GOWER COLLEGE SWANSEA AS BIOLOGY UNIT 1 NUCLEIC ACIDS DNA REPLICATION GENETIC CODE PROTEIN SYNTHESIS ATP
|
|
|
- Lambert Hawkins
- 5 years ago
- Views:
Transcription
1 GOWER COLLEGE SWANSEA AS BIOLOGY UNIT 1 NUCLEIC ACIDS DNA REPLICATION GENETIC CODE PROTEIN SYNTHESIS ATP NAME OPTION GROUP
2 NUCLEIC ACIDS 1.DNA - deoxyribonucleic acid 2. RNA - ribonucleic acid 1. DNA FUNCTIONS - To provide the GENETIC CODE or GENES. To be able to REPLICATE so that every new cell has a copy of the genetic code. The three-dimensional structure of DNA was discovered in 1953 by Watson and Crick in Cambridge, using experimental data of Wilkins and Franklin in London, for which work they won a Nobel Prize. In eukaryotic cells DNA is found in the nucleus. In prokaryotic cells DNA is in the cytoplasm as one large circle and several small circular plasmids. THINK - Why is it confined to the nucleus in eukaryotes?. DNA is a double stranded molecule - one molecule consists of 2 polynucleotide strands. It is around 2 nm wide. THINK - Why is it double stranded? *It is too wide to get through the nuclear pores and therefore traps the molecule in the nucleus. *A double stranded molecule can be replicated (see later notes) DNA is a stable polynucleotide - a polymer of NUCLEOTIDES (these are its monomers). THINK - Why does it need to be stable? FIRST EXAMINE THE NUCLEOTIDES Nucleotides contain the elements C H O N P, and have three parts to them:
3 a phosphate group (PO 4 2- ), which is negatively charged, and gives nucleic acids their acidic properties. a pentose sugar, which has 5 carbon atoms. If carbon 2' has a hydroxyl group attached, then the sugar is ribose, found in RNA. If the carbon 2' just has a hydrogen atom attached instead, then the sugar is deoxyribose, found in DNA. a nitrogenous base. There are five different bases ( you don't need to know their individual structures), they contain the elements carbon, hydrogen, oxygen and nitrogen. Since there are five bases, there are five different nucleotides: Base: Adenine (A) Cytosine (C) Guanine (G) Thymine (T) Uracil (U) In DNA there are only adenine, guanine, cytosine and thymine (NO uracil)

4 FORMING A NUCLEIC ACID POLYMER Nucleotides polymerise by forming phosphodiester bonds between carbon 3' of the sugar and an oxygen atom of the phosphate. The result is known as the SUGAR PHOSPHATE BACKBONE and the bases take no part in this reaction. It is a CONDENSATION REACTION. THINK. What is released? A nucleic acid may be many hundreds of nucleotides long, a POLYNUCLEOTIDE. Because each nucleotide is offset slightly, the chain gradually forms a helix. Not a spiral. The SEQUENCE of the 4 nucleotides is critical as they will be repeated many times and form the genetic code. A polynucleotide has a free phosphate group at one end, called the 5' end because the phosphate is attached to carbon 5' of the sugar, and a free OH group at the other end, called the 3' end because it's on carbon3' of the sugar. The terms 3' and 5' are often used to denote the different ends of a DNA molecule. But this only produces a single strand. DNA is double stranded. To form a double strand, a second strand must bond to the first. It does this by forming HYDROGEN BONDS between the nitrogenous bases. THINK Are H bonds weak or strong and what will be the effect of having many of them?
5 First let's look at the bases. Two of them have only one ring structure - these are PYRIMIDINE BASES - thymine and cytosine. Two of them have a double ring structure - these are PURINE BASES - adenine and guanine. Two of them have 2 possible hydrogen bonds - adenine and thymine (T for Two and Thymine Two of them have 3 possible hydrogen bonds - cytosine and guanine The bases will only bond with a specific COMPLEMENTARY BASE. ADENINE with THYMINE and GUANINE with CYTOSINE. They obey 2 COMPLEMENTARY BASE PAIRING 'RULES' 1. A purine must pair with a pyrimidine. THINK What effect will this have on the distance between the two sugar phosphate 'backbones'? 2. The number of hydrogen bonds must match. 2 to 2 and 3 to 3. The only possible combination therefore becomes; ADENINE with THYMINE, and GUANINE and CYTOSINE (A T Gower College!!)

6 Next, consider how the two strands must be orientated. The two strands of DNA are ANTIPARALLEL. THINK What does this mean and why is it necessary? The nitrogenous bases must be opposite each other if they are to form H bonds between them. THINK What effect will two complementary strands have on the ability of DNA to replicate itself. THINK How will a double strand improve the stability of the molecule?


