairs with a cytosine on the opposite strand The structure and size of the nitrogen bases allows for only these two paired combinations
49 These base-pairing rules are supported by Chargaff s observations Adenine forms two hydrogen bonds with thymine, and cytosine forms three hydrogen bonds with guanine The hydrogen bonds between the nitrogen bases keep the two strands of DNA together The strictness of base-pairing results in two strands that contain complementary base pairs
50 That is, the sequence of bases on one strand determines the sequence of bases on the other strand For example, if the sequence of nitrogen bases on one strand of a DNA molecule is TCGAACT; the sequence of nitrogen bases on the other strand must be AGCTTGA
51 One final point about DNA s structure is that the opposite sides of the helix are said to be antiparallel That means they run in opposite directions At the very end of each side of the molecule is, of course a nucleotide At one end, the phosphate group is the very last molecule, while at the other end, the sugar molecule is the last one
52 Scientists have dubbed the end with the phosphate group the 5 end (read five prime), and the end with the sugar the 3 end Since the sides of the helix are antiparallel, the 3 end on one side of the ladder is opposite the 5 end on the other side