Sequencing techniques
|
|
|
- Kelley Carr
- 5 years ago
- Views:
Transcription
1 Sequencing techniques Workshop on Whole Genome Sequencing and Analysis, 2-4 Oct. 2017
..identify the elements that make up the raw sequence files..at a general level assess the quality of your data")
2 Learning objective: After this lecture, you should be able to account for different techniques for whole genome sequencing (Illumina, Ion Torrent, PacBio, Nanopore)..identify the elements that make up the raw sequence files..at a general level assess the quality of your data


3 Preparing for sequencing 2nd generation sequencing have many steps in common 1. DNA isolation 2. DNA fragmentation Barcode Isolated DNA 3. Primer ligation 4. Amplification Sequencing primers Amplification primers
4 Illumina sequencing
5
6
7
8
9

10
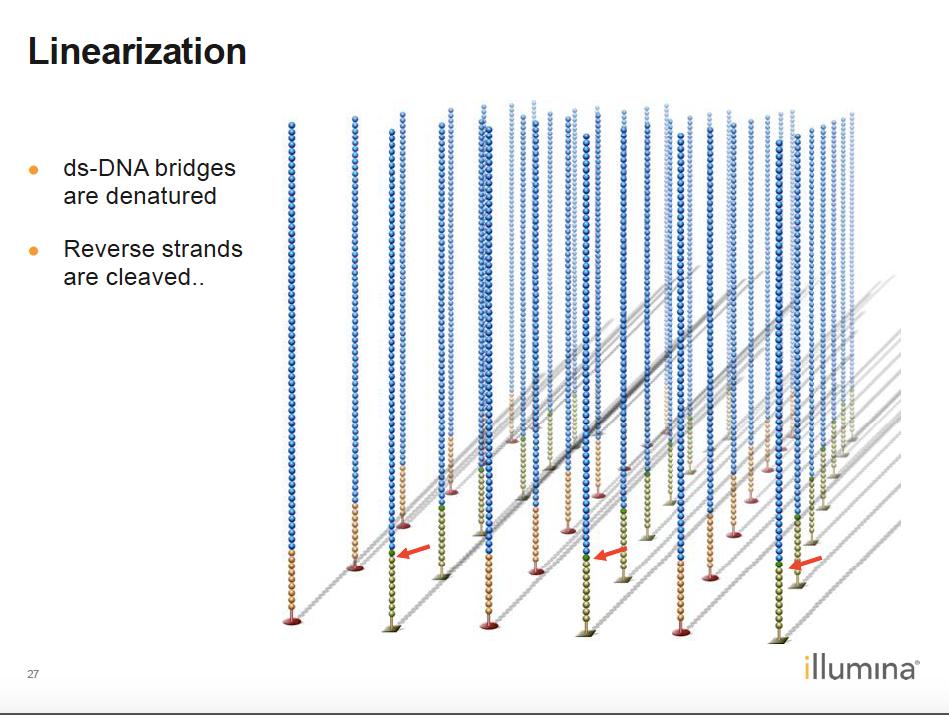
11
12
13
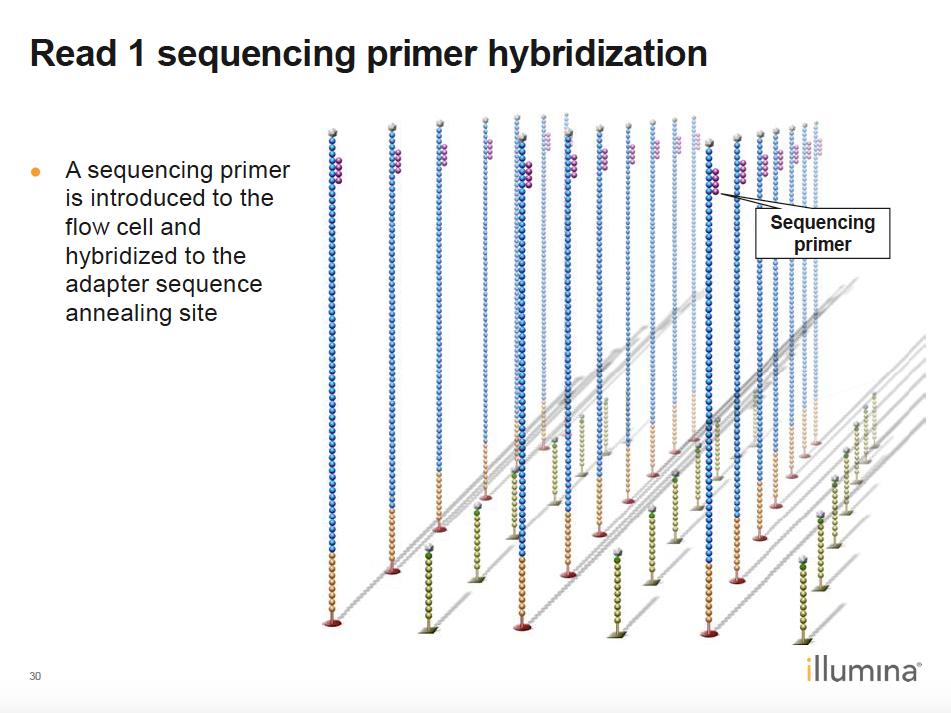
14
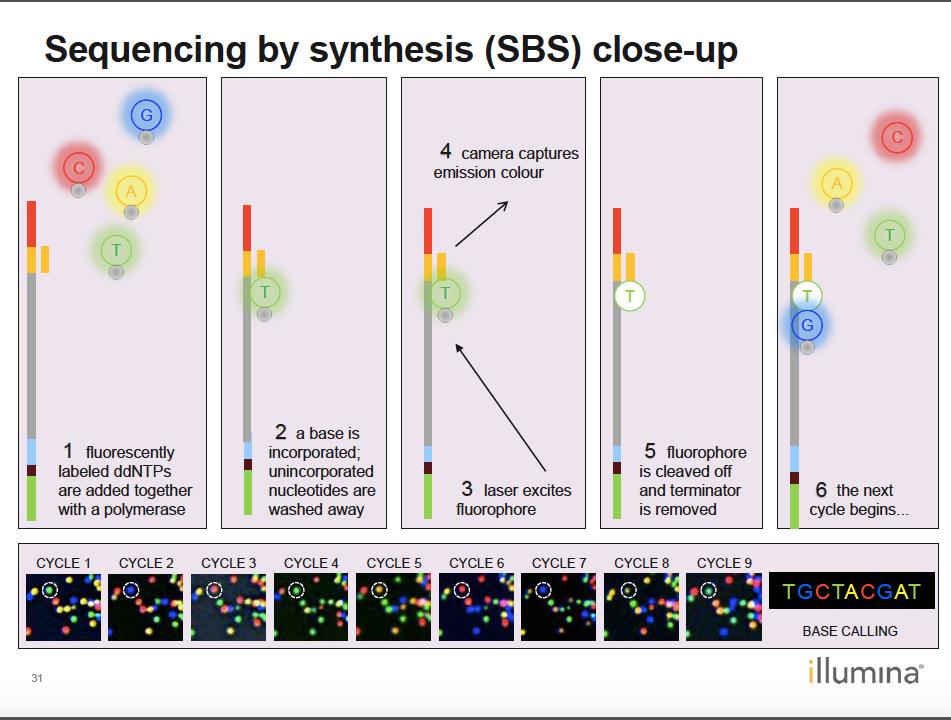
15

