Introduction to Bioinformatics
|
|
|
- Clinton Reed
- 6 years ago
- Views:
Transcription
1 Introduction to Bioinformatics Dr. rer. nat. Jing Gong Cancer Research center Medicine School of Shandong University

2 Chapter 2 Databases 2

3 Why Do WE Need Databases? What s that? gcattac ttgatctaatca ataggatctaatctt tactagaacgcc ttgatctaatca ttgcaa 3


4 Why Do We Need Databases? This is the entire HIV1 genome containing total 9752 nucleotides with only 9 genes. gcattac ttgatctaatca ataggatctaatctt tactagaacgcc ttgatctaatca ttgcaa 4



5 Why Do We Need Databases? Human Genome : 3 Gbp = 3,000,000,000 bp 5000bp/page 600pages/book 1000 x 3cm/book 600,000 pages 1000 books = 30m bookshelf Over 1000 species : 26.6m 1000 x 30m-bookshelves 200 x 5 layers/bookshelf = 2 x 医学院图书馆 450,000 册 5



6 Why Do We Need Databases? 10cm All sequenced genomes: collect access x m update 14.6cm 1TB = 1000GB = 1,000,000MB = 1,000,000,000KB = 1.000,000,000,000B manage 6


7 History of Biological Databases Biological Databases - A biological database is a collection of data that is organized so that its contents can easily be accessed, managed, and updated. Biological databases make it possible to answer today s biological questions by enabling us to analyze sequences that may have been determined as many as 30 years ago, when the whole technology emerged. The first biological database was created within a short period after the Insulin protein sequence was made available in insulin = MALWMRLLPLLALLALWGPDPAAAFVNQHL CGSHLVEALYLVCGERGFFYTPKTRREAEDLQVGQVELGG GPGAGSLQPLALEGSLQKRGIVEQCCTSICSLYQLENYCN Frederick Sanger (1918-) nobel prize


8 History of Biological Databases Around mid 1960 s, the first nucleic acid sequence of Yeast trna with 77 bases was found out by Holley. During this period, three dimensional structure of proteins were studied and the well known Protein Data Bank was developed as the first protein structure database with only 10 entries in This has now grown into a large database with over 75,000 entries. Robert W. Holley ( ) nobel prize 1968 Max Ferdinand Perutz ( ) nobel prize 1962 John Cowdery Kendrew ( ) nobel prize
9 History of Biological Databases At beginning, the initial databases of protein sequences were maintained at the individual laboratories. The development of a consolidated formal database known as Swiss-Prot protein sequence database was initiated in Now it has about 530,000 protein sequences from more than 12,000 organisms. 9
10 History of Biological Databases The Los Alamos National Laboratory (USA) established the Los Alamos Sequence Database in 1979, which culminated in 1982 with the creation of the public GenBank. Later, the nucleotide sequence database of European Molecular Biology Laboratory (EMBL) and the DNA Data Bank of Japan (DDBJ) were created. Today these three databases represent the largest and fundamental biological databases and they together called International Nucleotide Sequence Database Collaboration (INSDC). 10
11 Classification of Biological Databases Nucleotide Database Protein Database >2000 Primary Nucleotide Database Primary Protein Database Protein Sequence DB Protein Structure DB INSDC UniProt Secondary Nucleotide Database Secondary Protein Database Specific Database 11
12 Classification of Biological Databases Nucleotide Database Protein Database >2000 Primary Nucleotide Database Primary Protein Database Protein Sequence DB Protein Structure DB INSDC UniProt Secondary Nucleotide Database Secondary Protein Database Specific Database 12
13 Nucleotide Databases Primary Nucleotide Database is produced and maintained by the National Center for Biotechnology Information ( NCBI ). The NCBI is a part of the National Institutes of Health ( ) in the United States ( ). GenBank receive sequences produced in laboratories throughout the world. In about 30 years since its establishment, Its data were accessed and cited by millions of researchers around the world. GenBank continues to grow at an exponential rate, doubling every 18 months. Release produced in 2008, contained over 99 billion nucleotide bases in more than 98 million sequences. 13
 member states and one associate member state, Australia ( ).")
), Hamburg ( ), Grenoble ( ), and Monterotondo ( ).")

14 Nucleotide Databases Primary Nucleotide Database The European Molecular Biology Laboratory (EMBL) is supported by 20 European ( ) member states and one associate member state, Australia ( ). It consists of five facilities: the main Laboratory in Heidelberg ( ), outstations in Hinxton (, the European Bioinformatics Institute (EBI)), Hamburg ( ), Grenoble ( ), and Monterotondo ( ). The EMBL Nucleotide Sequence Database constitutes Europe's primary nucleotide sequence resource. Main sources for DNA and RNA sequences are direct submissions from individual researchers, genome sequencing projects and patent applications. The current release contains 212 millions sequence entries comprising 326 billions nucleotides. 14
15 Nucleotide Databases Primary Nucleotide Database The DNA Data Bank of Japan (DDBJ) is a biological database that collects DNA sequences. It is located at the National Institute of Genetics ( ) in the Shizuoka ( 静冈 ) of Japan. DDBJ began data bank activities in 1986 at NIG and remains the only nucleotide sequence data bank in Asia. Although DDBJ mainly receives its data from Japanese researchers, it can accept data from contributors from any other country. The current release contains 138 millions sequence entries and 128 billions bases. 15
16 Nucleotide Databases Primary Nucleotide Database The International Nucleotide Sequence Database Collaboration (INSDC) consists of a joint effort to collect and disseminate databases containing DNA and RNA sequences New and updated data on nucleotide sequences contributed by research teams to each of the three databases are synchronized on a daily basis through continuous interaction between the staff at each the collaborating organizations. 16
17 Nucleotide Databases Reading into Genes and Genomes All living organisms can be sorted into one of two groups depending on the fundamental structure of their cells. These two groups are the prokaryotes (organisms lacking a true nucleus) and the eukaryotes (organisms having a true nucleus). archaea Nucleotide sequences are universal, but the structure of genes they encode is markedly different between prokaryotes and eukaryotes. prokaryotic cell eukaryotic cell 17


18 Nucleotide Databases Reading into Genes and Genomes Besides prokaryotes and eukaryotes, there is the third class of living organisms, archaea. They are bacteria-like organisms living in extreme conditions. In bioinformatic context, prokaryotes and archaea are very much the same. archaea prokaryotic cell eukaryotic cell 18
19 Nucleotide Databases Reading into Genes and Genomes Prokaryotes (archaea) have the following properties in common: They are microscopic organisms. Their genomes is single, circular DNA molecule. Their gene density is approximately one gene per 1,000 base pairs. Their genome contains few useless part (70% is coding for proteins). Their genes do not overlap. Their genes are transcribed to mrna right after a control region, called promoter. These mrna are collinear with the genome sequence. Protein sequences are derived by translating the longest open reading frame (ORF) spanning the gene-transcript sequence. 19
20 Nucleotide Databases Reading into Genes and Genomes Reading Frame - a reading frame is a way of breaking a DNA sequence into three letter codons which can be translated in amino acids. ORF x 3 x 3 = x 6 reading frames ORF (Open Reading Frame) - a DNA sequence that contains a start codon but does not contain a stop codon in a given reading frame. ATG Met (M) TAA TAG TGA 20
. Their genes do not overlap.")
21 Nucleotide Databases Reading into Genes and Genomes Prokaryotes (archaea) have the following properties in common: They are microscopic organisms. Their genomes is single, circular DNA molecule. Their gene density is approximately one gene per 1,000 base pairs. Their genome contains few useless part (70% is coding for proteins). Their genes do not overlap. Their genes are transcribed to mrna right after a control region, called promoter. These mrna are collinear with the genome sequence.. Protein sequences are derived by translating the longest open reading frame spanning the gene-transcript sequence. 21
22 Nucleotide Databases Reading into Genes and Genomes According to these common properties, database entries describing a coding prokaryotic sequence should include three important features: The coordinates of some promoter elements The coordinates of the RBS The coordinates of the ORF boundaries. Not all genes encode proteins. For some of them, the function is directly carried out by the transcribed RNA molecule, including trna, rrna and a few others. 22
23 Nucleotide Databases Reading into Genes and Genomes Eukaryotes have the following properties in common: Their genome consists of multiple linear pieces of DNA called chromosomes. Their genome size is much bigger than in prokaryotes. Their gene density is much lower than that for prokaryotes. Their genome is not efficient, containing many useless parts. Genes on opposite DNA strands might overlap, although that s a relatively rare occurrence. Their genes are transcribed right after a control region called a promoter, but sequence elements located far away can have a strong influence on this process. Gene sequences are not collinear with the final messenger RNA (mrna) and protein sequences. Only small bits (the exons) are retained in the mature mrna that encodes the final product. 23
24 Nucleotide Databases Reading into Genes and Genomes A few points between prokaryotes and eukaryotes: genome size gene density cording region content Is gene collinear? Has mrna introns? Prokaryotes million bp one gene / 1,000 bp 70% yes no Eukaryotes ,000 million bp One gene / 100,000 bp (human) 5% no yes Eu. Pro. 24
25 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase X
26 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase
27 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase 27
28 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase LOCUS gives us the locus name, the size of the nucleotide sequence in base pairs, the nature of the molecule, its topology and the last updated date. 28
29 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase DEFINITION provides a short definition of the gene that corresponds to the entry sequence. Here, it s the E. coli dut gene. This gene can encode the enzyme dutpase. The full name of dutpase is deoxyuridine 5 - triphosphate nucleotidohydrolase ( 脱氧尿苷焦磷酸酶 ). 29
30 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase ACCESSION lists the accession number - a unique identifier within and across various databases. Here, the accession number is X
31 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase VERSION fills you in on synonymous or past ID numbers. 31
32 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase KEYWORDS introduces a list of terms that broadly characterize the entry. You can use these terms as keywords for certain database searches. 32
33 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase SOURCE reveals the common name of the relevant organism to which the sequence belongs. 33
34 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase ORGANISM gives a more complete identification of the organism, complete with its technical taxonomic classification. 34
35 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase REFERENCE introduces a section where the credits for the sequence determination are given (different parts of the sequences can be credited to different authors). The REFERENCE section contains multiple parts: AUTHORS, TITLE, JOURNAL, and PUBMED. 35
36 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase COMMENT contains free-formatted text, such as acknowledgments or information that doesn t fit in the previous sections. 36
37 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase FEATURES describes the gene regions and the associated biological properties that have been identified in the nucleotide sequence. This entire section is under the control of the FEATURES keyword, such as source, promoter, etc. 37
38 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase source indicates the origin of specific regions of the sequence. This is useful when you want to distinguish cloning vectors from host sequences. In X01714, the whole sequence comes from E. coli genomic DNA. 38
39 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase promoter shows the coordinates of a promoter element. In X01714, a -35 region is indicated from position 286 to 291 in the nucleotide sequence. 39
40 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase misc feature (miscellaneous feature) indicates the putative location of the transcription start (mrna synthesis). For X01714, this is from positions 322 to
41 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase RBS (Ribosome Binding Site) indicates the location of the last upstream element. For X01714, this is at position 330 to
42 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase CDS (CoDing Segment) introduces a complex section that describes the gene s open reading frame (ORF). 42
43 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase The first line indicates the coordinates of the ORF from its initial ATG to the last nucleotide of the first stop codon TAA. 43
44 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase Each of the following lines gives the name of a protein product, indicates the reading frame to use (here, 343 is the first base of the first codon), the genetic code to apply, and a number of IDs for the protein sequence. 44
45 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase /translation introduces the conceptual amino-acid sequence of the coding segment. This sequence is a computer translation that uses the coordinates, reading frame, and genetic code indicated in the preceding lines. 45
46 Nucleotide Databases X misc feature contains lines that point out putative stem-loop structures and repeats. These are potential regulatory elements of the dutpase gene. 46
47 Nucleotide Databases X This entry exhibits an extra putative gene, indicated by an additional RBS element and a second CDS section. GenBank entries containing more than one gene are frequent. 47
.")
48 Nucleotide Databases X The last section is the nucleotide sequence section. It starts with the ORIGIN keyword and finishes with the end-of-entry line introduced by two slash marks (//). Each line of nucleotide sequence starts with the position number of the first nucleotide in that line. Each line contains 60 nucleotides. 48
49 Nucleotide Databases X Making sense of GenBank entry of a prokaryotic gene: E. coli dutpase 1. Way 2. Way 49
50 Nucleotide Databases U Making sense of GenBank entry of an eukaryotic mrna: human dutpase U