.")
7 The complimentary base pairing rules mean that the ratio of Thymine to Adenine is always 1:1 and the ratio of Guanine to Cytosine is always 1:1 in DNA. Experiments by Erwin Chargaff have confirmed this to be true. He extracted the DNA from different species of organisms and measured the percentage of each nucleotide present in their DNA. Note the following 1. In each organism, the percentages for all four bases add up to 100% in total. 2. The percentage of any one base can vary from one organism to another. This is because organisms are genetically different from each other with a different nucleotide sequence in their DNA. 3. The percentage of some complementary bases are slightly different. This is due to some experimental errors. If the % of A and T are very different and the % of G and C are also very different, there is no complementary pairing and the nucleic acid is likely to be single stranded (see the structure of RNA). The result is an antiparallel, double stranded, helix. Each 'twist' of the helix is 10 nm long. You could be asked to calculate the % of each base from the % of only one of them. In DNA, if one base % is known, it is straightforward to calculate the other three.
 34 + 34 = 68% 100% - 68% = 32% remaining; This must be equally divided between the other two nucleotides (because they are")
8 eg if there is 34% Adenine... There must also be 34% Thymine (because they are complementary) = 68% 100% - 68% = 32% remaining; This must be equally divided between the other two nucleotides (because they are complementary) Therefore, cytosine and guanine must have 16% each. Because each nucleotide is the same length, the DNA is measured by the number of nucleotide repeats. Kilo base pairs = the number of thousand base pairs.

9 In the nucleus, it is folded and wrapped around proteins called HISTONES. A full length of DNA is a CHROMOSOME In Eukaryotic cells the DNA is linear. In Prokaryotic cells, the DNA is circular.

10 2. RNA - RiboNucleic Acid A Single stranded polynucleotide molecule. The sugar is RIBOSE. There is no Thymine. It is replaced by URACIL (also a pyrimidine base) It is shorter than DNA. There are 3 types of RNA 1. Messenger RNA - mrna Produced in the nucleus and diffuses into the cytoplasm. THINK How does its single stranded structure enable this movement to happen? mrna is made as a complementary copy of one of the DNA strands (a template strand). mrna is shorter than DNA. This is because it is a copy of only part of the DNA - one gene only. mrna is not folded.
11 There is a sequence of many triplet (3) base CODONS along the length of the molecule. These are complementary to DNA triplets (which are NOT called codons. Codons are parts of mrna only) 2. Transfer RNA - trna Found in the cytoplasm only. trna is folded so that it has a specific structure/shape. The folds are held by hydrogen bonds between complementary base pairs so all trna molecules The sequence of nucleotides at these places is the same for all trna molecules.. At the apex of one of the loops,there is one anticodon, a triplet of 3 nucleotides, that are complementary to one of the codons on the mrna. There is one amino acid binding site which enables a specific amino acid to attach to it in the cytoplasm. This has the base sequence ACC. The exact amino acid is determined by the codon/anticodon. This means there are many different trna molecules in the cytoplasm, (one for each triplet base codon in the mrna).
12 3. Ribosomal RNA - rrna. Formed in the nucleolus. Migrates to the cytoplasm where it combines with proteins to make ribosomes. rrna is also folded. In the table below, summarise the differences between DNA and RNA DNA RNA
13 DNA is unique in its ability to replicate itself. DNA REPLICATION DNA is copied, or replicated, before every cell division, so that one identical copy can go to each daughter cell. The method of DNA replication is indicated from its structure: The double helix unzips/separates and two new strands are built up by complementary base-pairing onto the two old strands. 1. Replication starts at a specific sequence on the DNA molecule called the replication origin. 2. An enzyme, DNA helicase unwinds and separates the two strands of DNA, breaking the hydrogen bonds between the base pairs. 3. The new DNA is built up from the four nucleotides (A, C, G and T) that are present in the nucleoplasm. 4. These nucleotides attach themselves to the bases on the old strands by complementary base pairing. Where there is a T base, only an A nucleotide will bind and where there is a C base, a G will bind. 5. The enzyme DNA polymerase joins the each new nucleotides to the next by strong covalent phosphodiester bonds, forming the sugar-phosphate backbone. The enzyme can do this in one direction only along the 'continuous strand' (leading strand), from the 5' to the 3' end. It does this in pieces along the 'discontinuous strand' (lagging strand). THINK Why does DNA polymerase form a polymer in one direction only? 6. Another enzyme, DNA ligase, joins the pieces of the discontinuous strand together. The new strands twist as they form double helices. 7. The two new DNA molecules are identical to the old molecule. Each new DNA molecule contains one "new" strand and one "old" strand.