16 Question In the figure above each coloured spot represents a spot on the flow cell where millions of identical DNA templates are clustered and each grey square one cycle of sequencing. What is the sequence of the template DNA strand in the lower right corner of the flow cell?
17
18
19
20
21
22 Illumina reads have equal lengths. One base is determined per cycle A T C A C T A C A A G T A T T A C C C C T >Read_1 >Read_2 >Read_3 End cycle 1: A C A C T G G T G A T C A C A C T G G T G AT End cycle 2: TC CA C T T A C A C G End cycle 3: ATA CAT TCC

23 Ion Torrent - also a 2nd gen. sequencing technology Does not rely on optical signals from fluorescently labelled nucleotides Detects the small ph change caused by H+ release, when a nucleotide is incorporated Has difficulties correctly calling homopolymers (stretches of identical nucleotides)
24 Question Type of nucleotide flooded across well Imagine the above is the output from an Ion Torrent run. Which sequence does it represent?
25 Ion Torrent reads do not usually have equal lengths A C A T G A C G T C C G C C A T C G A T G C GA CT C GA C T A >Read_1 >Read_2 >Read_3 End cycle 1: 2: 3: 4: A CA T TGCCCA
26 Third generation sequencing No template amplification step (single molecule sequencing) Fast Produces very long reads (>10,000 bp) Assembly gets much easier
27 PacificBiosciences - PacBio (3rd gen. sequencing) The first 3rd generation sequencer on the market Uses Single-Molecule Sequencing in Real Time (SMRT) technology Single DNA polymerases are attached to the bottom surface of individual detector wells DNA is sequenced as fluorescently labelled nucleotides are incorporated into the complementary strand, since incorporation results in retention of the nucleotide, and this retention can be detected
 Reagent costs per run is expensive when only one bacterial strains")
 up to 12-plex and 2 Mb ge")
28 PacBio RSII Advantages: Long reads Quick run time Disadvantages: Big, expensive machine Relatively low accuracy (but not context specific errors) Reagent costs per run is expensive when only one bacterial strains is sequenced per run Sequel Recently: Protocol for multiplexing 5 Mb microbial genomes (e.g., E. coli) up to 12-plex and 2 Mb genomes (e.g., Campylobacter) up to 16-plex making sequencing of microbial genomes more affordable.
 The newest kid in class Sequences")