51 Nucleotide Databases U Making sense of GenBank entry of an eukaryotic mrna: human dutpase 51

52 Nucleotide Databases U Making sense of GenBank entry of an eukaryotic mrna: human dutpase A common problem in sequence databases: annotations may be incomplete. A word to the wise: You should never expect GenBank (or any sequence database) annotations to be up-to-date. 52
53 Nucleotide Databases U Making sense of GenBank entry of an eukaryotic mrna: human dutpase In the FEATURES section, the CDS indicates a coding region (63-821) sequence that corresponds to the mitochondrial form of human dutpase, following the conceptual amino-acid translation of the ORF. 53
54 Nucleotide Databases U Making sense of GenBank entry of an eukaryotic mrna: human dutpase The sig peptide keyword indicates the location of a mitochondrial targeting sequence, and the mat peptide keyword provides the exact boundaries of the mature peptide. 54
55 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry AF
56 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry This specifies that the entry encompasses exon 3 of the gene. 56
57 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry SEGMENT indicates that this current GenBank entry is the second segment of a super entry made of four. You need all four entries to reconstruct the complete mrna sequence used as a template for producing the protein. 57
58 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry The /map in the source section indicates that the sequence belongs to chromosome 15, and was more precisely mapped on the long arm (q) of this chromosome, within the q21.1 cytogenetic band. 58
59 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry The < at the beginning of the formula indicates that the gene might actually start before the indicated position, the > at the end of the formula indicates that the gene might actually continue beyond the indicated position. The gene keyword introduces complex-looking formulas. Their purpose is to describe precisely the reconstruction of the various mrnas spread over several separate entries. 59
60 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry 60
61 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry 61

62 Nucleotide Databases AF Making sense of GenBank entry of an eukaryotic genomic entry The exon keyword indicates the position of the sole exon present in this sequence. 62

![human [organism] http://www.ncbi.](/docs-images/78/77094422/images/63-2.jpg "nlm.nih.")
63 Nucleotide Databases Using a Gene-Centric Database DUT [gene] human [organism] 2 DUT [gene] human [organism]
![Nucleotide Databases Using a Gene-Centric Database DUT [gene] human [organism] http://www.ncbi.nlm.nih.](/docs-images/78/77094422/images/64-1.jpg "gov/ The top of the entry provides a general description of what this gene is all about and what function its products are known to perform, as well as a")
64 Nucleotide Databases Using a Gene-Centric Database DUT [gene] human [organism] The top of the entry provides a general description of what this gene is all about and what function its products are known to perform, as well as a large variety of links to other databases or NCBI files. 64
![Nucleotide Databases Using a Gene-Centric Database DUT [gene] human [organism]](/docs-images/78/77094422/images/65-1.jpg "http://www.ncbi.nlm.nih.")
65 Nucleotide Databases Using a Gene-Centric Database DUT [gene] human [organism] A schematic view of the Human DUT gene structure 65
![Nucleotide Databases Using a Gene-Centric Database DUT [gene] human [organism] http://www.ncbi.nlm.nih.](/docs-images/78/77094422/images/66-1.jpg "gov/ Other sections provide information on potential interactions with other gene products, protein functions, a list of all corresponding sequence entries in GenBank")
66 Nucleotide Databases Using a Gene-Centric Database DUT [gene] human [organism] Other sections provide information on potential interactions with other gene products, protein functions, a list of all corresponding sequence entries in GenBank and a large variety of links to other databases or NCBI files, etc. 66

67 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV

68 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV

69 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV

70 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV

71 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV
72 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV-1 This clickable picture indicates the identity and respective positions of all the genes. Global summary of the HIV-1 genome 72

73 Nucleotide Databases HIV-1 Working with complete viral genomes: HIV-1 A live map - allows you to zoom in/out on any genome region, down to the nucleotide sequence level. Viruses commonly have the same nucleotide sequence involved in the making of two different aminoacid sequences 73

74 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV

75 Nucleotide Databases Working with complete viral genomes: HIV-1 HIV-1 The Protein List page - you can retrieve the DNA and protein sequences in different formats, GenBank format, or FASTA format. 75
76 Nucleotide Databases Working with complete bacterial genomes at TIGR The Institute for Genome Research (TIGR) is home to a team of scientists who pioneered the field of bacterial genomics. TIGR is founded in 1992 by Craig Venter and is now a part of the J. Craig Venter Institute. In 1995, the scientists of TIGR produced the two first complete bacterial genomes. Since then, they have contributed to more than 700 complete bacterial genomes, with more on the way. TIGR offers a site that is quite complementary to the NCBI resource because it keeps track of all ongoing bacterial genome sequencing projects (not only of the completed ones). TIGR home page:

77 Nucleotide Databases Working with complete bacterial genomes at TIGR 77

78 Nucleotide Databases Working with complete bacterial genomes at TIGR 78

79 Nucleotide Databases Working with complete bacterial genomes at TIGR 79

80 Nucleotide Databases Working with complete bacterial genomes at TIGR 80

81 Nucleotide Databases Working with complete bacterial genomes at TIGR 81
82 Nucleotide Databases Microbes from the environment at DoE The U.S. Department of Energy (DoE) is also a main player in microbial genomics. Its Joint Genome Institute specializes in the study of organisms that are either (a) important for preserving our environment, or (b) offering some new perspective in solving the incoming worldwide energy crisis (such as cheap ways of producing hydrogen). DoE home page: 82

83 Nucleotide Databases Microbes from the environment at DoE 83

84 Nucleotide Databases Microbes from the environment at DoE 84

85 Nucleotide Databases Microbes from the environment at DoE

86 Nucleotide Databases 86

87 Nucleotide Databases Microbes from the environment at DoE 87

88 Nucleotide Databases Microbes from the environment at DoE 88

89 Nucleotide Databases Microbes from the environment at DoE A live display of the microbe gene content in the range 1 to 500,
90 Nucleotide Databases Exploring the Human Genome Human Genome 3 billion nucleotides spread over 23 chromosomes. If you want to make sense of human data, you must have clear ideas on the current state of the data: The complete nucleotide sequence of the human genome is now at hand. This sequence was obtained in raw format; the next challenge is the annotation of the raw data, creating a detailed and accurate FEATURES table of the human genome. Throughout the world, new information is generated daily on human gene properties and functions, using a wide array of techniques. 90
91 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl Ensembl is a joint project between the European Bioinformatics Institute (EBI) and the Sanger Institute. Together they ve developed an integrated database and software system to produce and maintain automatic annotations for the genomes of animals with a special attention to our closest relatives: the vertebrates. Ensembl home page: 91

92 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl 92

93 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl 93

94 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl A schematic image of the various human chromosomes 94


95 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl the Chromosome 15 data subset 95

96 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl 96
97 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl GenBank Entry U90223 for human dutpase gene 97

98 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl 98

99 Nucleotide Databases Exploring the Human Genome : the Internet home page of Ensembl Human DUT ID card - everything you ever wanted to know about this gene can be found. 99

100 Tools for Nucleotide Sequences Establishing the G+C content of your sequence The GC content of a molecule of DNA is the percentage of the total nitrogenous base in the DNA that is either guanine or cytosine. GC content is a very interesting property of DNA sequences because it is correlated to repeats and gene deserts. DNA with high GC-content is more stable than DNA with low GC-content. In PCR experiments, the GC-content of primers are used to predict their annealing temperature to the template DNA. A higher GC-content level indicates a higher melting temperature. ORIGIN cagagaaaat caaaaagcag gccacgcagg accccgatat cgtcgcaggc gttgccgcac ttgccgccga aacaaataat gtggaagaat acgcccggca aaaacgtatc cgtaaaaacc ttgatctgat ctgcgcgaac gatgtttccc // 100

101 Tools for Nucleotide Sequences Establishing the G+C content of your sequence : Genomatix 101

102 Tools for Nucleotide Sequences Establishing the G+C content of your sequence : Genomatix 102

103 Tools for Nucleotide Sequences Establishing the G+C content of your sequence : Genomatix 103

104 Tools for Nucleotide Sequences Establishing the G+C content of your sequence : Genomatix 104

105 Tools for Nucleotide Sequences Establishing the G+C content of your sequence : Genomatix 105
106 Tools for Nucleotide Sequences Counting long words in DNA sequences : Wordcount 4 different nucleotides 16 different dinucleotides 64 different trinucleotides (3-tuples) 256 different 4-tuples 1024 different 5-tuples 4096 different 6-tuples (hexamer) Identifying hexamers (6-tuples) with unexpected high frequencies in a set of sequences (such as promoter regions) is often the starting point for discovering regulatory sequence motifs. The EMBOSS server (EBI), offers an online version of the program wordcount that allows you to compute the word frequency in your DNA sequence for any size

107 Tools for Nucleotide Sequences Counting long words in DNA sequences : : Wordcount 107

108 Tools for Nucleotide Sequences gongjing@sdu.edu.cn 108

109 Tools for Nucleotide Sequences 109
110 Tools for Nucleotide Sequences Finding Protein-Coding Regions Protein-coding genes have vastly different structures in microbes and multi cellular organisms. In microbes, each protein is encoded by a simple DNA segment, from start to end, called an open reading frame (ORF). In animal and plant genes, proteins are encoded in several pieces called exons, separated by non-coding DNA segments called introns. prokaryotes (archaea) eukaryotes 110

111 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI 111

112 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI 112

113 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI 113
114 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI 2 1 AE AE : Rickettsia conorii genome (bacterium) 114
115 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI 115
116 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI

117 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI or 117

118 Tools for Nucleotide Sequences Finding Protein-Coding Regions : ORF Finder at NCBI This program is also good for finding protein-coding regions for higher organisms, if your sequence is a cdna. cdna don t include introns and they have a simple, microbe-like ORF structure. 118
119 Tools for Nucleotide Sequences Finding Protein-Coding Regions : GeneMark The simplest ORF finding programs can probably correctly identify 85% percent of the protein-coding regions you may be interested in. However, in some cases, you may need to : Finding very short proteins Resolving uncertain cases where overlapping ORFs are predicted in different reading frames, on the direct and reverse strand, for instance Pinpoint the exact Start codon (the most distal ATG isn t always the correct one) GeneMark - searches for coding regions using a criterion that s a bit more sophisticated than it has to be an uninterrupted reading frame longer than a certain length. This program also takes into account the statistical properties of your sequence and associates some sort of a probabilistic quality index to each candidate s ORFs. 119

120 Tools for Nucleotide Sequences Finding Protein-Coding Regions : GeneMark 120

121 Tools for Nucleotide Sequences Finding Protein-Coding Regions : GeneMark 121
122 Tools for Nucleotide Sequences PDF 122

123 Tools for Nucleotide Sequences Finding Protein-Coding Regions : MZEF If you re looking at a human genomic sequence, your first question should be: Do I have a protein-coding exon somewhere in there? In eukaryotic DNA sequence, exons are separated by non-coding introns. According to what molecular biologists have worked out, a protein coding exon is an ORF flanked by two specific signals known as splice sites. Several programs exist that can recognize these exons. MZEF - developed by Dr. Michael Zhang at Cold Spring Harbor Lboratory on beautiful Long Island (USA)

124 Tools for Nucleotide Sequences Finding Protein-Coding Regions : MZEF 124
125 Tools for Nucleotide Sequences Finding Protein-Coding Regions : MZEF 125

126 Tools for Nucleotide Sequences Finding Protein-Coding Regions : MZEF 126

127 Tools for Nucleotide Sequences Finding Protein-Coding Regions : MZEF gongj@informatik.u 127
128 Tools for Nucleotide Sequences Finding Protein-Coding Regions : MZEF 128
129 Tools for Nucleotide Sequences Finding Protein-Coding Regions Beijing Gene Finder (BGF) - (eukaryotes) GeneFinder - GENEID - Genlang - GENSCAN - (eukaryotes) Glimmer - (prokarytoes, archaea) GlimmerM - (eukaryotes) GrailEXP
130 Tools for Nucleotide Sequences Information Page 130
131 Classification of Biological Databases Nucleotide Database Protein Database >2000 Primary Nucleotide Database Primary Protein Database Protein Sequence DB Protein Structure DB INSDC UniProt Secondary Nucleotide Database Secondary Protein Database Specific Database 131
132 Protein Databases Introduction to Bioinformatics Primary Protein Sequence Databases UniProt Knowledgebase (UniProtKB) is a central protein database of ExPASy maintained by Swiss Institute of Bioinformatics (SIB) and European Bioinformatics Institute (EBI), consisting of two sections: UniProtKB/Swiss-Prot - a reviewed, manually annotated, nonredundant protein sequence database. It combines information extracted from scientific literature and biocurator- evaluated computational analysis. UniProtKB/TrEMBL - contains high-quality computationally analyzed records, which are enriched with automatic annotation. It was introduced in response to increased dataflow resulting from genome projects, as the time- and labourconsuming manual annotation process of UniProtKB/Swiss-Prot could not be broadened to include all available protein sequences. 132

133 Protein Databases Introduction to Bioinformatics Primary Protein Sequence Databases The Protein Information Resource (PIR), is an integrated public bioinformatics resource to support genomic and proteomic research, and scientific studies. In 2002, PIR along with its international partners, EBI and SIB, were awarded a grant from NIH to create UniProt, a single worldwide database of protein sequence and function, by unifying the PIR-PSD, Swiss-Prot, and TrEMBL databases. 133
134 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry Proteins are much simpler objects than genes. Proteins correspond to relatively small sequences (350 amino acids long, on the average). Unlike genes, proteins have clear beginnings and clear ends. Proteins are defined on a single strand. Whatever modifications occur between the ORF sequence and the mature protein, the amino acids they contain remain in the same order. Use the human epidermal growth factor receptor (EGFR) as an example. UniprotKB/Swiss-Prot home page (ExPASy) : 134

135 Protein Databases Introduction to Bioinformatics P Reading a UniprotKB/Swiss-Prot Entry human epidermal growth factor receptor (EGFR)

136 Protein Databases Introduction to Bioinformatics P Reading a UniprotKB/Swiss-Prot Entry 136
137 Protein Databases Introduction to Bioinformatics P Reading a UniprotKB/Swiss-Prot Entry General Information Entry Name, Accession Number, Secondary Accession Number, Last Modification Date. 137
138 Protein Databases Introduction to Bioinformatics P Reading a UniprotKB/Swiss-Prot Entry The E.C. number ( ) encodes the biochemical reaction that this protein performs. E.C. stands for Enzyme Nomenclature Committee. It can provides you a complete understanding of this protein enzymatic function. 138

139 Protein Databases Introduction to Bioinformatics P Reading a UniprotKB/Swiss-Prot Entry 139

140 Protein Databases Introduction to Bioinformatics P Reading a UniprotKB/Swiss-Prot Entry 140
141 Protein Databases Introduction to Bioinformatics P Reading a UniprotKB/Swiss-Prot Entry This section provides a simple list of terms relevant to your current protein. Clicking any one of these keywords brings out a list of all Swiss-Prot entries that contain the same term. With the increasing size of the database, it seems that this type of query is not useful anymore. 141

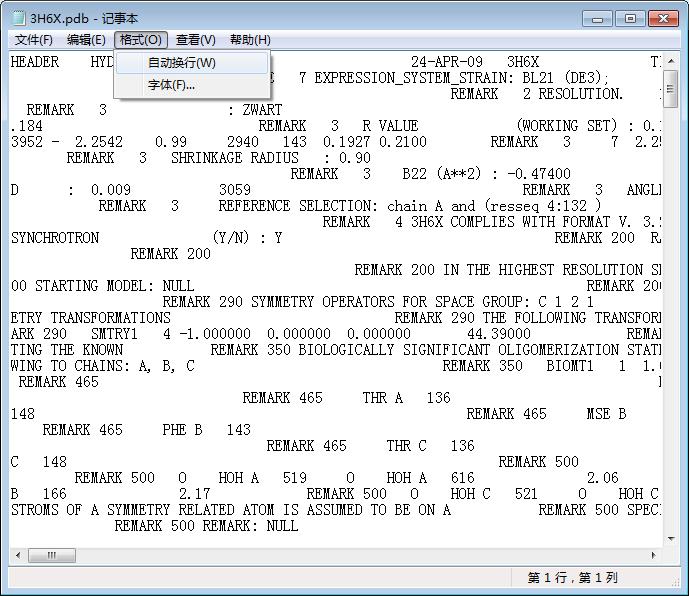
142 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry Other proteins it interacts with P
143 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P Description of the existence of related protein sequence(s) produced by alternative splicing of the same gene, alternative promoter usage, ribosomal frame-shifting or by the use of alternative initiation codons. 143
144 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P
145 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P or 145

146 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P or 146
147 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P
148 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P Only the entry, whose 3D structure was experimentally determined and submitted to the PDB, has this secondary structure annotation. (No computational result here!) 148
149 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P
150 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P The Cross-References section contains links to entries in other databases that contain some information about this protein. 150
151 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P Information Page 151
152 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P Each line begins with a two-character line code, which indicates the type of data contained in the line. 152
153 Protein Databases Introduction to Bioinformatics Reading a UniprotKB/Swiss-Prot Entry P Line code Content Occurrence in an entry Line code Content Occurrence in an entry ID AC DT DE GN OS OG OC Identification Accession number(s) Date Description Gene name(s) Organism species Organelle Organism classification Once; starts the entry Once or more Three times Once or more Optional Once or more Optional Once or more RG RA RT RL CC DR Reference group Reference authors Reference title Reference location Comments or notes Database crossreferences Once or more (Optional if RA line) Once or more (Optional if RG line) Optional Once or more Optional Optional OX Taxonomy cross-reference Once PE Protein existence Once OH Organism host Optional KW Keywords Optional RN Reference number Once or more FT Feature table data Once or more RP Reference position Once or more SQ Sequence header Once RC RX Reference comment(s) Reference cross-reference(s) Optional Optional blanks // Sequence data Termination line Once or more Once; ends the entry 153
. The data, typically obtained by X-ray crystallography or NMR spectroscopy and submitted by biologists and biochemists from around the world.")
154 Protein Databases Introduction to Bioinformatics Primary Protein Structure Databases The Protein Data Bank (PDB) is a repository for the 3D structural data of large biological molecules, such as proteins and nucleic acids (mainly proteins). The data, typically obtained by X-ray crystallography or NMR spectroscopy and submitted by biologists and biochemists from around the world. The structures in PDB are freely accessible on the Internet via the websites of its member organizations (PDBe, PDBj, and RCSB). The PDB is overseen by an organization called the Worldwide Protein Data Bank (wwpdb). Secondary Protein Structure Databases The Structural Classification of Proteins (SCOP) and CATH Protein Structure Classification (CATH) categorize structures according to type of structures stored in PDB and assumed their evolutionary relations. 154

155 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X 3H6X E coli dutpase protein 155

156 Protein Databases 3H6X 156


157 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X 记事本 157

158 158
159 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Title Section This section contains records used to describe the experiment and the biological macromolecules present in the entry. Keywords in this section include: HEADER, OBSLTE, TITLE, SPLIT, CAVEAT, COMPND, SOURCE, KEYWDS, EXPDTA, AUTHOR, REVDAT, SPRSDE, JRNL, REMARK. 159
160 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X HEADER identifies a PDB entry through the idcode field. This record also provides a classification for the entry. Finally, it contains the date when the coordinates were deposited to the PDB archive. 160
161 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X TITLE contains a title for the entry. It is also the title of the cited publication. 161
162 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X COMPND describes the macromolecular contents of an entry. 162
163 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X SOURCE specifies the biological and chemical source of each biological molecule in the entry. 163
164 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X KEYWDS contains a set of terms relevant to the entry, which can be used for keyword search across databases. 164
165 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X EXPDTA identifies the experimental technique used: X-RAY DIFFRACTION FIBER DIFFRACTION NEUTRON DIFFRACTION ELECTRON CRYSTALLOGRAPHY ELECTRON MICROSCOPY SOLID-STATE NMR SOLUTION NMR SOLUTION SCATTERING 165
166 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X AUTHOR contains the names of the people responsible for the contents of the entry. 166
167 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X REVDAT contains a history of the modifications made to an entry since its release. 167
168 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X JRNL contains the primary literature citation that describes the experiment which resulted in the deposited coordinate set. 168
169 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X REMARK presents experimental details, annotations, comments, and information not included in other records. 169
.")
170 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Primary Structure Section This section contains the sequence of residues in each chain of the macromolecule(s). DBREF, SEQADV, SEQRES, MODRES 170
171 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Heterogen Section This section contains the complete description of nonstandard residues in the entry. 171
172 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Secondary Structure Section This section describes helices, sheets, and turns found in protein and polypeptide structures. 172
173 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Connectivity Annotation Section This section specifies the existence and location of disulfide bonds and other linkages. 173