14 THIS IS CALLED SEMI CONSERVATIVE REPLICATION. Is there evidence to support this? The Meselson-Stahl Experiment Alternative theories suggested that a "photocopy" of the original DNA could be made, leaving the original DNA conserved (conservative replication), or the old DNA molecule could be dispersed randomly in the two copies (dispersive replication).
15 Matthew Meselson and Franklin Stahl used the bacterium E. coli together with the technique of density gradient centrifugation, which separates molecules on the basis of their density. 1. Grow bacteria on medium with 'heavy' 15 N (in NH 4+ ) 2. Grow bacteria for several generations on medium with 14 N (in NH 4+.) THINK What is the purpose of the controls? Extract DNA from Bacteria and centrifuge in a density gradient of Caesium Chloride solution. The DNA will settle at the density that is equal to the density at a specific level of the solution. The heavier the DNA, the lower down the tube it will settle. Note - 1 generation = approx 20 mins. THINK DNA? why did the 1st generation hybrid DNA settle halfway between the position of light and heavy After a 2nd division in 14 N, where would the DNA settle? Explain whether there would there be any 'heavy' DNA bands after the 2nd or subsequent generations?

16 THE GENETIC CODE * A gene is a section of DNA that codes for a polypeptide.* Every molecule of DNA (CHROMOSOME) will have many genes along its length. ONE GENE CODES FOR ONE POLYPEPTIDE The sequence of amino acids makes up a polypeptide. The sequence of nucleotide bases must therefore be the code for the sequence of amino acids. * There are 20 different amino acids and only 4 nucleotide bases. one base therefore cannot code for one amino acid. * A combination of 3 nucleotide bases codes for each amino acid. This provides 4 3 or 64 possible combinations of triplets. More than enough for 20 amino acids. * On the mrna a group of 3 bases coding for an amino acid is the CODON. The meaning of each codon is the genetic code. * Most amino acids are coded for by more than one codon. There is one 'start' codon, AUG and several 'STOP' codons. These mark the beginning and the end of a gene. A specific sequence of 3 nucleotide bases (a triplet) is the code for a specific amino acid. The Genetic Code has 2 properties 1. It is Degenerate - there more than one code for most amino acids ie more codes than are needed 2. It is Non Overlapping - every 3 nucleotides are translated regardless of their sequence. GENETIC CODE FOR mrna CODONS The DNA of a gene will contain several sequences that do not code for any amino acids. These are known as INTRONS (coding DNA sequences are EXONS).

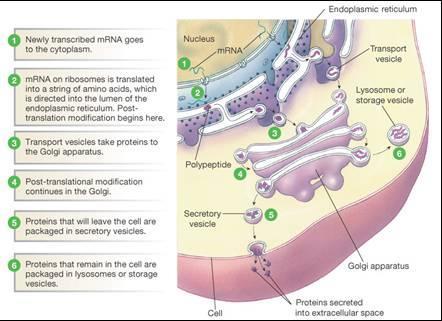
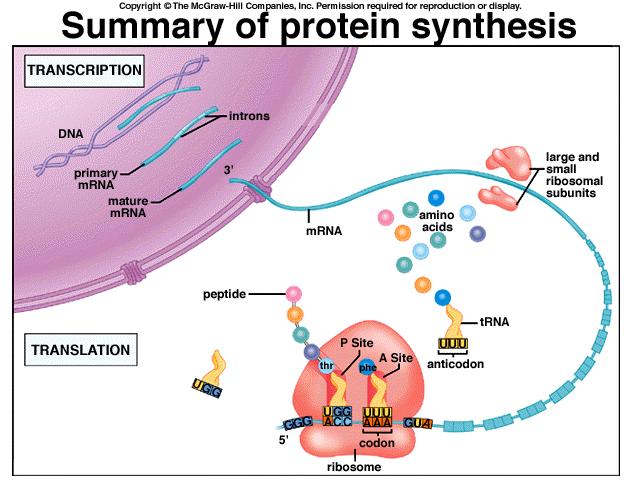
17 PROTEIN SYNTHESIS The following is a description of how the DNA code is converted/translated into a polypeptide. The process takes place in two main stages. 1. TRANSCRIPTION - This occurs in the nucleus. a. The section of DNA /gene, to transcribed unwinds and is separated by DNA helicase. b. Only one of the strands becomes a template strand. This is the SENSE STRAND. The other strand does not. This is the ANTI SENSE STRAND c. Complementary RNA nucleotides (from the nucleoplasm) form a single strand of mrna. This begins with the AUG which is the START CODON The RNA nucleotides are bonded to each other by RNA polymerase. Each group of 3 RNA nucleotides along the mrna is a CODON. d. Once complete, the mrna single strand detaches from the DNA template and diffuses out from the nucleus through a nuclear pore into the cytoplasm. It then attaches to a ribosome that is in turn, attached to the Rough Endoplasmic Reticulum (RER). In this way, many copies of the gene's code can be made and sent into the cytoplasm where many polypeptides can be produced at the same time. The DNA code remains in the nucleus. The section of DNA that was transcribed rejoins and rewinds into a helix.
.")