 So far also very high error rates (up to")
29 Oxford Nanopore (3rd. gen. sequencing) The newest kid in class Sequences while singlestranded DNA is passed through nanopore The minion is the size of a small cell phone VERY long reads (up to ?) So far also very high error rates (up to 15%)
30 Comparing sequencing technologies Costs Max. read sequencing Output per Average run Platform Sequencer lengths platform run/lane time (bp) ($) Illumina HiSeq , gbp days Illumina MiSeq 100, gbp days Ion torrent Proton II 224, gbp hours Ion torrent PGM ,000 2 gbp hours PacBio RS II 700, mbp 54,000 3 hours Nanopore MinION 1, gbp 150,000 n.a* Bleidorn C., Systematics and Biodiversity (2016), 14(1):1-8 * Machine run time is adjusted to need of sequencing depth. Example given is for 48 hours
31 What is the data? Fastq files Fastq example: 1 read, 4 ACNGTGTTTTTAGTTATTGTTTTGTTAAGTTGGGTTTTTTGTACCCAATAGCCAACAAGCCGCCTTTATGGCGGTTTTTTTGTGCCTGAAAAGTGGGCGCA + ACGTTAGCAGAATCGCTTTCTGTTCGTTTTCCACCTGCGACAGACGCACCGGACCACGGTTGGCGAGATCGTCGCGCAGAATATCGGCGGCACGCTGCGAC + AGCGTGACAAACATTTTATTGCGCCCGGTTTTATCCAGCTTGAATGCCTGACGAAAGAAGATGATGGTGACGACGATGGAGAGAACAATCAGCACCAGATT + AGCGTCTGACTCACACAAAAACGGTAACACAGTTATCCACAGAATCAGGGGATAAGGCCGGAAAGAACATGTGAGCAAAAAGGCAAAGCCAGGACAAAAGG + bbbeeeeegggggiiiiiiiiiigifhhiiighiiihhiiiiiiihiiiiiiiiiihiigcdbbdcdcccccdccccccccacccccccbcccacccccc
32 What is the data? Fastq files Fastq Header/ID ACNGTGTTTTTAGTTATTGTTTTGTTAAGTTGGGTTTTTTGTACCCAATAGCCAACAAGCCGCCTTTATGGCGGTTTTTTTGTGCCTGAAAAGTGGGCGCA + ACGTTAGCAGAATCGCTTTCTGTTCGTTTTCCACCTGCGACAGACGCACCGGACCACGGTTGGCGAGATCGTCGCGCAGAATATCGGCGGCACGCTGCGAC + AGCGTGACAAACATTTTATTGCGCCCGGTTTTATCCAGCTTGAATGCCTGACGAAAGAAGATGATGGTGACGACGATGGAGAGAACAATCAGCACCAGATT + AGCGTCTGACTCACACAAAAACGGTAACACAGTTATCCACAGAATCAGGGGATAAGGCCGGAAAGAACATGTGAGCAAAAAGGCAAAGCCAGGACAAAAGG + bbbeeeeegggggiiiiiiiiiigifhhiiighiiihhiiiiiiihiiiiiiiiiihiigcdbbdcdcccccdccccccccacccccccbcccacccccc
33 What is the data? Fastq files Fastq DNA sequence ACNGTGTTTTTAGTTATTGTTTTGTTAAGTTGGGTTTTTTGTACCCAATAGCCAACAAGCCGCCTTTATGGCGGTTTTTTTGTGCCTGAAAAGTGGGCGCA + ACGTTAGCAGAATCGCTTTCTGTTCGTTTTCCACCTGCGACAGACGCACCGGACCACGGTTGGCGAGATCGTCGCGCAGAATATCGGCGGCACGCTGCGAC + AGCGTGACAAACATTTTATTGCGCCCGGTTTTATCCAGCTTGAATGCCTGACGAAAGAAGATGATGGTGACGACGATGGAGAGAACAATCAGCACCAGATT + AGCGTCTGACTCACACAAAAACGGTAACACAGTTATCCACAGAATCAGGGGATAAGGCCGGAAAGAACATGTGAGCAAAAAGGCAAAGCCAGGACAAAAGG + bbbeeeeegggggiiiiiiiiiigifhhiiighiiihhiiiiiiihiiiiiiiiiihiigcdbbdcdcccccdccccccccacccccccbcccacccccc
