Transforming Analytics with Cloudera Data Science WorkBench
|
|
|
- Allyson Skinner
- 5 years ago
- Views:
Transcription
1 Transforming Analytics with Cloudera Data Science WorkBench Process data, develop and serve predictive models. 1
2 Age of Machine Learning Data volume NO Machine Learning Machine Learning 1950s 1960s 1970s 1980s 1990s 2000s 2010s Cost of compute Time 2 2
3 Our current platform PROCESS, ANALYZE, SERVE BATCH Spark, Hive, Pig MapReduce STREAM Spark SQL Impala SEARCH Solr OTHER Kite UNIFIED SERVICES OPERATIONS Cloudera Manager Cloudera Director RESOURCE MANAGEMENT YARN FILESYSTEM HDFS RELATIONAL Kudu NoSQL HBase SECURITY Sentry, RecordService OTHER Object Store DATA MANAGEMENT Cloudera Navigator Encrypt and KeyTrustee Optimizer STORE STRUCTURED Sqoop UNSTRUCTURED Kafka, Flume INTEGRATE 3
4 Apache Spark De facto Data Processing and Modern Analytic Engine 4



5 Apache Spark Fast and flexible general purpose data processing for Hadoop Data Engineering Stream Processing Data Science & Machine Learning Unified API and processing Engine for large scale data 5
6 Spark Addresses Common Limitations Access and Usability One of the key advantages of Apache Spark is the intuitive and flexible API for big-data processing, available in popular programming languages. Prior to Apache Spark, users had access to very limited inflexible abstractions for processing large distributed data, with poor support outside Java. Data Processing Performance MapReduce made big strides in enabling cost effective batch processing of large volumes of data. However businesses continue to see a need to shorten data processing windows and consume data faster, requiring a new framework with significantly better performance. Machine Learning at Scale Data Science and Machine Learning on big-data are exciting areas of focus. However that requires libraries and that enable building models on large distributed data and APIs that allow flexible exploration of data. 6