174 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Crystallographic and Coordinate Transformation Section This section describes the geometry of the crystallographic experiment and the coordinate system transformations. 174

175 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein Atom index 3H6X The most important part!!! X Y Z Coordinate Section This section contains the collection of atomic coordinates. Residue index 175

176 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Connectivity Section This section provides information on atomic connectivity. 176
177 Protein Databases Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Bookkeeping Section This section provides some final information about the file itself. A *.pdb file always ends with this END. 177




178 Protein Databases VMD Introduction to Bioinformatics Reading a PDB Entry: E. coli dutpase protein 3H6X Maestro 3H6X.pdb Pymol Chapter 4 Structure 178

179 Protein Databases Introduction to Bioinformatics Finding out more about your protein : RESID RESID, the post-translational modification database maintained by John Garavelli at the European Bioinformatics Institute (EBI). 179

180 Protein Databases Introduction to Bioinformatics Finding out more about your protein : RESID RESID, the post-translational modification database maintained by John Garavelli at the European Bioinformatics Institute (EBI). Myristoylation ( 豆蔻酰化 ) 180

181 Protein Databases Introduction to Bioinformatics Finding out more about your protein : RESID RESID, the post-translational modification database maintained by John Garavelli at the European Bioinformatics Institute (EBI). 181


182 Protein Databases Introduction to Bioinformatics Finding out more about your protein : RESID 182

183 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG KEGG - the Kyoto Encyclopedia of Genes and Genomes, was initiated by the Japanese human genome program in KEGG can be regarded as a "computer representation" of the biological system. Its collection includes genomes, enzymatic pathways, and biological chemicals. The PATHWAY database records networks of molecular interactions in the cells, and variants of them specific to particular organisms. Home page of KEGG : 183


184 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG 184
185 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG 185
186 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG 186

187 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG 187


188 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG Enzyme Pathway Compound 188
189 Protein Databases Enzyme relevant Pathways Compound 189

190 Protein Databases 190

191 Protein Databases 191

192 Protein Databases 192

193 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG 193
 - recognize pathogen-associated molecular patterns (PAMPs) on invading organisms but not on hosts and are the first")
194 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG Toll-like Receptor (TLR) - recognize pathogen-associated molecular patterns (PAMPs) on invading organisms but not on hosts and are the first line of defense in innate immunity. 194
195 Protein Databases Removing vector sequences 195

196 Protein Databases 196

197 Protein Databases 197


198 Protein Databases Introduction to Bioinformatics Finding out more about your protein : KEGG TLR4 LIPID of LPS MD2 Park et al

199 Protein Databases 199

200 Protein Databases autoimmunity caused by overactivity of TLRs : Systemic Lupus Erythematosus (SLE) 系统性红斑狼疮 Agonist Antagonist 200

201 Protein Databases Introduction to Bioinformatics Finding out more about your protein : ProtParam ProtParam - a program you can use online on the ExPASy server, is a convenient way to estimate every simple physico-chemical property, include the molecular weight, theoretical pi, amino acid composition, atomic composition, extinction coefficient, estimated half-life, instability index, aliphatic index and grand average of hydropathicity. 201

202 Protein Databases Introduction to Bioinformatics Finding out more about your protein : ProtParam 202

203 Protein Databases Introduction to Bioinformatics P Finding out more about your protein : ProtParam 203
204 Protein Databases Introduction to Bioinformatics Finding out more about your protein : ProtParam P
205 Protein Databases Introduction to Bioinformatics Finding out more about your protein : ProtParam P

206 Protein Databases Introduction to Bioinformatics Finding out more about your protein: WebLogo Sequence logos - are a graphical representation of an amino acid or nucleic acid multiple sequence alignment developed by Tom Schneider and Mike Stephens. Each logo consists of stacks of symbols, one stack for each position in the sequence. The overall height of the stack indicates the sequence conservation at that position, while the height of symbols within the stack indicates the relative frequency of each amino or nucleic acid at that position. In general, a sequence logo provides a richer and precise description of, for example, a binding site. 206

207 Protein Databases Introduction to Bioinformatics Finding out more about your protein: WebLogo WebLogo - is a web based application designed to make the generation of sequence logos easy and painless. WebLogo has featured in over 150 scientific publications
208 Protein Databases Introduction to Bioinformatics Finding out more about your protein: WebLogo promoter.seqs
209 Protein Databases Introduction to Bioinformatics Finding out more about your protein: WebLogo promoter.seqs 209
210 Protein Databases Introduction to Bioinformatics Finding out more about your protein: WebLogo promoter.seqs
. The TATA box has the core DNA sequence 5'-TATAAA-3' or a variant.")
211 Protein Databases Introduction to Bioinformatics Finding out more about your protein: WebLogo promoter.seqs In the promoter region of genes, we usually found a special fragment, called TATA box (also called Goldberg-Hogness box). The TATA box has the core DNA sequence 5'-TATAAA-3' or a variant. It is usually found as the binding site of RNA polymerase II. 211

212 Protein Databases Introduction to Bioinformatics Finding out more about your protein: MEME Sequence Motif - a nucleotide or amino-acid sequence pattern that is widespread and has, or is conjectured to have, a biological significance. An example is the N-glycosylation site motif: Asn, followed by anything but Pro, followed by either Ser or Thr, followed by anything but Pro This pattern can be written as N{P}[ST]{P}(Regular expression), where N=Asn, P=Pro, S=Ser, T=Thr; {X} means any amino acid except X; and [XY] means either X or Y. The notation [XY] does not give any indication of the probability of X or Y occurring in the pattern. Observed probabilities can be graphically represented using sequence logos. 212
213 Protein Databases Introduction to Bioinformatics Finding out more about your protein: MEME The MEME Suite - Motif-based sequence analysis tools. The MEME Suite allows you to: discover motifs on groups of related DNA or protein sequences, search sequence databases using motifs, compare a motif to all motifs in a database of motifs. Home page : 213

214 Protein Databases Introduction to Bioinformatics Finding out more about your protein: MEME 214

215 Protein Databases Introduction to Bioinformatics meme.seqs Finding out more about your protein: MEME 215

216 Protein Databases Introduction to Bioinformatics meme.seqs Finding out more about your protein: MEME 216

217 Protein Databases Introduction to Bioinformatics meme.seqs Finding out more about your protein: MEME 217
218 Protein Databases Introduction to Bioinformatics meme.seqs Finding out more about your protein: MEME 218

219 Protein Databases meme.seqs 219
220 Protein Databases Introduction to Bioinformatics Finding out more about your protein The Nuclear Protein Database (NPD) - a searchable database of information on proteins that are localized to the nucleus of vertebrate cells. SignalP 3.0 server - predicts the presence and location of signal peptide cleavage sites in amino acid sequences from different organisms. Phospho.ELM - a database of S/T/Y phosphorylation sites. SYSTERS - protein family database of large-scale protein clustering based on sequence similarity More tools and databases, please see Information Page 220

