Jonathan A. Eisen. University of California, Davis
|
|
|
- Charlotte Carter
- 5 years ago
- Views:
Transcription

1 The Now Generation Sequencing: The Now Generation Bodega Bay Applied Phylogenetics Jonathan A. Eisen University of California, Davis
2 Sequencing Technology
3 Key Issues Cost / bp Read length Paired end Ease of feeding Error profiles Barcoding potential
4 Timeline Approaching to NGS Sanger sequencing method by F. Sanger (PNAS,1977, 74: ) 1983 Discovery of DNA structure (Cold Spring Harb. Symp. Quant. Biol. 1953;18:123-31) PCR by K. Mullis (Cold Spring Harb Symp Quant Biol. 1986;51 Pt 1:263-73) Human Genome Project (Nature, 2001, 409: ; Science, 2001, 291: ) 1993 Single molecule emulsion PCR 1998 Development of pyrosequencing (Anal. Biochem., 1993, 208: ; Science,1998, 281: ) Founded Solexa 1998 Founded 454 Life Science 2000 From Slideshare presentation of Cosentino Cristian GS20 sequencer (First NGS sequencer) 2005 Solexa Genome Analyzer (First short-read NGS sequencer) Illumina acquires Solexa (Illumina enters the NGS business) ABI SOLiD (Short-read sequencer based upon ligation) Roche acquires 454 Life Sciences (Roche enters the NGS business) GS FLX sequencer (NGS with bp read lenght) NGS Human Genome sequencing (First Human Genome sequencing based upon NGS technology) Hi-Seq2000 (200Gbp per Flow Cell) 2010
5 Timeline Approaching to NGS Sanger sequencing method by F. Sanger (PNAS,1977, 74: ) 1983 Discovery of DNA structure (Cold Spring Harb. Symp. Quant. Biol. 1953;18:123-31) PCR by K. Mullis (Cold Spring Harb Symp Quant Biol. 1986;51 Pt 1:263-73) Human Genome Project (Nature, 2001, 409: ; Science, 2001, 291: ) 1993 Single molecule emulsion PCR 1998 Development of pyrosequencing (Anal. Biochem., 1993, 208: ; Science,1998, 281: ) Founded Solexa 1998 Founded 454 Life Science 2000 From Slideshare presentation of Cosentino Cristian GS20 sequencer (First NGS sequencer) 2005 Solexa Genome Analyzer (First short-read NGS sequencer) Illumina acquires Solexa (Illumina enters the NGS business) ABI SOLiD (Short-read sequencer based upon ligation) Roche acquires 454 Life Sciences (Roche enters the NGS business) GS FLX sequencer (NGS with bp read lenght) NGS Human Genome sequencing (First Human Genome sequencing based upon NGS technology) Hi-Seq2000 (200Gbp per Flow Cell) 2010 Miseq Roche Jr Ion Torrent PacBio Oxford

6 Generation I: Manual Sanger


7 Generation II: Automation



8 Automation 2
9 Automated Sanger Highlights 1991: ESTs by Venter 1995: Haemophilus influenzae genome 1996: Yeast, archaea 1999: Drosophila genome 2000: Arabidopsis genome 2000: Human genome 2004: Shotgun metagenomics