7 Apache Spark Apache Spark is at the core of our data science experience Libraries for common machine learning Trusted in production by our customers Delivered with expert support and training A requirement for our Data Science Workbench Apache Spark is a huge driver for machine learning Native language development tools Reliable operation at big data scale Native access to Hadoop data for testing and training Spark 2.1 is here Separate parcel for easy implementation for multiple Spark instances Better Streaming Performance Machine Learning Persistence 7
8 Machine Learning 8
9 Machine Learning on Hadoop Data Engineering Data Science Data Engineering Raw Data - many sources - many formats - varying validity cleaning merging filtering Well-formated data Training, validation, and test data model building model training hyper-param tuning Validated ML Models pipeline execution production operation End User Consumption for analysis ongoing data ingestion 9
 Train of CDH (Spark ML) Deliver on transactional systems Build on CDH (Workbench) Train on CDH (Spark ML) Deliver on CDH (Hbase/Kudu/Spark Streaming)")
10 Machine Learning Deployment Patterns Train Build and Train Build, Train, and Serve Build in Notebooks Train on CDH (Spark ML) Deliver on transactional systems or run batch Build on CDH (Workbench) Train of CDH (Spark ML) Deliver on transactional systems Build on CDH (Workbench) Train on CDH (Spark ML) Deliver on CDH (Hbase/Kudu/Spark Streaming) 10
11 Apache Spark MLlib Collection of mainstream machine learning algorithms built on Spark Including: Classifiers: logistic regression, boosted trees, random forests, etc Clustering: k-means, Latent Dirichlet Allocation (LDA) Recommender Systems: Alternating Least Squares Dimensionality Reduction: Principal Component Analysis (PCA) and Singular Value Decomposition (SVD) Feature Engineering & Selection: TF-IDF, Word2Vec, Normalizer, etc Statistical Functions: Chi-Squared Test, Pearson Correlation, etc 11
12 Cloudera Data Science Self-Service Data Science for the Enterprise 12
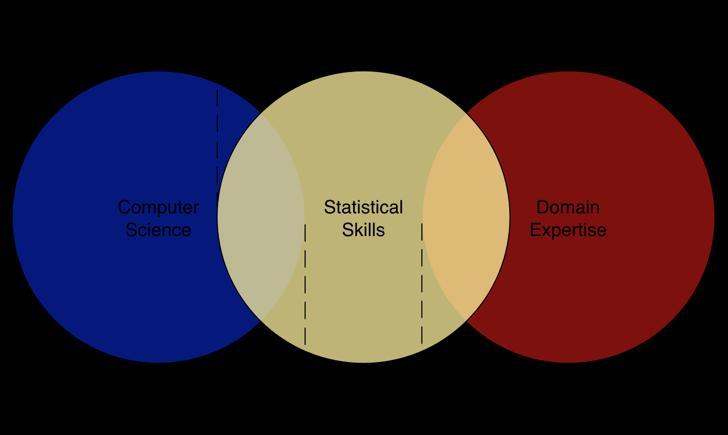
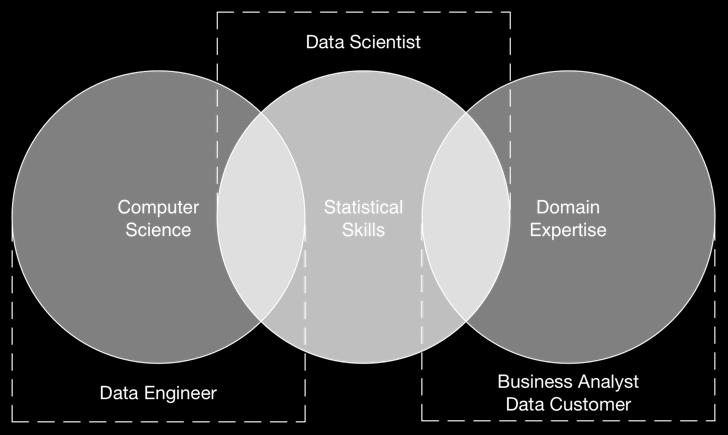
13 Types of data science Exploratory (discover and quantify opportunities) Operational (deploy production systems) Team: Data scientists and analysts Goal: Understand data, develop and improve models, share insights Data: New and changing; often sampled Environment: Local machine, sandbox cluster Tools: R, Python, SAS/SPSS, SQL; notebooks; data wrangling/discovery tools, End State: Reports, dashboards, PDF, MS Office Team: Data engineers, developers, SREs Goal: Build and maintain applications, improve model performance, manage models in production Data: Known data; full scale Environment: Production clusters Tools: Java/Scala, C++; IDEs; continuous integration, source control, End State: Online/production applications 13
14 14
15 Common Limitations Access Many times secured clusters are hard for data science professionals to connect either because they don t have the right permissions or resources are to scarce to afford them access. In addition popular frameworks and libraries don t read Hadoop data formats out-of-the-box. Scale Notebook environments seldom have large enough data storage for medium, let alone big data. Data scientists are often relegated to sample data and constrained when working on distributed systems. Popular frameworks and libraries don t easily parallelize across the cluster. Developer Experience Popular notebooks don t work well with access engines like Spark and package deployment and dependency management across multiple software versions is often hard to manage. Then once a model is built there is no easy path from model development to production 15




16 Open data science in the enterprise Data Scientist explore, experiment, iterate IT drive adoption while maintaining compliance 16
17 17
18 Solving Data Science is a Full-Stack Problem Leverage Big Data Enable real-time use cases Provide sufficient toolset for the Data Analysts Provide sufficient toolset for the Data Scientists + Data Engineers Provide standard data governance capabilities Provide standard security across the stack Provide flexible deployment options Integrate with partner tools Provide management tools that make it easy for IT to deploy/maintain Hadoop Kafka, Spark Streaming Spark, Hive, Hue Data Science Workbench (beta) Navigator + Partners Kerberos, Sentry, Record Service, KMS/KTS Cloudera Director Rich Ecosystem Cloudera Manager/Director 18
19 Data Science Workbench Self-service data science for the enterprise 19
20 Introducing Cloudera Data Science Workbench Self-service data science for the enterprise Accelerates data science from development to production with: Secure self-service environments for data scientists to work against Cloudera clusters Support for Python, R, and Scala, plus project dependency isolation for multiple library versions Workflow automation, version control, collaboration and sharing 20
21 Key Benefits How is Cloudera Data Science different? Works with fully secured clusters One tool for multiple languages (Python, R, Scala) Multi-tenant Architecture Common Platform 21
22 Cloudera Manager Session A Session B Ingestion Flume/Sqoop/ Kafka Analytics Hive/Impala/S park/search ML spark.mllib Deep Learning Frameworks Session N HDFS Security, Lineage and Governance 22
23 How does CDSW help! Multiple Users Configurable Sessions Extensible Engines Retrain and redeploy Change and Compile Source code Visualize results Trivial to tweak parameters Roles/Governance CDH 23
24 Thank You 24