221 221
Two Mark question and Answers
 1. Define Bioinformatics Two Mark question and Answers Bioinformatics is the field of science in which biology, computer science, and information technology merge into a single discipline. There are three
1. Define Bioinformatics Two Mark question and Answers Bioinformatics is the field of science in which biology, computer science, and information technology merge into a single discipline. There are three
Biological databases an introduction
 Biological databases an introduction By Dr. Erik Bongcam-Rudloff SLU 2017 Biological Databases Sequence Databases Genome Databases Structure Databases Sequence Databases The sequence databases are the
Biological databases an introduction By Dr. Erik Bongcam-Rudloff SLU 2017 Biological Databases Sequence Databases Genome Databases Structure Databases Sequence Databases The sequence databases are the
Gene Identification in silico
 Gene Identification in silico Nita Parekh, IIIT Hyderabad Presented at National Seminar on Bioinformatics and Functional Genomics, at Bioinformatics centre, Pondicherry University, Feb 15 17, 2006. Introduction
Gene Identification in silico Nita Parekh, IIIT Hyderabad Presented at National Seminar on Bioinformatics and Functional Genomics, at Bioinformatics centre, Pondicherry University, Feb 15 17, 2006. Introduction
I nternet Resources for Bioinformatics Data and Tools
 ~i;;;;;;;'s :.. ~,;;%.: ;!,;s163 ~. s :s163:: ~s ;'.:'. 3;3 ~,: S;I:;~.3;3'/////, IS~I'//. i: ~s '/, Z I;~;I; :;;; :;I~Z;I~,;'//.;;;;;I'/,;:, :;:;/,;'L;;;~;'~;~,::,:, Z'LZ:..;;',;';4...;,;',~/,~:...;/,;:'.::.
~i;;;;;;;'s :.. ~,;;%.: ;!,;s163 ~. s :s163:: ~s ;'.:'. 3;3 ~,: S;I:;~.3;3'/////, IS~I'//. i: ~s '/, Z I;~;I; :;;; :;I~Z;I~,;'//.;;;;;I'/,;:, :;:;/,;'L;;;~;'~;~,::,:, Z'LZ:..;;',;';4...;,;',~/,~:...;/,;:'.::.
COMPUTER RESOURCES II:
 COMPUTER RESOURCES II: Using the computer to analyze data, using the internet, and accessing online databases Bio 210, Fall 2006 Linda S. Huang, Ph.D. University of Massachusetts Boston In the first computer
COMPUTER RESOURCES II: Using the computer to analyze data, using the internet, and accessing online databases Bio 210, Fall 2006 Linda S. Huang, Ph.D. University of Massachusetts Boston In the first computer
Protein Bioinformatics Part I: Access to information
 Protein Bioinformatics Part I: Access to information 260.655 April 6, 2006 Jonathan Pevsner, Ph.D. pevsner@kennedykrieger.org Outline [1] Proteins at NCBI RefSeq accession numbers Cn3D to visualize structures
Protein Bioinformatics Part I: Access to information 260.655 April 6, 2006 Jonathan Pevsner, Ph.D. pevsner@kennedykrieger.org Outline [1] Proteins at NCBI RefSeq accession numbers Cn3D to visualize structures
Computational gene finding
 Computational gene finding Devika Subramanian Comp 470 Outline (3 lectures) Lec 1 Lec 2 Lec 3 The biological context Markov models and Hidden Markov models Ab-initio methods for gene finding Comparative
Computational gene finding Devika Subramanian Comp 470 Outline (3 lectures) Lec 1 Lec 2 Lec 3 The biological context Markov models and Hidden Markov models Ab-initio methods for gene finding Comparative
Genome Resources. Genome Resources. Maj Gen (R) Suhaib Ahmed, HI (M)
 Suhaib Ahmed, HI (M)") Maj Gen (R) Suhaib Ahmed, I (M) The human genome comprises DNA sequences mostly contained in the nucleus. A small portion is also present in the mitochondria. The nuclear DNA is present in chromosomes.
Maj Gen (R) Suhaib Ahmed, I (M) The human genome comprises DNA sequences mostly contained in the nucleus. A small portion is also present in the mitochondria. The nuclear DNA is present in chromosomes.
EECS 730 Introduction to Bioinformatics Sequence Alignment. Luke Huan Electrical Engineering and Computer Science
 EECS 730 Introduction to Bioinformatics Sequence Alignment Luke Huan Electrical Engineering and Computer Science http://people.eecs.ku.edu/~jhuan/ Database What is database An organized set of data Can
EECS 730 Introduction to Bioinformatics Sequence Alignment Luke Huan Electrical Engineering and Computer Science http://people.eecs.ku.edu/~jhuan/ Database What is database An organized set of data Can
BIO303, Genetics Study Guide II for Spring 2007 Semester
 BIO303, Genetics Study Guide II for Spring 2007 Semester 1 Questions from F05 1. Tryptophan (Trp) is encoded by the codon UGG. Suppose that a cell was treated with high levels of 5- Bromouracil such that
BIO303, Genetics Study Guide II for Spring 2007 Semester 1 Questions from F05 1. Tryptophan (Trp) is encoded by the codon UGG. Suppose that a cell was treated with high levels of 5- Bromouracil such that
Prokaryotic Transcription
 Prokaryotic Transcription Transcription Basics DNA is the genetic material Nucleic acid Capable of self-replication and synthesis of RNA RNA is the middle man Nucleic acid Structure and base sequence are
Prokaryotic Transcription Transcription Basics DNA is the genetic material Nucleic acid Capable of self-replication and synthesis of RNA RNA is the middle man Nucleic acid Structure and base sequence are
Computational gene finding. Devika Subramanian Comp 470
 Computational gene finding Devika Subramanian Comp 470 Outline (3 lectures) The biological context Lec 1 Lec 2 Lec 3 Markov models and Hidden Markov models Ab-initio methods for gene finding Comparative
Computational gene finding Devika Subramanian Comp 470 Outline (3 lectures) The biological context Lec 1 Lec 2 Lec 3 Markov models and Hidden Markov models Ab-initio methods for gene finding Comparative
DNA and Biotechnology Form of DNA Form of DNA Form of DNA Form of DNA Replication of DNA Replication of DNA
 21 DNA and Biotechnology DNA and Biotechnology OUTLINE: Replication of DNA Gene Expression Mutations Regulating Gene Activity Genetic Engineering Genomics DNA (deoxyribonucleic acid) Double-stranded molecule
21 DNA and Biotechnology DNA and Biotechnology OUTLINE: Replication of DNA Gene Expression Mutations Regulating Gene Activity Genetic Engineering Genomics DNA (deoxyribonucleic acid) Double-stranded molecule
Lesson Overview. Fermentation 13.1 RNA
 13.1 RNA The Role of RNA Genes contain coded DNA instructions that tell cells how to build proteins. The first step in decoding these genetic instructions is to copy part of the base sequence from DNA
13.1 RNA The Role of RNA Genes contain coded DNA instructions that tell cells how to build proteins. The first step in decoding these genetic instructions is to copy part of the base sequence from DNA
Videos. Lesson Overview. Fermentation
 Lesson Overview Fermentation Videos Bozeman Transcription and Translation: https://youtu.be/h3b9arupxzg Drawing transcription and translation: https://youtu.be/6yqplgnjr4q Objectives 29a) I can contrast
Lesson Overview Fermentation Videos Bozeman Transcription and Translation: https://youtu.be/h3b9arupxzg Drawing transcription and translation: https://youtu.be/6yqplgnjr4q Objectives 29a) I can contrast
Chapter 12 Packet DNA 1. What did Griffith conclude from his experiment? 2. Describe the process of transformation.
 Chapter 12 Packet DNA and RNA Name Period California State Standards covered by this chapter: Cell Biology 1. The fundamental life processes of plants and animals depend on a variety of chemical reactions
Chapter 12 Packet DNA and RNA Name Period California State Standards covered by this chapter: Cell Biology 1. The fundamental life processes of plants and animals depend on a variety of chemical reactions
MODULE 5: TRANSLATION
 MODULE 5: TRANSLATION Lesson Plan: CARINA ENDRES HOWELL, LEOCADIA PALIULIS Title Translation Objectives Determine the codons for specific amino acids and identify reading frames by looking at the Base
MODULE 5: TRANSLATION Lesson Plan: CARINA ENDRES HOWELL, LEOCADIA PALIULIS Title Translation Objectives Determine the codons for specific amino acids and identify reading frames by looking at the Base
Computational gene finding
 Computational gene finding Devika Subramanian Comp 470 Outline (3 lectures) Lec 1 Lec 2 Lec 3 The biological context Markov models and Hidden Markov models Ab-initio methods for gene finding Comparative
Computational gene finding Devika Subramanian Comp 470 Outline (3 lectures) Lec 1 Lec 2 Lec 3 The biological context Markov models and Hidden Markov models Ab-initio methods for gene finding Comparative
Multiple choice questions (numbers in brackets indicate the number of correct answers)
") 1 Multiple choice questions (numbers in brackets indicate the number of correct answers) February 1, 2013 1. Ribose is found in Nucleic acids Proteins Lipids RNA DNA (2) 2. Most RNA in cells is transfer
1 Multiple choice questions (numbers in brackets indicate the number of correct answers) February 1, 2013 1. Ribose is found in Nucleic acids Proteins Lipids RNA DNA (2) 2. Most RNA in cells is transfer
Genome annotation & EST
 Genome annotation & EST What is genome annotation? The process of taking the raw DNA sequence produced by the genome sequence projects and adding the layers of analysis and interpretation necessary
Genome annotation & EST What is genome annotation? The process of taking the raw DNA sequence produced by the genome sequence projects and adding the layers of analysis and interpretation necessary
Biology A: Chapter 9 Annotating Notes Protein Synthesis
 Name: Pd: Biology A: Chapter 9 Annotating Notes Protein Synthesis -As you read your textbook, please fill out these notes. -Read each paragraph state the big/main idea on the left side. -On the right side
Name: Pd: Biology A: Chapter 9 Annotating Notes Protein Synthesis -As you read your textbook, please fill out these notes. -Read each paragraph state the big/main idea on the left side. -On the right side
PROTEIN SYNTHESIS Flow of Genetic Information The flow of genetic information can be symbolized as: DNA RNA Protein
 PROTEIN SYNTHESIS Flow of Genetic Information The flow of genetic information can be symbolized as: DNA RNA Protein This is also known as: The central dogma of molecular biology Protein Proteins are made
PROTEIN SYNTHESIS Flow of Genetic Information The flow of genetic information can be symbolized as: DNA RNA Protein This is also known as: The central dogma of molecular biology Protein Proteins are made
Unit 1: DNA and the Genome. Sub-Topic (1.3) Gene Expression
 Gene Expression") Unit 1: DNA and the Genome Sub-Topic (1.3) Gene Expression Unit 1: DNA and the Genome Sub-Topic (1.3) Gene Expression On completion of this subtopic I will be able to State the meanings of the terms genotype,
Unit 1: DNA and the Genome Sub-Topic (1.3) Gene Expression Unit 1: DNA and the Genome Sub-Topic (1.3) Gene Expression On completion of this subtopic I will be able to State the meanings of the terms genotype,
MBioS 503: Section 1 Chromosome, Gene, Translation, & Transcription. Gene Organization. Genome. Objectives: Gene Organization
 Overview & Recap of Molecular Biology before the last two sections MBioS 503: Section 1 Chromosome, Gene, Translation, & Transcription Gene Organization Joy Winuthayanon, PhD School of Molecular Biosciences
Overview & Recap of Molecular Biology before the last two sections MBioS 503: Section 1 Chromosome, Gene, Translation, & Transcription Gene Organization Joy Winuthayanon, PhD School of Molecular Biosciences
Gene Expression: Transcription, Translation, RNAs and the Genetic Code
 Lecture 28-29 Gene Expression: Transcription, Translation, RNAs and the Genetic Code Central dogma of molecular biology During transcription, the information in a DNA sequence (a gene) is copied into a
Lecture 28-29 Gene Expression: Transcription, Translation, RNAs and the Genetic Code Central dogma of molecular biology During transcription, the information in a DNA sequence (a gene) is copied into a
Big Idea 3C Basic Review