10 Generation III: Clusters not clones
11 Next-Generation DNA Sequencing Methods Elaine R. Mardis Departments of Genetics and Molecular Microbiology and Genome Sequencing Center, Washington University School of Medicine, St. Louis MO 63108; Annu. Rev. Genomics Hum. Genet : First published online as a Review in Advance
12 From Slideshare presentation of Cosentino Cristian high-throughput-equencing Isolation and purification of target DNA Sample preparation Library validation Amplification Cluster generation on solid-phase Emulsion PCR Sequencing Sequencing by synthesis with 3 -blocked reversible terminators Pyrosequencing Sequencing by ligation Imaging Four colour imaging Data analysis Illumina GAII Roche 454 ABi SOLiD
13 454
14 454 From Slideshare presentation of Cosentino Cristian
15 Roche 454 From Slideshare presentation of Cosentino Cristian
16 454 -> Roche 1st Next-generation sequencing system to become commercially available, in 2004 Uses pyrosequencing Polymerase incorporates nucleotide Pyrophosphate released Eventually light from luciferase released Three main steps in 454 method Library prep Emulsion PCR Sequencing
17
18 454 Step1: Library Prep a DNA library preparation 4.5 hours Ligation B A Genome fragmented by nebulization A B Selection (isolate AB fragments only) A B No cloning; no colony picking sstdna library created with adaptors A/B fragments selected using avidin-biotin purification gdna sstdna library gdna fragmented by nebulization or sonication Fragments are endrepaired and ligated to adaptors containing universal priming sites Fragments are denatured and AB ssdna are selected by avidin/biotin purification (ssdna library) From Mardis Annual Rev. Genetics 9: 387.
19 454 Step 2: Emulsion PCR b Emulsion PCR 8 hours Anneal sstdna to an excess of DNA capture beads Emulsify beads and PCR reagents in water-in-oil microreactors Clonal amplification occurs inside microreactors Break microreactors and enrich for DNA-positive beads sstdna library Bead-amplified sstdna library From Mardis Annual Rev. Genetics 9: 387.
20 454 Step 3: Sequencing c Sequencing 7.5 hours Well diameter: average of 44 µm 400,000 reads obtained in parallel A single cloned amplified sstdna bead is deposited per well Amplified sstdna library beads Quality filtered bases From Mardis Annual Rev. Genetics 9: 387.




21 454 Step 3: Sequencing Annu. Rev. Genomics Hum. Genet., 2008, 9: Nature Reviews genetics, 2010, 11: µm Pyrosequecning From Slideshare presentation of Cosentino Cristian Reads are recorded as flowgrams
22 454 Key Issues Number of repeated nucleotides estimated by amount of light... many errors Reasonable number of failures in EM- PCR and other steps Systems GS20 FLX FLX Titanium FLX Titanium XL Junior
23

24
25
26 Solexa
27 Solexa From Slideshare presentation of Cosentino Cristian

28 Illumina From Slideshare presentation of Cosentino Cristian
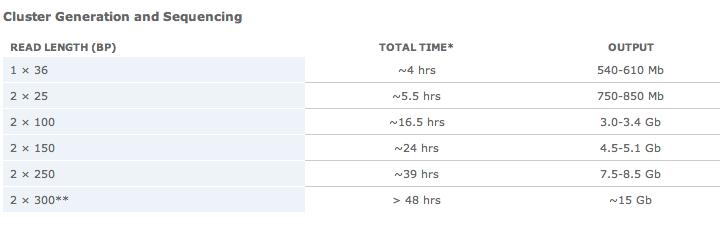
29 Illumina Sequencing by synthesis 1st system released in 2006 by Solexa Acquired by Illumina in 2007 Systems GA GAII HiSeqs HiScan MiSeq


30 Illumina Outline Sample preparation and library validation Cluster generation Cluster station Wash cluster station Clusters amplification Linearization, Blocking and primer Hybridization From Slideshare presentation of Cosentino Cristian cosentia/highthroughput-equencing SBS sequencing Analysis GAIIx & PE Read 1 Prepare read 2 Read 2 Pipeline base call Data analysis


