Genome 373: High- Throughput DNA Sequencing. Doug Fowler
|
|
|
- Collin Waters
- 5 years ago
- Views:
Transcription
1 Genome 373: High- Throughput DNA Sequencing Doug Fowler

2 Tasks give ML unity We learned about three tasks that are commonly encountered in ML
3 Models/Algorithms Give ML Diversity Classification Regression Clustering We covered a handful of the many models that can be employed to solve these tasks
4 Models/Algorithms Give ML Diversity Classification Regression Clustering Decision trees Random forests K-nearest neighbor Neural networks Naïve Bayes classifier SVM Perceptron SVR Linear regression Kernel regression Generalized linear models K-means Expectation-max Hierarchical Mean-shift Density-based Graph-based Biclustering We learned about three tasks that are commonly encountered in ML

5 ML In Genomics Has Been Driven By an Onslaught of Data
6 Outline HTS technology and a bit of history HTS applications: a data onslaught The future
7




8 DNA sequencing throughput 's 1,000's 1,000,000's nucleotides sequenced per day per instrument 1,000,000,000's
9 How? New Sequencing Paradigms How does Sanger sequencing work? Sanger sequencing
10 How? New Sequencing Paradigms Each DNA molecule of interest is amplified and sequenced separately Sanger sequencing

 and sequenced")
11 How? New Sequencing Paradigms Massively parallel sequencing Sanger sequencing Millions of DNA molecules are amplified (maybe) and sequenced in parallel
12 Two different strategies for parallel amplification BRIDGE PCR EMULSION PCR
13 How Does PCR Work?
14 Bridge PCR To Amplify DNA Cluster generating primer #2 DNA to be sequenced Cluster generating primer #1 The DNA to be sequenced is prepared by attaching cluster generating primers to each end
15 Bridge PCR To Amplify DNA Single stranded DNA molecules are attached a glass flowcell seeded with surface-bound cluster generation primers
16 Bridge PCR To Amplify DNA Templates are annealed to the complimentary surfacebound cluster generating primers
17 Bridge PCR To Amplify DNA A single-stranded bridge Templates are annealed to the complimentary surfacebound cluster generating primers
18 Bridge PCR To Amplify DNA A double-stranded bridge DNA polymerase extends the annealed primer
19 Bridge PCR To Amplify DNA This completes one cycle of bridge PCR (note we now have two surface-bound copies of each template)
20 Bridge PCR To Amplify DNA Repeated cycles result in many copies of each clonal template per cluster The clusters form a randomly addressed DNA array

21 Bridge PCR Lends Itself to an Optical Readout A single Illumina NextSeq flowcell will contain ~400,000,000 clusters each grown from an individual DNA molecule
22 Massively Parallel DNA Sequencing A T Cycle 1 C A G G T A C Cycle 2 G A T A G G A C C A Cycle 3 T T C C C G G T AGT GAC ACG CTT GGC TAA TAG AGC CCT What is Base 1? What is Base 2? What is Base 3? One cycle: 1. Polymerase extension with fluorescent nucleotides 2. Imaging of the slide 3. Cleave & wash
23 109-plex à effective reagent volume of femotoliters per sequencing reaction
24 Two different strategies for parallel amplification BRIDGE PCR EMULSION PCR
25 Emulsion PCR to amplify DNA As with bridge PCR we start by attaching amplification adapters to DNA template molecules
26 Emulsion PCR to amplify DNA Next we mix these template molecules with beads containing a single surface-bound amplification primer
27 Emulsion PCR to amplify DNA An emulsion is formed from template and beads such that each droplet gets one bead and one template (on average)

