Informatic Issues in Genomics
|
|
|
- Annabelle Lawrence
- 5 years ago
- Views:
Transcription
1 Informatic Issues in Genomics DEISE PRACE Symposium Barcelona, May 2010 Ivo Glynne Gut, PhD Centro Nacional de Analisis Genomico Barcelona
2 Our Objectives Improve the quality of life Understand the function of genomes



3 Basic biology Folding Post translational modification
4 3 x 10 9 bases/nucleotides < 1 % coding genes Human genome
5 Human genome sequencing project Baseline nucleotide sequence of one individual 3 x 10 9 $ Involved the labour of thousands of people Factories of automated sequencing instruments
6 Polymorphisms TGCATATGCAAGTAACCGTA ACGTATACGTTCATTGGCAT TGCATATGCAAATAACCGTA ACGTATACGTTTATTGGCAT
7 Genome Variation Only identical twins have the same DNA sequences 2x10 7 bases in the human genome are variable Average differences between two humans 0.1 % of their genome Difference between human and chimpanzee is about 1 %
8 Human HapMap...mapping ancestral haplotype blocks across the genome Common samples (288 samples from several populations) Genotype ~1 million SNPs, 5% frequency Select haplotype tag SNPs Has helped advance technology and genome knowledge Benefit to complex disease genetics?
9 Detection of frequent disease associated variants 1. case control Scan genome for all in DNA collection with 317,000 variants 2. Log 10 p value Identify regions of marked differences in frequencies of variants in cases/controls 3. case control Confirm in additional larger collections

10 Phase 2 Asthma Genome Wide Association Study cases


11 Identification of genetic predisposition to lung cancer (Hung et al., Nature 2008) 1989 lung cancer cases 2625 hospital matched controls 310,023 SNPs Genome wide significance p<5x10 7 P = 10 10
12 Impact on life time risk of lung cancer death Example from Poland CC genotype occurs in about 12% of population
 ~90 myopathy cases and ~90 matched controls with 300,000 genetic markers (and fine mapping)")
 per C allele and 16.9 (4.7 61.")
13 SLCO1B1 Variants and Statin Induced Myopathy Simvastatin 80 mg daily (Link et al., NEJM 2008) ~90 myopathy cases and ~90 matched controls with 300,000 genetic markers (and fine mapping) Strong association with myopathy risk of single marker (unadjusted p=4x10 9) Odds ratio of 4.5 ( ) per C allele and 16.9 ( ) for CC vs TT Prevalence of C allele is 15 %: more than 60 % of myopathy cases can be attributed to C variant

14 Asthma : Moffat et al. Nature, :470 3; Bouzigon et al. N Engl J Med, 359: , 2008 Lung cancer: Huang et al. Nature,452:633 7, 2008; McKay et al. Nat Genet, 40:1404 6, 2008 Glioma: Shete et al. Nat Genet, submitted, 2009 Melanoma: Bishop et al. Nat Genet, submitted, 2009 Crohn s disease Libouelle et al. PLoS Genetics 3:e58, 2007; Barrett et al. Nat Genet, 40:955 62, 2008 Thrombosis: Tregouet et al. Blood, in press, Cardiovascular disease: Farrall et al. N Engl J Med, submitted, Lipids: Kathiresan et al. Nat Genet, 41:56 65, 2009 ; Willer et al., Nat Genet, 40: 161 9, Hypertension: Caulfield et al. PLoS Med, 5:e197, 2008 Global BPgen Consortium Nat Genet, in press, 2009 Psoriasis: Nair et al. Nat Genet, 41: , 2009 Modifier genes of Mendelian disease: Menzel et al. Nat Genet, 39:1197 9, 2007; Thein et al. PNAS, 4: , 2007 Pharmacogenetics: Link et al. N Engl J Med, 359: , 2008 Association of globale gene expression: Dixon et al. Nat Genet, 39:1202 7, 2007 ETC...
15 GWAS database ( 5/05/ publications 2704 variants




16 Number of Individuals Number of different SNPs
17 Sequencing methods 1 st generation DNA sequencing Fred Sanger 2 nd generation DNA sequencing rd generation DNA sequencing 2011

18 Illumina Solexa 1G Sequencer (2007) Cost: To sequence initially at 1/100 th current costs Throughput: To sequence in excess of 1 Gbase per experiment Accuracy: To generate high accuracy raw data with reliable quality metrics Cost/human genome 150 k$ 6 months




19 Clonal Single Molecule Arrays Prepare DNA fragments Ligate adapters Attach single molecules to surface Amplify to form clusters 100um Random array of clusters ~1000 molecules per ~ 1 um cluster ~1000 clusters per 100 um square ~40 million clusters per experiment
20 Sequencing by synthesis (SBS) 3 5 Cycle 1: Add sequencing reagents First base incorporated Remove unincorporated bases G A T C T C A G T A G C T G C T A C G A T A C C C G A T C G A Detect signal Cycle 2 n: Add sequencing reagents and repeat All four labelled nucleotides in one reaction High accuracy Base by base sequencing No problems with homopolymer repeats T 5