31 Illumina Flow Cell From Slideshare presentation of Cosentino Cristian cosentia/highthroughput-equencing

32 Illumina Prep Flow cell prep: Coat flow cell with primers for bridge PCR DNA prep Fragment DNA to size of interest Add adapters to DNA of interest Clean up fragments
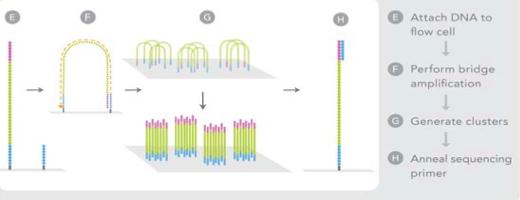
33 Illumina Step 1: Attach DNA a Adapter DNA DNA fragment Dense lawn of primers Adapter Adapters Prepare genomic DNA sample Randomly fragment genomic DNA and ligate adapters to both ends of the fragments. Attach DNA to surface Bind single-stranded fragments randomly to the inside surface of the flow cell channels. From Mardis Annual Rev. Genetics 9: 387. The Illumina sequencing-by-synthesis Nucleotides approach. Cluster strands created by bridge amplification are primed and all four fluorescently labeled, 3 -OH blocked nucleotides are added to the flow cell with DNA polymerase. The cluster strands are extended by one nucleotide. Following the incorporation step, the unused nucleotides and DNA polymerase molecules are washed away, a scan buffer is added to the flow cell, and the optics system scans each lane of the flow cell by imaging units called tiles. Once imaging is completed, chemicals that effect cleavage of the fluorescent labels and the 3 -OH blocking groups are added to the flow cell, which Attached prepares the cluster strands for another round of fluorescent nucleotide incorporation
34 Prepare genomic DNA sample Randomly fragment genomic DNA and ligate adapters to both ends of Attach DNA to surface Bind single-stranded fragments randomly to the inside surface of the flow cell channels. Illumina Step 2: Bridge PCR the fragments. Nucleotides Attached Bridge amplification Add unlabeled nucleotides and enzyme to initiate solidphase bridge amplification. Denature the double stranded molecules Figure 2 The The Illumina Illumina sequencing-by-synthesis sequencing-by-synthesis approach. approach. Cluster strands Cluster created strands by bridge created amplification by bridge are primed amplification and all four are fluorescently primed and labeled, all four 3 -OH fluorescently blocked nucleotides labeled, are added 3 -OH toblocked the flow cell nucleotides with DNA polymerase. are added The to cluster the flow strands cell are with extended DNA by polymerase. one The nucleotide. cluster Following strands are the incorporation extended by step, one thenucleotide. unused nucleotides Following and DNA the polymerase incorporation molecules step, arethe washed unused away, anucleotides scan buffer is and added DNA to the polymerase flow cell, andmolecules the optics system are washed scans eachaway, lane ofa the scan flow buffer cell by imaging is added units to called the flow tiles. Once cell, imaging and the isoptics completed, chemicals that effect cleavage of the fluorescent labels and the 3 system scans each lane of the flow cell by imaging units -OH blocking groups are added to the flow cell, which prepares the called tiles. Once imaging is completed, chemicals cluster strands for another round of fluorescent nucleotide incorporation. that effect cleavage of the fluorescent labels and the 3 -OH blocking groups are added to the flow cell, which prepares the cluster strands for another round of fluorescent nucleotide incorporation 392 Mardis From Mardis Annual Rev. Genetics 9: 387.
35

36 Illumina Step 3: Sequencing b First chemistry cycle: determine first base To initiate the first sequencing cycle, add all four labeled reversible terminators, primers, and DNA polymerase enzyme to the flow cell. Image of first chemistry cycle After laser excitation, capture the image of emitted fluorescence from each cluster on the flow cell. Record the identity of the first base for each cluster. Before initiating the next chemistry cycle The blocked 3' terminus and the fluorophore from each incorporated base are removed. Laser From Mardis Annual Rev. Genetics 9: 387.
37 Illumina SBS From Slideshare presentation of Cosentino Cristian cosentia/highthroughput-equencing
38 HiSeq 2500/1500 From Illumina Web Site
39 MiSeq From Illumina Web Site
40
41