 Big Idea 3C Basic Review 1. A gene is a. A sequence of DNA that codes for a protein. b. A sequence of amino acids that codes for a protein. c. A sequence of codons that code for nucleic acids. d. The end
Big Idea 3C Basic Review 1. A gene is a. A sequence of DNA that codes for a protein. b. A sequence of amino acids that codes for a protein. c. A sequence of codons that code for nucleic acids. d. The end
Find this material useful? You can help our team to keep this site up and bring you even more content consider donating via the link on our site.
 Find this material useful? You can help our team to keep this site up and bring you even more content consider donating via the link on our site. Still having trouble understanding the material? Check
Find this material useful? You can help our team to keep this site up and bring you even more content consider donating via the link on our site. Still having trouble understanding the material? Check
Bio 101 Sample questions: Chapter 10
 Bio 101 Sample questions: Chapter 10 1. Which of the following is NOT needed for DNA replication? A. nucleotides B. ribosomes C. Enzymes (like polymerases) D. DNA E. all of the above are needed 2 The information
Bio 101 Sample questions: Chapter 10 1. Which of the following is NOT needed for DNA replication? A. nucleotides B. ribosomes C. Enzymes (like polymerases) D. DNA E. all of the above are needed 2 The information
Fermentation. Lesson Overview. Lesson Overview 13.1 RNA
 13.1 RNA THINK ABOUT IT DNA is the genetic material of cells. The sequence of nucleotide bases in the strands of DNA carries some sort of code. In order for that code to work, the cell must be able to
13.1 RNA THINK ABOUT IT DNA is the genetic material of cells. The sequence of nucleotide bases in the strands of DNA carries some sort of code. In order for that code to work, the cell must be able to
Themes: RNA and RNA Processing. Messenger RNA (mrna) What is a gene? RNA is very versatile! RNA-RNA interactions are very important!
 What is a gene? RNA is very versatile! RNA-RNA interactions are very important!") Themes: RNA is very versatile! RNA and RNA Processing Chapter 14 RNA-RNA interactions are very important! Prokaryotes and Eukaryotes have many important differences. Messenger RNA (mrna) Carries genetic
Themes: RNA is very versatile! RNA and RNA Processing Chapter 14 RNA-RNA interactions are very important! Prokaryotes and Eukaryotes have many important differences. Messenger RNA (mrna) Carries genetic
Lecture 7 Motif Databases and Gene Finding
 Introduction to Bioinformatics for Medical Research Gideon Greenspan gdg@cs.technion.ac.il Lecture 7 Motif Databases and Gene Finding Motif Databases & Gene Finding Motifs Recap Motif Databases TRANSFAC
Introduction to Bioinformatics for Medical Research Gideon Greenspan gdg@cs.technion.ac.il Lecture 7 Motif Databases and Gene Finding Motif Databases & Gene Finding Motifs Recap Motif Databases TRANSFAC
Biology. Biology. Slide 1 of 39. End Show. Copyright Pearson Prentice Hall
 Biology Biology 1 of 39 12-3 RNA and Protein Synthesis 2 of 39 Essential Question What is transcription and translation and how do they take place? 3 of 39 12 3 RNA and Protein Synthesis Genes are coded
Biology Biology 1 of 39 12-3 RNA and Protein Synthesis 2 of 39 Essential Question What is transcription and translation and how do they take place? 3 of 39 12 3 RNA and Protein Synthesis Genes are coded
Biology. Biology. Slide 1 of 39. End Show. Copyright Pearson Prentice Hall
 Biology Biology 1 of 39 12-3 RNA and Protein Synthesis 2 of 39 12 3 RNA and Protein Synthesis Genes are coded DNA instructions that control the production of proteins. Genetic messages can be decoded by
Biology Biology 1 of 39 12-3 RNA and Protein Synthesis 2 of 39 12 3 RNA and Protein Synthesis Genes are coded DNA instructions that control the production of proteins. Genetic messages can be decoded by
The Nature of Genes. The Nature of Genes. Genes and How They Work. Chapter 15/16
 Genes and How They Work Chapter 15/16 The Nature of Genes Beadle and Tatum proposed the one gene one enzyme hypothesis. Today we know this as the one gene one polypeptide hypothesis. 2 The Nature of Genes
Genes and How They Work Chapter 15/16 The Nature of Genes Beadle and Tatum proposed the one gene one enzyme hypothesis. Today we know this as the one gene one polypeptide hypothesis. 2 The Nature of Genes
Introduction to Cellular Biology and Bioinformatics. Farzaneh Salari
 Introduction to Cellular Biology and Bioinformatics Farzaneh Salari Outline Bioinformatics Cellular Biology A Bioinformatics Problem What is bioinformatics? Computer Science Statistics Bioinformatics Mathematics...
Introduction to Cellular Biology and Bioinformatics Farzaneh Salari Outline Bioinformatics Cellular Biology A Bioinformatics Problem What is bioinformatics? Computer Science Statistics Bioinformatics Mathematics...
Web-based Bioinformatics Applications in Proteomics
 Web-based Bioinformatics Applications in Proteomics Chiquito Crasto ccrasto@genetics.uab.edu January 30, 2009 NCBI (National Center for Biotechnology Information) http://www.ncbi.nlm.nih.gov/ 1 Pubmed
Web-based Bioinformatics Applications in Proteomics Chiquito Crasto ccrasto@genetics.uab.edu January 30, 2009 NCBI (National Center for Biotechnology Information) http://www.ncbi.nlm.nih.gov/ 1 Pubmed
I. Gene Expression Figure 1: Central Dogma of Molecular Biology
 I. Gene Expression Figure 1: Central Dogma of Molecular Biology Central Dogma: Gene Expression: RNA Structure RNA nucleotides contain the pentose sugar Ribose instead of deoxyribose. Contain the bases
I. Gene Expression Figure 1: Central Dogma of Molecular Biology Central Dogma: Gene Expression: RNA Structure RNA nucleotides contain the pentose sugar Ribose instead of deoxyribose. Contain the bases
Videos. Bozeman Transcription and Translation: Drawing transcription and translation:
 Videos Bozeman Transcription and Translation: https://youtu.be/h3b9arupxzg Drawing transcription and translation: https://youtu.be/6yqplgnjr4q Objectives 29a) I can contrast RNA and DNA. 29b) I can explain
Videos Bozeman Transcription and Translation: https://youtu.be/h3b9arupxzg Drawing transcription and translation: https://youtu.be/6yqplgnjr4q Objectives 29a) I can contrast RNA and DNA. 29b) I can explain
Genetics Lecture 21 Recombinant DNA
 Genetics Lecture 21 Recombinant DNA Recombinant DNA In 1971, a paper published by Kathleen Danna and Daniel Nathans marked the beginning of the recombinant DNA era. The paper described the isolation of
Genetics Lecture 21 Recombinant DNA Recombinant DNA In 1971, a paper published by Kathleen Danna and Daniel Nathans marked the beginning of the recombinant DNA era. The paper described the isolation of
Genes and How They Work. Chapter 15
 Genes and How They Work Chapter 15 The Nature of Genes They proposed the one gene one enzyme hypothesis. Today we know this as the one gene one polypeptide hypothesis. 2 The Nature of Genes The central
Genes and How They Work Chapter 15 The Nature of Genes They proposed the one gene one enzyme hypothesis. Today we know this as the one gene one polypeptide hypothesis. 2 The Nature of Genes The central
Studying the Human Genome. Lesson Overview. Lesson Overview Studying the Human Genome
 Lesson Overview 14.3 Studying the Human Genome THINK ABOUT IT Just a few decades ago, computers were gigantic machines found only in laboratories and universities. Today, many of us carry small, powerful
Lesson Overview 14.3 Studying the Human Genome THINK ABOUT IT Just a few decades ago, computers were gigantic machines found only in laboratories and universities. Today, many of us carry small, powerful
Tutorial for Stop codon reassignment in the wild
 Tutorial for Stop codon reassignment in the wild Learning Objectives This tutorial has two learning objectives: 1. Finding evidence of stop codon reassignment on DNA fragments. 2. Detecting and confirming
Tutorial for Stop codon reassignment in the wild Learning Objectives This tutorial has two learning objectives: 1. Finding evidence of stop codon reassignment on DNA fragments. 2. Detecting and confirming
Nucleic Acids: DNA and RNA
 Nucleic Acids: DNA and RNA Living organisms are complex systems. Hundreds of thousands of proteins exist inside each one of us to help carry out our daily functions. These proteins are produced locally,
Nucleic Acids: DNA and RNA Living organisms are complex systems. Hundreds of thousands of proteins exist inside each one of us to help carry out our daily functions. These proteins are produced locally,
Exam 2 Key - Spring 2008 A#: Please see us if you have any questions!
 Page 1 of 5 Exam 2 Key - Spring 2008 A#: Please see us if you have any questions! 1. A mutation in which parts of two nonhomologous chromosomes change places is called a(n) A. translocation. B. transition.
Page 1 of 5 Exam 2 Key - Spring 2008 A#: Please see us if you have any questions! 1. A mutation in which parts of two nonhomologous chromosomes change places is called a(n) A. translocation. B. transition.
Chapter 12: Molecular Biology of the Gene
 Biology Textbook Notes Chapter 12: Molecular Biology of the Gene p. 214-219 The Genetic Material (12.1) - Genetic Material must: 1. Be able to store information that pertains to the development, structure,
Biology Textbook Notes Chapter 12: Molecular Biology of the Gene p. 214-219 The Genetic Material (12.1) - Genetic Material must: 1. Be able to store information that pertains to the development, structure,
Transcription. The sugar molecule found in RNA is ribose, rather than the deoxyribose found in DNA.
 Transcription RNA (ribonucleic acid) is a key intermediary between a DNA sequence and a polypeptide. RNA is an informational polynucleotide similar to DNA, but it differs from DNA in three ways: RNA generally
Transcription RNA (ribonucleic acid) is a key intermediary between a DNA sequence and a polypeptide. RNA is an informational polynucleotide similar to DNA, but it differs from DNA in three ways: RNA generally
Molecular Cell Biology - Problem Drill 08: Transcription, Translation and the Genetic Code
 Molecular Cell Biology - Problem Drill 08: Transcription, Translation and the Genetic Code Question No. 1 of 10 1. Which of the following statements about how genes function is correct? Question #1 (A)
Molecular Cell Biology - Problem Drill 08: Transcription, Translation and the Genetic Code Question No. 1 of 10 1. Which of the following statements about how genes function is correct? Question #1 (A)
Lesson Overview. Studying the Human Genome. Lesson Overview Studying the Human Genome
 Lesson Overview 14.3 Studying the Human Genome THINK ABOUT IT Just a few decades ago, computers were gigantic machines found only in laboratories and universities. Today, many of us carry small, powerful
Lesson Overview 14.3 Studying the Human Genome THINK ABOUT IT Just a few decades ago, computers were gigantic machines found only in laboratories and universities. Today, many of us carry small, powerful
DNA and RNA. Chapter 12
 DNA and RNA Chapter 12 History of DNA Late 1800 s scientists discovered that DNA is in the nucleus of the cell 1902 Walter Sutton proposed that hereditary material resided in the chromosomes in the nucleus
DNA and RNA Chapter 12 History of DNA Late 1800 s scientists discovered that DNA is in the nucleus of the cell 1902 Walter Sutton proposed that hereditary material resided in the chromosomes in the nucleus
DNA REPLICATION & BIOTECHNOLOGY Biology Study Review
 DNA REPLICATION & BIOTECHNOLOGY Biology Study Review DNA DNA is found in, in the nucleus. It controls cellular activity by regulating the production of, which includes It is a very long molecule made up
DNA REPLICATION & BIOTECHNOLOGY Biology Study Review DNA DNA is found in, in the nucleus. It controls cellular activity by regulating the production of, which includes It is a very long molecule made up