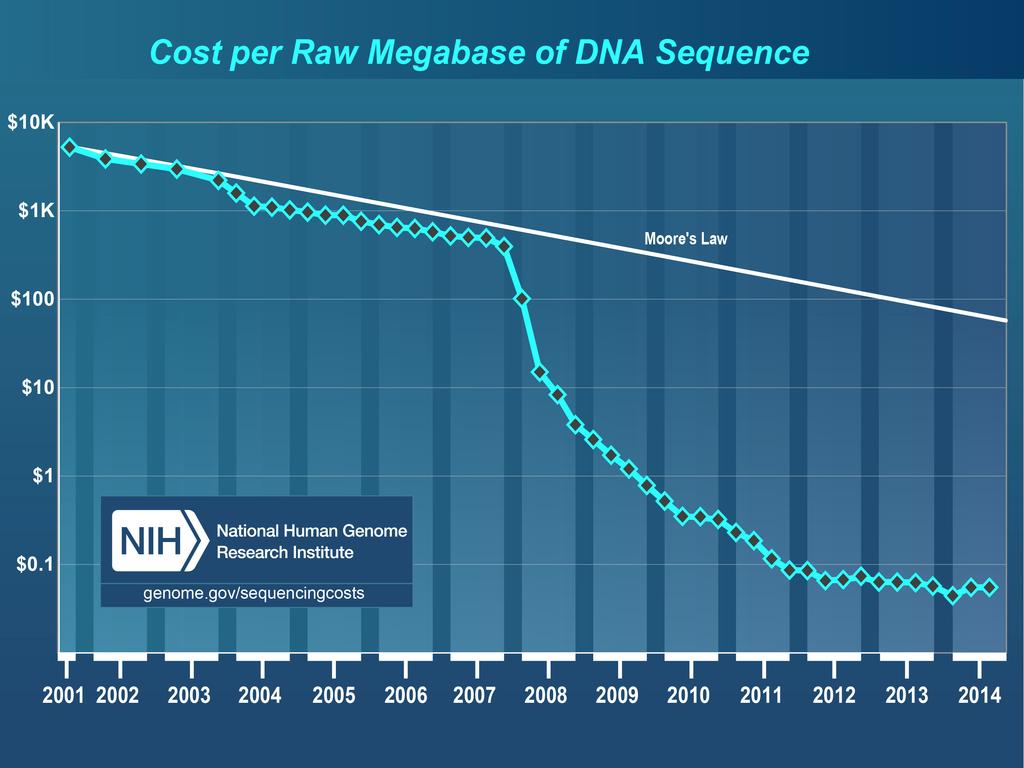
28 Emulsion PCR to amplify DNA An emulsion is a stable mixture of water droplets in oil each droplet is like a tiny PCR tube.
29 Emulsion PCR to amplify DNA The droplet contains all the ingredients necessary for PCR including the other primer and the polymerase
30 Emulsion PCR to amplify DNA The free template is annealed to a surface bound primer, extended with the polymerase and the new strand is melted off the bead. This is one cycle
31 Emulsion PCR to amplify DNA Multiple cycles result in clonal amplification of the single template DNA strand

32 Emulsion PCR to amplify DNA Finally, we break the emulsion and isolate beads with amplified product
33 So, what next? We now have millions of beads each with clonally amplified template strands what should we do next?
 2. ph change from reaction detected 3. Wash 4.")
34 Bead-Bound DNA Lends Itself to Microwells One cycle: 1. Add first NTP (e.g. ATP) 2. ph change from reaction detected 3. Wash 4. Repeat for each other NTP
 Clonal Amp emulsion PCR Sequencing ph microsensor Fedurco et al.")
35 Many ways to skin a cat Rothberg et al. (2011) Clonal Amp emulsion PCR Sequencing ph microsensor Fedurco et al. (2006) bridge PCR Optical imaging
36 2001:$3 billion
37 2001:$3 billion 2007:$100 million
38 2008:$1.5 million 2007:$100 million 2001:$3 billion







39 2015:$1, :$1.5 million 2007:$100 million 2001:$3 billion
 Paired end 100 bp reads >2 billion read- pairs >400 gigabases (Gb) of total output")
40 What can a sequencer do today? In 8 days (Illumina HiSeq 2000) Paired end 100 bp reads >2 billion read- pairs >400 gigabases (Gb) of total output 1 in 1,000 error rate for most base- calls IniEal drag of human genome based on 23 Gb
41 What s the catch? 1. Very short, error-laden sequence reads 2. Sequence biases (e.g. G+C content) 3. Days to weeks per instrument run 4. Substantial bioinformatics burden 5. It s cheap, but it still isn t free
42 Outline HTS technology and a bit of history HTS applications: a data onslaught The future

43 The ENCODE Project As An Example The goal of the Encyclopedia Of DNA Elements (ENCODE) was to identify all functional elements of the human genome This was a massive and audacious undertaking that generated a ridiculous quantity of data of multiple types The results are somewhat controversial, but a significant fraction of the human genome has some function