42
43
44
45 ABI Solid

46 ABI Solid From Slideshare presentation of Cosentino Cristian cosentia/highthroughput-equencing
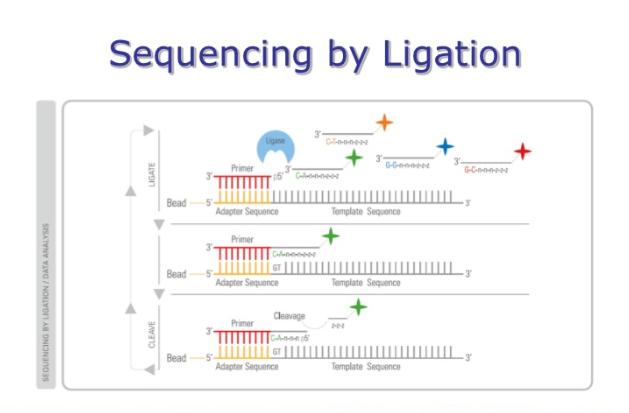
47 a SOLiD substrate 1 μm bead 1. Prime and ligate Universal seq primer (n) 3' 1 μm bead P1 adapter 2. Image 5' P1 adapter Template sequence Primer round 1 4. Cleave off fluor TA P OH A T TA 3. Cap unextended strands Cleavage agent AT TA Glass slide Excite PO 4 P + Ligase Template sequence Phosphatase HO Fluorescence 3' 3' 3' 3' 3' ABI Solid Details Di base probes 3'TTnnnzzz5' 3'TGnnnzzz5' 3'TCnnnzzz5' 3'TAnnnzzz5' Cleavage site Template 2nd base A C G T A C 5. Repeat steps 1 4 to extend sequence Ligation cycle (n cycles) 6. Primer reset A T T A T T A A C T G A Universal seq primer (n 1) 3' 2. Primer reset 1 μm bead 7. Repeat steps 1 5 with new primer Primer round 2 1 Universal seq primer (n 1) A A 3' 1 μm bead T C A GT CG GC G T G T C A 1 base shift T C 1st base T T A A 1. Melt off extended sequence A A A G TT C A G T T A A T G C C G 3' From Mardis Annual Rev. Genetics 9: 387. C C G G 3' 3' The ligase-mediated sequencing approach of the Applied Biosystems SOLiD sequencer. In a manner similar to Roche/454 emulsion PCR amplification, DNA fragments for SOLiD sequencing are amplified on the surfaces of 1- μm magnetic beads to provide sufficient signal during the sequencing reactions, and are then deposited onto a flow cell slide. Ligasemediated sequencing begins by annealing a primer to the shared adapter sequences on each amplified fragment, and then DNA ligase is provided along with specific fluorescentlabeled 8mers, whose 4th and 5th bases are encoded by the attached fluorescent group. Each ligation step is followed by fluorescence detection, after which a regeneration step removes bases from the ligated 8mer (including the fluorescent group) and concomitantly prepares the extended primer for another round of ligation. (b) Principles of two-base encoding. Because each fluorescent group on a ligated 8mer identifies a two-base combination, the resulting sequence reads can be screened for base-calling errors versus true polymorphisms versus single base deletions by aligning the individual reads to a known high-quality reference sequence.