Resources. How to Use This Presentation. Chapter 10. Objectives. Table of Contents. Griffith s Discovery of Transformation. Griffith s Experiments
 How to Use This Presentation To View the presentation as a slideshow with effects select View on the menu bar and click on Slide Show. To advance through the presentation, click the right-arrow key or
How to Use This Presentation To View the presentation as a slideshow with effects select View on the menu bar and click on Slide Show. To advance through the presentation, click the right-arrow key or
Introduction and Public Sequence Databases. BME 110/BIOL 181 CompBio Tools
 Introduction and Public Sequence Databases BME 110/BIOL 181 CompBio Tools Todd Lowe March 29, 2011 Course Syllabus: Admin http://www.soe.ucsc.edu/classes/bme110/spring11 Reading: Chapters 1, 2 (pp.29-56),
Introduction and Public Sequence Databases BME 110/BIOL 181 CompBio Tools Todd Lowe March 29, 2011 Course Syllabus: Admin http://www.soe.ucsc.edu/classes/bme110/spring11 Reading: Chapters 1, 2 (pp.29-56),
Winter Quarter Midterm Exam
 1. For a science fair project, two students decided to repeat the Hershey and Chase experiment, with modifications. They decided to label the nitrogen of the DNA, rather than the phosphate. They reasoned
1. For a science fair project, two students decided to repeat the Hershey and Chase experiment, with modifications. They decided to label the nitrogen of the DNA, rather than the phosphate. They reasoned
DNA. translation. base pairing rules for DNA Replication. thymine. cytosine. amino acids. The building blocks of proteins are?
 2 strands, has the 5-carbon sugar deoxyribose, and has the nitrogen base Thymine. The actual process of assembling the proteins on the ribosome is called? DNA translation Adenine pairs with Thymine, Thymine
2 strands, has the 5-carbon sugar deoxyribose, and has the nitrogen base Thymine. The actual process of assembling the proteins on the ribosome is called? DNA translation Adenine pairs with Thymine, Thymine
Genomes DNA Genes to Proteins. The human genome is a multi-volume instruction manual
 Dr. Kathleen Hill Assistant Professor Department of Biology The University of Western Ontario khill22@uwo.ca Office Hours: Monday 1 to 5pm Room 333 Western Science Centre Research Website: http://www.uwo.ca/biology/faculty/hill/index.htm
Dr. Kathleen Hill Assistant Professor Department of Biology The University of Western Ontario khill22@uwo.ca Office Hours: Monday 1 to 5pm Room 333 Western Science Centre Research Website: http://www.uwo.ca/biology/faculty/hill/index.htm
Chapter 4 DNA Structure & Gene Expression
 Biology 12 Name: Cell Biology Per: Date: Chapter 4 DNA Structure & Gene Expression Complete using BC Biology 12, pages 108-153 4.1 DNA Structure pages 112-114 1. DNA stands for and is the genetic material
Biology 12 Name: Cell Biology Per: Date: Chapter 4 DNA Structure & Gene Expression Complete using BC Biology 12, pages 108-153 4.1 DNA Structure pages 112-114 1. DNA stands for and is the genetic material
Section 10.3 Outline 10.3 How Is the Base Sequence of a Messenger RNA Molecule Translated into Protein?
 Section 10.3 Outline 10.3 How Is the Base Sequence of a Messenger RNA Molecule Translated into Protein? Messenger RNA Carries Information for Protein Synthesis from the DNA to Ribosomes Ribosomes Consist
Section 10.3 Outline 10.3 How Is the Base Sequence of a Messenger RNA Molecule Translated into Protein? Messenger RNA Carries Information for Protein Synthesis from the DNA to Ribosomes Ribosomes Consist
Key Area 1.3: Gene Expression
 Key Area 1.3: Gene Expression RNA There is a second type of nucleic acid in the cell, called RNA. RNA plays a vital role in the production of protein from the code in the DNA. What is gene expression?
Key Area 1.3: Gene Expression RNA There is a second type of nucleic acid in the cell, called RNA. RNA plays a vital role in the production of protein from the code in the DNA. What is gene expression?
The Structure of Proteins The Structure of Proteins. How Proteins are Made: Genetic Transcription, Translation, and Regulation
 How Proteins are Made: Genetic, Translation, and Regulation PLAY The Structure of Proteins 14.1 The Structure of Proteins Proteins - polymer amino acids - monomers Linked together with peptide bonds A
How Proteins are Made: Genetic, Translation, and Regulation PLAY The Structure of Proteins 14.1 The Structure of Proteins Proteins - polymer amino acids - monomers Linked together with peptide bonds A
Bioinformatics Prof. M. Michael Gromiha Department of Biotechnology Indian Institute of Technology, Madras. Lecture - 5a Protein sequence databases
 Bioinformatics Prof. M. Michael Gromiha Department of Biotechnology Indian Institute of Technology, Madras Lecture - 5a Protein sequence databases In this lecture, we will mainly discuss on Protein Sequence
Bioinformatics Prof. M. Michael Gromiha Department of Biotechnology Indian Institute of Technology, Madras Lecture - 5a Protein sequence databases In this lecture, we will mainly discuss on Protein Sequence
CHAPTER 20 DNA TECHNOLOGY AND GENOMICS. Section A: DNA Cloning
 Section A: DNA Cloning 1. DNA technology makes it possible to clone genes for basic research and commercial applications: an overview 2. Restriction enzymes are used to make recombinant DNA 3. Genes can
Section A: DNA Cloning 1. DNA technology makes it possible to clone genes for basic research and commercial applications: an overview 2. Restriction enzymes are used to make recombinant DNA 3. Genes can
Chapter 13. From DNA to Protein
 Chapter 13 From DNA to Protein Proteins All proteins consist of polypeptide chains A linear sequence of amino acids Each chain corresponds to the nucleotide base sequenceof a gene The Path From Genes to
Chapter 13 From DNA to Protein Proteins All proteins consist of polypeptide chains A linear sequence of amino acids Each chain corresponds to the nucleotide base sequenceof a gene The Path From Genes to
Fig Ch 17: From Gene to Protein
 Fig. 17-1 Ch 17: From Gene to Protein Basic Principles of Transcription and Translation RNA is the intermediate between genes and the proteins for which they code Transcription is the synthesis of RNA
Fig. 17-1 Ch 17: From Gene to Protein Basic Principles of Transcription and Translation RNA is the intermediate between genes and the proteins for which they code Transcription is the synthesis of RNA
Sequence Databases and database scanning
 Sequence Databases and database scanning Marjolein Thunnissen Lund, 2012 Types of databases: Primary sequence databases (proteins and nucleic acids). Composite protein sequence databases. Secondary databases.
Sequence Databases and database scanning Marjolein Thunnissen Lund, 2012 Types of databases: Primary sequence databases (proteins and nucleic acids). Composite protein sequence databases. Secondary databases.
CHAPTER 21 LECTURE SLIDES
 CHAPTER 21 LECTURE SLIDES Prepared by Brenda Leady University of Toledo To run the animations you must be in Slideshow View. Use the buttons on the animation to play, pause, and turn audio/text on or off.
CHAPTER 21 LECTURE SLIDES Prepared by Brenda Leady University of Toledo To run the animations you must be in Slideshow View. Use the buttons on the animation to play, pause, and turn audio/text on or off.
Regulation of bacterial gene expression
 Regulation of bacterial gene expression Gene Expression Gene Expression: RNA and protein synthesis DNA ----------> RNA ----------> Protein transcription translation! DNA replication only occurs in cells
Regulation of bacterial gene expression Gene Expression Gene Expression: RNA and protein synthesis DNA ----------> RNA ----------> Protein transcription translation! DNA replication only occurs in cells
Chapter 12. DNA TRANSCRIPTION and TRANSLATION
 Chapter 12 DNA TRANSCRIPTION and TRANSLATION 12-3 RNA and Protein Synthesis WARM UP What are proteins? Where do they come from? From DNA to RNA to Protein DNA in our cells carry the instructions for making
Chapter 12 DNA TRANSCRIPTION and TRANSLATION 12-3 RNA and Protein Synthesis WARM UP What are proteins? Where do they come from? From DNA to RNA to Protein DNA in our cells carry the instructions for making
The gene. Fig. 1. The general structure of gene
 The gene is the basic unit of heredity and carries the genetic information for a given protein and/or RNA molecule. In biochemical terms a gene represents a fragment of deoxyribonucleic acid (DNA), which
The gene is the basic unit of heredity and carries the genetic information for a given protein and/or RNA molecule. In biochemical terms a gene represents a fragment of deoxyribonucleic acid (DNA), which
Bioinformatics Tools. Stuart M. Brown, Ph.D Dept of Cell Biology NYU School of Medicine
 Bioinformatics Tools Stuart M. Brown, Ph.D Dept of Cell Biology NYU School of Medicine Bioinformatics Tools Stuart M. Brown, Ph.D Dept of Cell Biology NYU School of Medicine Overview This lecture will
Bioinformatics Tools Stuart M. Brown, Ph.D Dept of Cell Biology NYU School of Medicine Bioinformatics Tools Stuart M. Brown, Ph.D Dept of Cell Biology NYU School of Medicine Overview This lecture will
From Gene to Protein
 8.2 Structure of DNA From Gene to Protein deoxyribonucleic acid - (DNA) - the ultimate source of all information in a cell This information is used by the cell to produce the protein molecules which are
8.2 Structure of DNA From Gene to Protein deoxyribonucleic acid - (DNA) - the ultimate source of all information in a cell This information is used by the cell to produce the protein molecules which are
Biotechnology Unit 3: DNA to Proteins. From DNA to RNA
 From DNA to RNA Biotechnology Unit 3: DNA to Proteins I. After the discovery of the structure of DNA, the major question remaining was how does the stored in the 4 letter code of DNA direct the and of
From DNA to RNA Biotechnology Unit 3: DNA to Proteins I. After the discovery of the structure of DNA, the major question remaining was how does the stored in the 4 letter code of DNA direct the and of
Lecture 2: Central Dogma of Molecular Biology & Intro to Programming
 Lecture 2: Central Dogma of Molecular Biology & Intro to Programming Central Dogma of Molecular Biology Proteins: workhorse molecules of biological systems Proteins are synthesized from the genetic blueprints
Lecture 2: Central Dogma of Molecular Biology & Intro to Programming Central Dogma of Molecular Biology Proteins: workhorse molecules of biological systems Proteins are synthesized from the genetic blueprints
Unit 5 DNA, RNA, and Protein Synthesis
 1 Biology Unit 5 DNA, RNA, and Protein Synthesis 5:1 History of DNA Discovery Fredrick Griffith-conducted one of the first experiment s in 1928 to suggest that bacteria are capable of transferring genetic
1 Biology Unit 5 DNA, RNA, and Protein Synthesis 5:1 History of DNA Discovery Fredrick Griffith-conducted one of the first experiment s in 1928 to suggest that bacteria are capable of transferring genetic
Klinisk kemisk diagnostik BIOINFORMATICS
 Klinisk kemisk diagnostik - 2017 BIOINFORMATICS What is bioinformatics? Bioinformatics: Research, development, or application of computational tools and approaches for expanding the use of biological,
Klinisk kemisk diagnostik - 2017 BIOINFORMATICS What is bioinformatics? Bioinformatics: Research, development, or application of computational tools and approaches for expanding the use of biological,
Biological databases an introduction
 Biological databases an introduction By Dr. Erik Bongcam-Rudloff SGBC-SLU 2016 VALIDATION Experimental Literature Manual or semi-automatic computational analysis EXPERIMENTAL Costs Needs skilled manpower