34 What is the data? Fastq ACNGTGTTTTTAGTTATTGTTTTGTTAAGTTGGGTTTTTTGTACCCAATAGCCAACAAGCCGCCTTTATGGCGGTTTTTTTGTGCCTGAAAAGTGGGCGCA + Fastq example: Name field (optional) ACGTTAGCAGAATCGCTTTCTGTTCGTTTTCCACCTGCGACAGACGCACCGGACCACGGTTGGCGAGATCGTCGCGCAGAATATCGGCGGCACGCTGCGAC + AGCGTGACAAACATTTTATTGCGCCCGGTTTTATCCAGCTTGAATGCCTGACGAAAGAAGATGATGGTGACGACGATGGAGAGAACAATCAGCACCAGATT + AGCGTCTGACTCACACAAAAACGGTAACACAGTTATCCACAGAATCAGGGGATAAGGCCGGAAAGAACATGTGAGCAAAAAGGCAAAGCCAGGACAAAAGG + bbbeeeeegggggiiiiiiiiiigifhhiiighiiihhiiiiiiihiiiiiiiiiihiigcdbbdcdcccccdccccccccacccccccbcccacccccc
35 What is the data? Fastq ACNGTGTTTTTAGTTATTGTTTTGTTAAGTTGGGTTTTTTGTACCCAATAGCCAACAAGCCGCCTTTATGGCGGTTTTTTTGTGCCTGAAAAGTGGGCGCA + Fastq example: Quality scores (also called PHRED scores) ACGTTAGCAGAATCGCTTTCTGTTCGTTTTCCACCTGCGACAGACGCACCGGACCACGGTTGGCGAGATCGTCGCGCAGAATATCGGCGGCACGCTGCGAC + AGCGTGACAAACATTTTATTGCGCCCGGTTTTATCCAGCTTGAATGCCTGACGAAAGAAGATGATGGTGACGACGATGGAGAGAACAATCAGCACCAGATT + AGCGTCTGACTCACACAAAAACGGTAACACAGTTATCCACAGAATCAGGGGATAAGGCCGGAAAGAACATGTGAGCAAAAAGGCAAAGCCAGGACAAAAGG + bbbeeeeegggggiiiiiiiiiigifhhiiighiiihhiiiiiiihiiiiiiiiiihiigcdbbdcdcccccdccccccccacccccccbcccacccccc


36 Why are quality scores necessary? In a perfect world In our world
37 PHRED (Q) quality scores Encodes the probability of an erroneous call Phred Quality Score (Q) Error probability (P) PHRED quality score, Q = -10 log 10 P Error probability, P = 10 -Q/10 Probability of incorrect base call in % in % in ,9 % Base call accuracy in 10,000 99,99 % in 100,000 99,999 % Example: Base call with Q = 30 has error probability of 10-3 meaning 1 out of 1000 bases called with this quality score would be wrong
38 The PHRED quality scores are written using ASCII encoding Shown here is the Sanger/Phred+33 conversion table currently used by Illumina

39 Data quality assessed via FastQC Great data!
 Great for generating reports on your WGS data Not able to trim the data")
40 Data quality assessed via FastQC Horrible data! FastQC is freely downloadable ( Great for generating reports on your WGS data Not able to trim the data


41 How to perform read trimming using PRINSEQ

42 Recap by multiple choice scratch cards