48
49

50
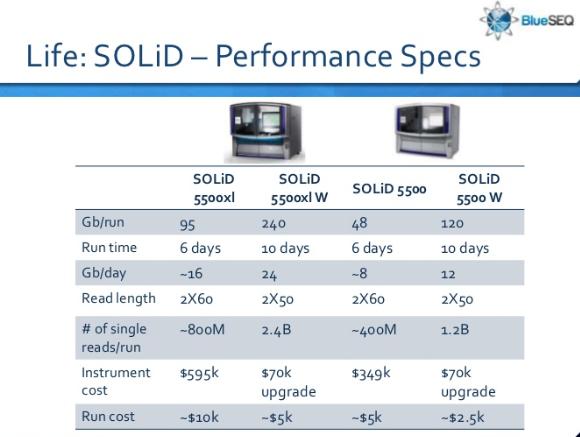
51

52
53
54 Comparison From Slideshare presentation of Cosentino Cristian
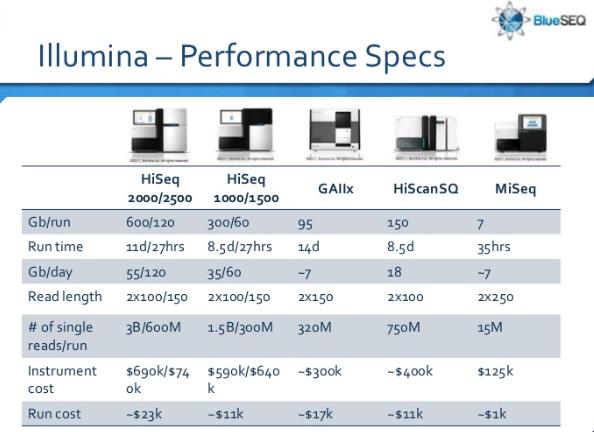
55 Comparison in 2008 Sequencing Amplif. Chemistry Read lenght (bp) Roche 454 GS FLX Titanium empcr Pyrosequencing ABi SOLiD empcr Sequencing by ligation Illumina GAII Solid-phase Reversible terminator * Average Run time (d) 0.35 * Gbp/ day DNA required (μg) $/sequencer (ref. 2008) From Slideshare presentation of Cosentino Cristian
56 Comparison in 2008 Sequencing Advantages Disadvantages $/Mbp (in 2008)* Roche 454 ABi SOLiD Long reads even > 400 bp, improving de novo sequencing Rare sustitution errors Error correction with the two-base encoding system Illumina GAII Most widely used platform (> 90 science/nature publication) Sample preparation automatable SBS, real-time analysis and base calling are performed simultaneously to the run Automated cluster generation *Nat. Biotech., 2008, 26: High indel in homopolymer stretches > 6 nucl. High reagent cost Longest reads only in singleread (2x150 bp) Long time run Needs of cluster station to perform base calling and up to 1 week to align Alignment must be performed against a reference db Low multiplexing capability Substitution errors From Slideshare presentation of Cosentino Cristian
57 Comparison in 2008 Roche (454) Illumina SOLiD Chemistry Pyrosequencing Polymerase-based Ligation-based Amplification Emulsion PCR Bridge Amp Emulsion PCR Paired ends/sep Yes/3kb Yes/200 bp Yes/3 kb Mb/run 100 Mb 1300 Mb 3000 Mb Time/run 7 h 4 days 5 days Read length 250 bp bp 35 bp Cost per run $8439 $8950 $17447 (total) Cost per Mb $84.39 $5.97 $5.81 From Introduction to Next Generation Sequencing by Stefan Bekiranov prometheus.cshl.org/twiki/pub/main/ CdAtA08/CSHL_nextgen.ppt
58 Comparison in 2012 Roche (454) Illumina SOLiD Chemistry Pyrosequencing Polymerase-based Ligation-based Amplification Emulsion PCR Bridge Amp Emulsion PCR Paired ends/sep Yes/3kb Yes/200 bp Yes/3 kb Mb/run 100 Mb 1300 Mb 3000 Mb Time/run 7 h 4 days 5 days Read length 250 bp bp 35 bp Cost per run $8439 $8950 $17447 (total) Cost per Mb $84.39 $5.97 $5.81 From Introduction to Next Generation Sequencing by Stefan Bekiranov prometheus.cshl.org/twiki/pub/main/ CdAtA08/CSHL_nextgen.ppt
59 Bells and Whistles Multiplexing Paired end Mate pair????
60 Multiplexing
61 Small amounts of DNA

62 Capture Methods RainDance Microdroplet PCR Roche Nimblegen Salid-phase capture with customdesigned oligonucleotide microarray Reported 84% of capture efficiency From Slideshare presentation of Cosentino Cristian Reported 65-90% of capture efficiency