Biological databases an introduction By Dr. Erik Bongcam-Rudloff SGBC-SLU 2016 VALIDATION Experimental Literature Manual or semi-automatic computational analysis EXPERIMENTAL Costs Needs skilled manpower
Multiple choice questions (numbers in brackets indicate the number of correct answers)
") 1 February 15, 2013 Multiple choice questions (numbers in brackets indicate the number of correct answers) 1. Which of the following statements are not true Transcriptomes consist of mrnas Proteomes consist
1 February 15, 2013 Multiple choice questions (numbers in brackets indicate the number of correct answers) 1. Which of the following statements are not true Transcriptomes consist of mrnas Proteomes consist
Molecular Genetics of Disease and the Human Genome Project
 9 Molecular Genetics of Disease and the Human Genome Project Fig. 1. The 23 chromosomes in the human genome. There are 22 autosomes (chromosomes 1 to 22) and two sex chromosomes (X and Y). Females inherit
9 Molecular Genetics of Disease and the Human Genome Project Fig. 1. The 23 chromosomes in the human genome. There are 22 autosomes (chromosomes 1 to 22) and two sex chromosomes (X and Y). Females inherit
Annotating the Genome (H)
") Annotating the Genome (H) Annotation principles (H1) What is annotation? In general: annotation = explanatory note* What could be useful as an annotation of a DNA sequence? an amino acid sequence? What
Annotating the Genome (H) Annotation principles (H1) What is annotation? In general: annotation = explanatory note* What could be useful as an annotation of a DNA sequence? an amino acid sequence? What
Name 10 Molecular Biology of the Gene Test Date Study Guide You must know: The structure of DNA. The major steps to replication.
 Name 10 Molecular Biology of the Gene Test Date Study Guide You must know: The structure of DNA. The major steps to replication. The difference between replication, transcription, and translation. How
Name 10 Molecular Biology of the Gene Test Date Study Guide You must know: The structure of DNA. The major steps to replication. The difference between replication, transcription, and translation. How
DNA is normally found in pairs, held together by hydrogen bonds between the bases
 Bioinformatics Biology Review The genetic code is stored in DNA Deoxyribonucleic acid. DNA molecules are chains of four nucleotide bases Guanine, Thymine, Cytosine, Adenine DNA is normally found in pairs,
Bioinformatics Biology Review The genetic code is stored in DNA Deoxyribonucleic acid. DNA molecules are chains of four nucleotide bases Guanine, Thymine, Cytosine, Adenine DNA is normally found in pairs,
Lecture Overview. Overview of the Genetic Information. Marieb s Human Anatomy and Physiology. Chapter 3 DNA & RNA Protein Synthesis Lecture 6
 Marieb s Human Anatomy and Physiology Marieb Hoehn Chapter 3 DNA & RNA Protein Synthesis Lecture 6 Lecture Overview The Genetic Information Structure of DNA/RNA DNA Replication Overview of protein synthesis
Marieb s Human Anatomy and Physiology Marieb Hoehn Chapter 3 DNA & RNA Protein Synthesis Lecture 6 Lecture Overview The Genetic Information Structure of DNA/RNA DNA Replication Overview of protein synthesis
Molecular Genetics. The flow of genetic information from DNA. DNA Replication. Two kinds of nucleic acids in cells: DNA and RNA.
 Molecular Genetics DNA Replication Two kinds of nucleic acids in cells: DNA and RNA. DNA function 1: DNA transmits genetic information from parents to offspring. DNA function 2: DNA controls the functions
Molecular Genetics DNA Replication Two kinds of nucleic acids in cells: DNA and RNA. DNA function 1: DNA transmits genetic information from parents to offspring. DNA function 2: DNA controls the functions
Biotechnology and DNA Technology
 11/27/2017 PowerPoint Lecture Presentations prepared by Bradley W. Christian, McLennan Community College CHAPTER 9 Biotechnology and DNA Technology Introduction to Biotechnology Learning Objectives Compare
11/27/2017 PowerPoint Lecture Presentations prepared by Bradley W. Christian, McLennan Community College CHAPTER 9 Biotechnology and DNA Technology Introduction to Biotechnology Learning Objectives Compare
Bio11 Announcements. Ch 21: DNA Biology and Technology. DNA Functions. DNA and RNA Structure. How do DNA and RNA differ? What are genes?
 Bio11 Announcements TODAY Genetics (review) and quiz (CP #4) Structure and function of DNA Extra credit due today Next week in lab: Case study presentations Following week: Lab Quiz 2 Ch 21: DNA Biology
Bio11 Announcements TODAY Genetics (review) and quiz (CP #4) Structure and function of DNA Extra credit due today Next week in lab: Case study presentations Following week: Lab Quiz 2 Ch 21: DNA Biology
The Nature of Genes. The Nature of Genes. The Nature of Genes. The Nature of Genes. The Nature of Genes. The Genetic Code. Genes and How They Work
 Genes and How They Work Chapter 15 Early ideas to explain how genes work came from studying human diseases. Archibald Garrod studied alkaptonuria, 1902 Garrod recognized that the disease is inherited via
Genes and How They Work Chapter 15 Early ideas to explain how genes work came from studying human diseases. Archibald Garrod studied alkaptonuria, 1902 Garrod recognized that the disease is inherited via
Computational Biology and Bioinformatics
 Computational Biology and Bioinformatics Computational biology Development of algorithms to solve problems in biology Bioinformatics Application of computational biology to the analysis and management
Computational Biology and Bioinformatics Computational biology Development of algorithms to solve problems in biology Bioinformatics Application of computational biology to the analysis and management
DNA and RNA Structure Guided Notes
 Nucleic acids, especially DNA, are considered as the key biomolecules that guarantee the continuity of life. DNA is the prime genetic molecule which carry all the hereditary information that's passed from
Nucleic acids, especially DNA, are considered as the key biomolecules that guarantee the continuity of life. DNA is the prime genetic molecule which carry all the hereditary information that's passed from
NCBI & Other Genome Databases. BME 110/BIOL 181 CompBio Tools
 NCBI & Other Genome Databases BME 110/BIOL 181 CompBio Tools Todd Lowe March 31, 2011 Admin Reading Dummies Ch 3 Assigned Review: "The impact of next-generation sequencing technology on genetics" by E.
NCBI & Other Genome Databases BME 110/BIOL 181 CompBio Tools Todd Lowe March 31, 2011 Admin Reading Dummies Ch 3 Assigned Review: "The impact of next-generation sequencing technology on genetics" by E.
Roadmap. The Cell. Introduction to Molecular Biology. DNA RNA Protein Central dogma Genetic code Gene structure Human Genome
 Introduction to Molecular Biology Lodish et al Ch1-4 http://www.ncbi.nlm.nih.gov/books EECS 458 CWRU Fall 2004 DNA RNA Protein Central dogma Genetic code Gene structure Human Genome Roadmap The Cell Lodish
Introduction to Molecular Biology Lodish et al Ch1-4 http://www.ncbi.nlm.nih.gov/books EECS 458 CWRU Fall 2004 DNA RNA Protein Central dogma Genetic code Gene structure Human Genome Roadmap The Cell Lodish
Molecular Genetics Quiz #1 SBI4U K T/I A C TOTAL
 Name: Molecular Genetics Quiz #1 SBI4U K T/I A C TOTAL Part A: Multiple Choice (15 marks) Circle the letter of choice that best completes the statement or answers the question. One mark for each correct
Name: Molecular Genetics Quiz #1 SBI4U K T/I A C TOTAL Part A: Multiple Choice (15 marks) Circle the letter of choice that best completes the statement or answers the question. One mark for each correct
Lecture 2: Biology Basics Continued. Fall 2018 August 23, 2018
 Lecture 2: Biology Basics Continued Fall 2018 August 23, 2018 Genetic Material for Life Central Dogma DNA: The Code of Life The structure and the four genomic letters code for all living organisms Adenine,
Lecture 2: Biology Basics Continued Fall 2018 August 23, 2018 Genetic Material for Life Central Dogma DNA: The Code of Life The structure and the four genomic letters code for all living organisms Adenine,
Algorithms in Bioinformatics
 Algorithms in Bioinformatics Sami Khuri Department of Computer Science San José State University San José, California, USA khuri@cs.sjsu.edu www.cs.sjsu.edu/faculty/khuri Outline Central Dogma of Molecular
Algorithms in Bioinformatics Sami Khuri Department of Computer Science San José State University San José, California, USA khuri@cs.sjsu.edu www.cs.sjsu.edu/faculty/khuri Outline Central Dogma of Molecular
Genome and DNA Sequence Databases. BME 110: CompBio Tools Todd Lowe April 5, 2007
 Genome and DNA Sequence Databases BME 110: CompBio Tools Todd Lowe April 5, 2007 Admin Reading: Chapters 2 & 3 Notes available in PDF format on-line (see class calendar page): http://www.soe.ucsc.edu/classes/bme110/spring07/bme110-calendar.html
Genome and DNA Sequence Databases BME 110: CompBio Tools Todd Lowe April 5, 2007 Admin Reading: Chapters 2 & 3 Notes available in PDF format on-line (see class calendar page): http://www.soe.ucsc.edu/classes/bme110/spring07/bme110-calendar.html
Nucleic Acid Structure:
 Genetic Information In Microbes: The genetic material of bacteria and plasmids is DNA. Bacterial viruses (bacteriophages or phages) have DNA or RNA as genetic material. The two essential functions of genetic
Genetic Information In Microbes: The genetic material of bacteria and plasmids is DNA. Bacterial viruses (bacteriophages or phages) have DNA or RNA as genetic material. The two essential functions of genetic
Do you think DNA is important? T.V shows Movies Biotech Films News Cloning Genetic Engineering
 DNA Introduction Do you think DNA is important? T.V shows Movies Biotech Films News Cloning Genetic Engineering At the most basic level DNA is a set of instructions for protein construction. Structural
DNA Introduction Do you think DNA is important? T.V shows Movies Biotech Films News Cloning Genetic Engineering At the most basic level DNA is a set of instructions for protein construction. Structural
O C. 5 th C. 3 rd C. the national health museum
 Elements of Molecular Biology Cells Cells is a basic unit of all living organisms. It stores all information to replicate itself Nucleus, chromosomes, genes, All living things are made of cells Prokaryote,
Elements of Molecular Biology Cells Cells is a basic unit of all living organisms. It stores all information to replicate itself Nucleus, chromosomes, genes, All living things are made of cells Prokaryote,
Gene Regulation 10/19/05
 10/19/05 Gene Regulation (formerly Gene Prediction - 2) Gene Prediction & Regulation Mon - Overview & Gene structure review: Eukaryotes vs prokaryotes Wed - Regulatory regions: Promoters & enhancers -
10/19/05 Gene Regulation (formerly Gene Prediction - 2) Gene Prediction & Regulation Mon - Overview & Gene structure review: Eukaryotes vs prokaryotes Wed - Regulatory regions: Promoters & enhancers -
Biology 3201 Genetics Unit #5
 Biology 3201 Genetics Unit #5 Protein Synthesis Protein Synthesis Protein synthesis: this is the process whereby instructions from DNA are used to create polypeptides that make up a protein. This process
Biology 3201 Genetics Unit #5 Protein Synthesis Protein Synthesis Protein synthesis: this is the process whereby instructions from DNA are used to create polypeptides that make up a protein. This process
The Genetic Code and Transcription. Chapter 12 Honors Genetics Ms. Susan Chabot
 The Genetic Code and Transcription Chapter 12 Honors Genetics Ms. Susan Chabot TRANSCRIPTION Copy SAME language DNA to RNA Nucleic Acid to Nucleic Acid TRANSLATION Copy DIFFERENT language RNA to Amino
The Genetic Code and Transcription Chapter 12 Honors Genetics Ms. Susan Chabot TRANSCRIPTION Copy SAME language DNA to RNA Nucleic Acid to Nucleic Acid TRANSLATION Copy DIFFERENT language RNA to Amino