18 The DNA will contain several sequences that do not code for any amino acids. These are known as INTRONS (coding DNA sequences are EXONS). The introns are also transcribed but before the mrna attaches to a ribosome, the INTRONS are removed. This makes the mrna shorter than the original transcribed molecule. 2. TRANSLATION - Takes place in the cytoplasm on the RER ribosomes. a. A mrna molecule attaches to a ribosome on the RER. The first 2 triplet codons form the b. The first trna molecule attaches to AUG with the anticodon UAC. It carries the amino acid Methionine. c. A second trna molecule attaches by the ANTICODON to the adjacentcodon on the mrna. d. Each of the trna molecules is carrying a specific amino acid. The two amino acids are now alongside each other in the same relative position. A peptide bond forms between the two amino acids in a condensation reaction.


19 e. Because the amino acids are attached (forming a dipeptide at this point), it is now possible for the first trna to be released from the ribosome. The ribosome moves along the mrna by one codon. f. A new trna attaches to this codon bringing a 3rd amino acid into place which joins the 1st two forming a tripeptide. g. This process is repeated along the entire mrna sequence of codons. One specific amino acid at a time is added to the growing polypeptide chain. When the chain is complete, there is a STOP codon on the mrna. This does not code for any amino acid and the polypeptide can be detached from the ribosome. If many copies of the same mrna molecule are attached to many ribosomes, many hundreds of protein molecules can be produced in a very short time. This is known as the 'turnover rate'. Some genes are only 'switched on' to produce particular proteins in specific calls. For example, insulin is a protein that is only produced in some pancreatic cells, called beta cells. The polypeptide will have folded into its secondary and tertiary structure. It passes from the RER into the GOLGI where it can be modified. This is called POST TRANSLATIONAL MODIFICATION. It may involve cutting part of the molecule or adding another molecule to it in some way.
20
21
22 ATP - ADENOSINE TRI PHOSPHATE STRUCTURE This molecule is a type of nucleotide. It has only one type of base, adenine. (has a specific shape that complements ATPase) Adenine bonds to the pentose sugar, ribose to form adenosine. There are 3 phosphates bonded to adenosine. This makes the molecule very reactive. The terminal phosphoanhydride bond can be hydrolysed to release energy (30.5 kj mol -1 ). it is known as a high energy bond. The enzyme ATPase catalyses this reaction in cells. to produce ADP + inorganic phosphate. ATP = ADP + Pi This is and exogonic reaction - it releases energy The terminal phosphate can be rejoined to adenosine if there is enough energy available. This is a condensation reaction using the enzyme ATP synthetase, ATP synthase. This is an endogonic reaction - it uses energy. The second phosphoanhydride bond can also release 30.5kJ mol -1 ADP = AMP + Pi (AMP = adenosine monophosphate)
23 FUNCTION ATP is referred to as UNIVERSAL ENERGY CURRENCY - for the following reasons;- 1. It can store or release energy in all types of cells in all organisms. 2. It provides energy for all types of activities within cells, for example active transport protein synthesis DNA replication cell division muscle contraction nerve impulse transmission formation of carbohydrates nitrogen fixation. NOTE - You may be required to suggest what specific cells use ATP for. Think what the cell may be doing. it is also known as an 'immediate' source of energy because, 1. It takes only one reaction and therefore only one enzyme to hydrolyse it. 2. The quantity of energy released is small enough for the sort of reactions it is used for inside a cell. ATP can cross some membranes, for example the membranes of the mitochondria where it is made during respiration. ATP cannot cross other membranes such as the plasma membrane. Therefore each cell has to produce its own ATP and usually it can't be passed from one cell to another.





24 Where is it formed? It is formed during respiration as energy is released from substrates like glucose. In the MITOCHONDRIA of eukaryotic cells during aerobic respiration (NOTE - many mitochondria indicate more energy is released as more aerobic respiration is possible) In the cytoplasm of most cells during anaerobic respiration (NOTE - very little energy is released ) On the mesosomes (folded inner membrane) of some bacteria during aerobic respiration. On the thylakoid membranes of Chloroplasts during the light dependent reactions of photosynthesis.