63 Agilent SureSelect Solution-phase capture with streptavidin-coated magnetic beads Reported 60-80% of capture efficiency From Slideshare presentation of Cosentino Cristian high-throughput-equencing
64 Moleculo
65 DNA Moleculo
66 DNA Moleculo Large fragments
67 DNA Moleculo Large fragments
68 DNA Moleculo Large fragments Isolate and amplify
69 DNA Moleculo Large fragments Isolate and amplify
70 DNA Moleculo Large fragments Isolate and amplify Sublibrary w/ unique barcodes
71 DNA Moleculo Large fragments Isolate and amplify Sublibrary w/ unique barcodes CACC GGAA TCTC ACGT AAGG GATC AAAA
72 DNA Moleculo Large fragments Isolate and amplify Sublibrary w/ unique barcodes CACC GGAA TCTC ACGT AAGG GATC AAAA Sequence w/ Illumina
73 DNA Moleculo Large fragments Isolate and amplify Sublibrary w/ unique barcodes CACC GGAA TCTC ACGT AAGG GATC AAAA Sequence w/ Illumina
74 DNA Moleculo Large fragments Isolate and amplify Sublibrary w/ unique barcodes CACC GGAA TCTC ACGT AAGG GATC AAAA Sequence w/ Illumina
75 DNA Moleculo Large fragments Isolate and amplify Sublibrary w/ unique barcodes CACC GGAA TCTC ACGT AAGG GATC AAAA Sequence w/ Illumina Assemble seqs w/ same codes
76 DNA Moleculo Large fragments Isolate and amplify Sublibrary w/ unique barcodes CACC GGAA TCTC ACGT AAGG GATC AAAA Sequence w/ Illumina Assemble seqs w/ same codes
77 Generation 3.5 Even faster
78 Ion Torrent PGM
79 Ion Torrent PGM
80 Applied Biosystems Ion Torrent PGM

81 Applied Biosystems Ion Torrent PGM Workflow similar to that for Roche/454 systems. Not surprising, since invented by people from 454.
82 Applied Biosystems Ion Torrent PGM

83 Ion Torrent Figure4. Layout of IonTorrent s semiconductor sequencing chip technology.(a)a layer-bylayer view of the chip revealing the structural design. The top layer contains the individual DNA polymerization reaction wells, and the bottom two layers comprise the FET ion sensor. Each well has a corresponding FET detector that identifies a change in ph. (B) A side view of an individual reaction well depicting DNA polymerase incorporation of a repeat of two TTP nucleotides on a sequencing fragment. The hydrogen ions released during this process are detected by the FET below. Reprinted with permission from Ion Torrent (Wes Conrad). From Niedringhaus et al. Analytical Chemistry 83:

84
85

86
87 Generation IV?? Single molecule sequencing
88 Pacific Biosciences

89 Pacific Biosciences
 The side view of a single ZMW nanostructure containing a single DNA polymerase (Φ29) bound to the bottom glass surface.")
90 Pacific Biosciences Figure 2. Schematic of PacBio s real-time single molecule sequencing. (A) The side view of a single ZMW nanostructure containing a single DNA polymerase (Φ29) bound to the bottom glass surface. The ZMW and the confocal imaging system allow fluorescence detection only at the bottom surface of each ZMW. (B) Representation of fluorescently labeled nucleotide substrate incorporation on to a sequencing template. The corresponding temporal fluorescence detection with respect to each of the five incorporation steps is shown below. From Niedringhaus et al. Analytical Chemistry 83:
91
92 Complete Genomics
93 Complete Genomics REVIEW Figure 3. Schematic of Complete Genomics DNB array generation and cpal technology. (A) Design of sequencing fragments, subsequent DNB synthesis, and dimensions of the patterned nanoarray used to localize DNBs illustrate the DNB array formation. (B) Illustration of sequencing with a set of common probes corresponding to 5 bases from the distinct adapter site. Both standard and extended anchor schemes are shown. omplete Genomics DNB array generation and cpal technology. (A) Design of sequencing fragments, subsequent DNB f the patterned nanoarray used to localize DNBs illustrate the DNB array formation. (B) Illustration of sequencing with a set onding to 5 bases from the distinct adapter site. Both standard and extended anchor schemes are shown. Reprinted with pyright XXXX American Association for the Advancement of Science. gure 3. Schematic of Complete DNB array generation and cpal technology. (A) Design sequencing fragments, subsequent DN FromGenomics Niedringhaus et al. Analytical Chemistry 83:of ased the number of false positive gene sitosterolemia phenotype determined comparison of nthesis, and dimensions of the patterned nanoarray used towere localize DNBsafter illustrate the DNB array formation. (B) Illustration of sequencing with a ely reduced the number gene candidates the patient s genome to a collection of reference genomes. common probes corresponding to 5Ultimately, bases from the distinctthat adapter site.failed Boththestandard it was determined the patient standard and extended anchor schemes are shown. Reprinted w Monday, March 4, 13 rmission from refpublished 50. Copyright Association forsterols the Advancement ofofscience. the second externally applica- XXXX bloodamerican test due to low levels of plant that were the result
94 Oxford Nanopore
95 Oxford Nanopore This diagram shows a protein nanopore set in an electrically resistant membrane bilayer. An ionic current is passed through the nanopore by setting a voltage across this membrane. If an analyte passes through the pore or near its aperture, this event creates a characteristic disruption in current. By measuring that current it is possible to identify the molecule in question. For example, this system can be used to distinguish the four standard DNA bases and G, A, T and C, and also modified bases. It can be used to identify target proteins, small molecules, or to gain rich molecular information for example to distinguish the enantiomers of ibuprofen or molecular binding dynamics. From Oxford Nanopores Web Site
SchematicofRHLproteinnanoporemutantdepictingthepositionsofthe cyclodextrin (at residue 135) and glutamines (at residue 139).")
96 Oxford Nanopore Figure6. BiologicalnanoporeschemeemployedbyOxfordNanopore. (A)SchematicofRHLproteinnanoporemutantdepictingthepositionsofthe cyclodextrin (at residue 135) and glutamines (at residue 139). (B) A detailed view of the β barrel of the mutant nanopore shows the locations of the arginines (at residue 113) and the cysteines. (C) Exonuclease sequencing: A processive enzyme is attached to the top of the nanopore to cleave single nucleotides from the target DNA strand and pass them through the nanopore. (D) A residual current-vs-time signal trace from an RHL protein nanopore that shows a clear discrimination between single bases (dgmp, dtmp, damp, and dcmp). (E) Strand sequencing: ssdna is threaded through a protein nanopore and individual bases are identified, as the strand remains intact. Panels A, B, and D reprinted with permission from ref 91. Copyright 2009 Nature Publishing Group. Panels C and E reprinted with permission from Oxford Nanopore Technologies (Zoe McDougall). Figure6. BiologicalnanoporeschemeemployedbyOxfordNanopore.(A)SchematicofRHLproteinnanoporemutantdepictingthepositionsofthe cyclodextrin (at residue 135) and glutamines (at residue 139). (B) A detailed view of the β barrel of the mutant nanopore shows the locations of the arginines (at residue 113) and the cysteines. (C) Exonuclease sequencing: A processive enzyme is attached to the top of the nanopore to cleave single nucleotides from the target DNA strand and pass them through the nanopore. (D) A residual current-vs-time signal trace from an RHL protein nanopore that shows a clear discrimination between single bases (dgmp, dtmp, damp, and dcmp). (E) Strand sequencing: ssdna is threaded through a protein nanopore and individual bases ar identified, as the strand remains intact. Panels A, B, and D reprinted with permission from ref 91. Copyright 2009 Nature Publishing Group. Panels C and E reprinted with permission from Oxford Nanopore Technologies (Zoe McDougall). From Niedringhaus et al. Analytical Chemistry 83:
97 Nanopores Nanopore DNA sequencing using electronic measurements and optical readout as detection methods.(a)in electronic nanopo schemes, signal is obtained through ionic current, 73 tunneling current, and voltage difference measurements. Each method must produce a characteristic signal to differentiate the four DNA bases. (B) In the optical readout nanopore design, each nucleotide is converted to a preset oligonucleotide sequence and hybridized with labeled markers that are detected during translocation of the DNA fragment through the nanopore. From Niedringhaus et al. Analytical Chemistry 83:

98 Oxford Nanopore From Oxford Nanopores Web Site

99