44 Where Did All This Data Come From? Every position in the genome was annotated with a huge amount of data on histone modifications, protein binding, accessibility, etc
45 HTS Enables High- Throughput Biology Biological phenomenon of interest We start with something we want to measure for each position in a genome
46 HTS Enables High- Throughput Biology Biological phenomenon of interest Sequencing-based assay Then, we develop a way to measure that phenomenon with sequencing
47 HTS Enables High- Throughput Biology Biological phenomenon of interest Sequencing-based assay Massively parallel way to measure the phenomenon A current-generation HT sequencer can collect ~400m reads each of which can be an individual measurement
48 HTS Enables High- Throughput Biology Biological phenomenon of interest Sequencing-based assay Massively parallel way to measure the phenomenon What are some things we might want to measure about positions in a genome?
49 DNA = machine-readable format for capturing biological information 1. Genetic variation in individuals 2. de novo genome assembly 3. Digital expression profiling (RNA-Seq) 4. Protein-DNA interactions (ChIP-Seq) 5. DNA accessibility (DNAse-Seq) 6. Methylation profiling (Methyl-Seq)
50 DNAse hypersensitivity: DNA Accessibility Why? DNA in the nucleus is not naked. Chromatin is a complex assembly of genomic DNA and proteins
51 DNAse hypersensitivity: DNA Accessibility We want to know where individual proteins bind to DNA
52 DNAse hypersensitivity: DNA Accessibility DNA is first digested with DNAse an enzyme that cleaves DNA when it is not blocked by other proteins
")
53 DNAse hypersensitivity: DNA Accessibility DNA is first digested with DNAse an enzyme that cleaves DNA when it is not blocked by other proteins Before HTS, individual loci were probed using Southern blots (e.g. gels followed by hybridization of radioactively labeled probe DNA)
54 DNAse-Seq: DNA Accessibility A first linker is ligated to mark the DNAse sensitive sites
55 DNAse-Seq: DNA Accessibility The DNA is digested with another nuclease to generate small fragments
56 DNAse-Seq: DNA Accessibility A second linker is added and the fragments are amplified Note, we now have a bunch of sequenceable fragments, one end of each corresponding to a DNAsesensitive site in the genome!
57 DNAse-Seq: DNA Accessibility Once we sequence our fragments, what informatics step do we need to take next?
58 DNAse-Seq: DNA Accessibility Alignment of the reads to the genome to find where the hypersensitive sites are!
59 DNAse-Seq: DNA Accessibility After read mapping we know the number of DNAse fragments at each position in the genome
60 DNAse-Seq: DNA Accessibility HTS reveals the number of DNAse fragments at each position in the genome This is a digital readout that tells us how sensitive to DNAse each site in the genome is (e.g. it s quantitative)
61 HTS-based Readouts Are Genomewide We can look at patterns of DNAse sensitivity across the whole genome every position has an attached DNAse reads data point
62 HTS-based Readouts Are Genomewide We can look at patterns of DNAse sensitivity across the whole genome every position has an attached DNAse reads data point
63 HTS-based Readouts Are Genomewide We can look at patterns of DNAse sensitivity across the whole genome every position has an attached DNAse reads data point
64 HTS-based Readouts Are Genomewide Based on the sequence of protected DNA we can predict what transcription factors bind in each location

65 HTS-based Readouts Are Exquisitely Sensitive We can actually see the effect of DNA contacts made by different transcription factors!
66 ChIP-Seq: Protein Binding How would you find the location of every binding site for a particular transcription factor?
67 ChIP-Seq: Protein Binding Crosslink DNA and proteins using formaldehyde (why?) then shear
68 ChIP-Seq: Protein Binding Use an antibody against the protein of interest to immunoprecipitate the protein-dna complexes

69 ChIP-Seq: Protein Binding Reverse chemical crosslinks and sequence DNA fragments

70 ChIP-Seq: Protein Binding Reverse chemical crosslinks and sequence DNA fragments
71 CCC (Chromosome Conformation Capture) Randomly assorted Nonrandom How do you guys think chromosomes are arranged within nuclei?
72 CCC (Chromosome Conformation Capture) Randomly assorted Nonrandom In fact, this is an active area of investigation and the degree to which chromosome conformation is ordered is unclear


73 CCC (Chromosome Conformation Capture) Randomly assorted Nonrandom How would you design an assay that could reveal chromosome conformation (hint: remember that in chromosomes DNA is coated with proteins)?
74 CCC (Chromosome Conformation Capture) The key idea is that we crosslink the proteins so that adjacent DNA is physically linked

75 CCC (Chromosome Conformation Capture)

76 CCC (Chromosome Conformation Capture) This is the conformation of chromosomes in the yeast nucleus as determined by sequencing!
77 Outline HTS technology and a bit of history HTS applications: a data onslaught The future
78 Single Molecule Sequencing Many of the problems of HTS inhere to: 1) Massively parallel DNA amplification (errors, etc) 2) Very short reads (mapping problems) What if we could sequence long, unamplified individual DNA molecules?
79 Single Molecule Sequencing: Fluorescent Uses zero-mode waveguide enables detection of fluorescence only very near the bottom of the nanowell
80 Single Molecule Sequencing: Fluorescent Each nanowell contains one DNA polymerase and one template DNA molecule
81 Single Molecule Sequencing: Fluorescent Sequencing is detected in real time by looking for pulses of fluorescence associated with base addition

82 Single Molecule Sequencing: Fluorescent Fluorophores are attached to the triphosphate group so they diffuse away from the detection volume rapidly!
83 Single Molecule Sequencing: Nanopores Protein nanopores enable water and ions to cross membranes
84 Single Molecule Sequencing: Nanopores The result is a current flow if there is a difference in potential across the membrane
85 Single Molecule Sequencing: Nanopores If a large molecule passes through the aperture of the pore, current flow is reduced
86 Single Molecule Sequencing: Nanopores Objects of different sizes cause different (and characteristic) current flows

87 Single Molecule Sequencing: Nanopores Sensing the different current flow induced by each different base is the key concept of nanopore sequencing