21 100 microns 20 microns









22 Base Calling From Raw Data T G C T A C G A T T T T T T T T G T The identity of each base of a cluster is read off from sequential images
23 Sequencing throughput 1 st generation ~1 million bases/instrument*day Only method until nd generation 2005 ~10 million bases/instrument*day 2007 ~100 million bases/instrument*day 2010 ~ 6 billion bases/instrument*day

24 Cornerposts 2 nd generation sequencing Complete human genome 30x coverage <30 k 1 month instrument time Short, clonal reads... Sequence only targeted areas of a genome 3 rd generation sequencing Complete human genome <1 k <1 day Long, clonal reads Lower error rate No replication chemistry... Complete genome sequence

25 Evolution of Genome databases
26 Human genomes first human genome sequence 2006 three complete genomes complete genomes CNAG projection complete human genomes CNAG projection 2012 > 1000 complete human genomes

27 We are outpacing Moore s law

28 3rd generation sequencing: Exonuclease αhl Nanopore Oxford Nanopore Technologies


29 Protein Nanopores in Apertures Placing αhl directly within apertures in solid materials to remove lipid bilayers Improved stability, greater range of experimental conditions, easier fabrication in large scale arrays Modifying αhl to localise and provide attachment sites to aperture ~3-8nm UOXF, TUD
30 Covalent Cyclodextrin enables Base Recognition Nature Nanotechnology (2009) ONT, UOXF









31 Centro Nacional de Análisis Genómico 11 Illumina GA2x 4 Illumina qbots 850 core cluster super computer 1.2 petabyte hardiscs The Genomehenge Sequencing capacity 50 Gbases/day now 200 Gbases/day in 2011 Barcelona Super Computer 10 x 10 Gb/s > cores

32 Centro Nacional de Análisis Genómico Biological Resources Cancer Genomics Sequencing Platform Informatics Disease Gene Identification Infectious Disease Genomics QC Storage Conditioning Genome sequencing Sample preparation Targeted re sequencing RNA sequencing Sequencing Production Epigenetic sequencing Variant validation. Methods development Quality Control Data Analysis Statistics Data basing. Livestock and Plant Genomics Genomics for Reagent Production Technology Development

33 Systematic Data Gathering




34 Structure of the Cancer Genome Analysis
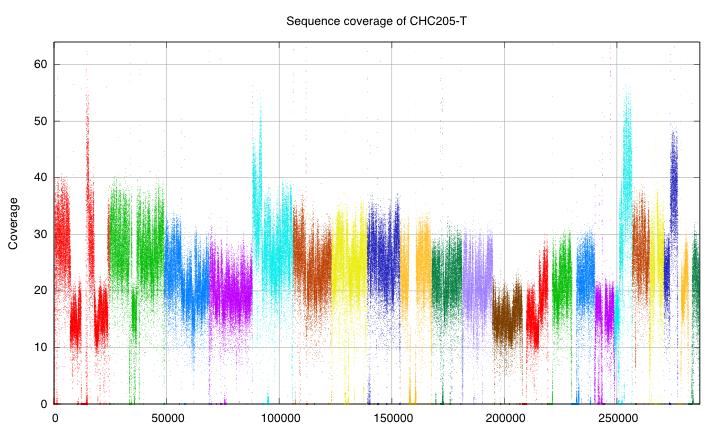
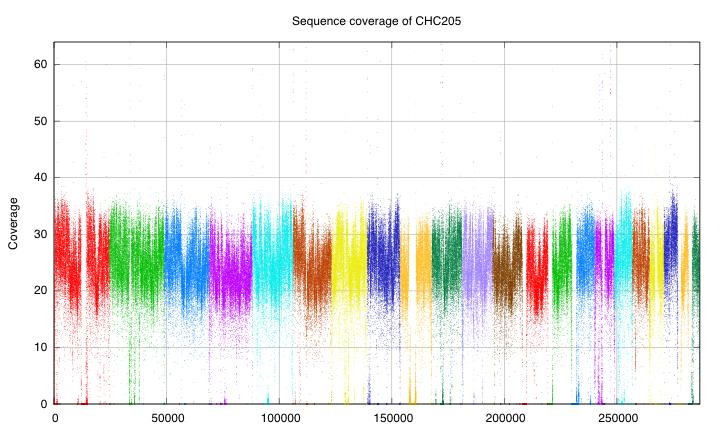
35
36 Analysis strategies Re alignement of ~ 1 billion of 100 base short reads Reference bias De novo assembly from ~1 billions 100 base short reads
37 Observations Identification of large numbers of cancerrelated somatic events Single base changes Indels Duplications Rearrangements Validation Understanding Translation into targeted, minimally invasive, cost effective diagnostic tests with good specificity and sensitivity
38 Data Amount of data is one issue However, genes are not used in a linear sequence, they act as a complex interplay genes!!! Modelling of processes Comparisons of 10 s of thousands of genomes with eachother


39 In situ transcript genotyping A padlock probe and RCA approach Larsson, C. et al. (2010) Nature Methods, in press.