SE350: Operating Systems. Lecture 6: Scheduling
|
|
|
- Aldous West
- 5 years ago
- Views:
Transcription
1 SE350: Operating Systems Lecture 6: Scheduling
2 Main Points Definitions Response time, throughput, scheduling policy, Uniprocessor policies FIFO, SJF, Round Robin, Multiprocessor policies Scheduling sequential application Scheduling multithreaded applications
3 Definitions Task/Job User request: e.g., mouse click, web request, shell command, Latency/response time How long does a task take to complete? Throughput How many tasks can be done per unit of time? Overhead How much extra work is done by the scheduler?
4 Definitions (cont.) Fairness How equal is the performance received by different users? Predictability How consistent is the performance over time? Workload Set of tasks for system to perform Preemptive scheduler If we can take resources away from a running task
5 Definitions (cont.) Work-conserving Resource is used whenever there is a task to run For non-preemptive schedulers, work-conserving is not always better Scheduling algorithm Takes a workload as input Decides which tasks to do first Performance metric (throughput, latency) as output Only preemptive, work-conserving schedulers to be considered
6 Important Notes Minimizing Average Response Time (ART) may lead to more context switching which hurts throughput Maximizing throughput has two parts Minimizing overhead (e.g., context switching) Utilizing system resources (e.g., CPU, disk, memory) Minimizing ART could make system less fair Delaying some tasks to make others faster
7 Main Points Definitions Response time, throughput, scheduling policy, Uniprocessor policies FIFO, SJF, Round Robin, Multiprocessor policies Scheduling sequential application Scheduling multithreaded applications
8 First In First Out (FIFO) Schedule tasks in the order they arrive Run them until they complete or yield the processor E.g., a supermarket line On what workloads is FIFO particularly bad? Short tasks land in line behind very long tasks FIFO leads to bad ART E.g., getting stuck behind someone with a full cart who insists on paying in pennies On what workloads is FIFO particularly good? All tasks have similar length and similar priority E.g., memcashed, Facebook cache of friend lists,
9 Shortest Job First (SJF) Always run the task that has the shortest remaining amount of work to do Often called Shortest Remaining Time First (SRTF) Requires knowledge of the future, usually impractical Right policy for bandwidth-constrained web service Service time could be predicted for static content ART is dominated by (frequent) requests to short pages Bandwidth costs are dominated by (less frequent) requests to large pages Large requests will be starved if web server is overloaded Requires its own set of solutions
10 FIFO vs. SJF Tasks FIFO (1) (2) (3) (4) (5) Tasks SJF (1) (2) (3) (4) (5) Time SJF runs short tasks first: huge effect on short tasks, negligible effect on long task
11 Questions SJF is optimal policy for minimizing ART! Why? Consider alternative policy P (not SJF) that is optimal Because P is not SJF, at some point it chooses to run a task that is longer than the shortest task in the queue Keep the order of tasks the same, but run the shorter task first reduced ART contradiction! Does SJF have any downsides? Starvation, context switches, and variance in response time Some task might take forever! E.g., would it work if a supermarket uses SJF? Customers could game the system: come with one item at a time
12 Starvation and Sample Bias Suppose you want to compare scheduling policies Create some infinite sequence of arriving tasks Start measuring Stop at some point Compute ART for finished tasks between start and stop Is this valid or invalid? SJF and FIFO would complete a different set of tasks Their ARTs are not directly comparable E.g., suppose you stopped at any point in FIFO vs. SJF slide
13 Solutions for Sample Bias For both systems, measure for long enough that # of completed tasks >> # of uncompleted tasks Start and stop system in idle periods Idle period: no work to do If algorithms are work-conserving, both will complete the same tasks
14 Round Robin (RR) Each task runs on the processor for a fixed period of time (time quantum, slice, interval) If a task does not complete, it goes back in line Need to pick a time quantum What if time quantum is too long? Infinite? Approximates FIFO What if time quantum is too short? One instruction? Approximates SJF
15 Round Robin Short vs. Long Time Quantum Tasks Round Robin (1 ms time slice) (1) Rest of Task 1 (2) (3) (4) (5) Tasks (1) Round Robin (100 ms time slice) Rest of Task 1 (2) (3) (4) (5) Time
16 Round Robin vs. FIFO Assuming zero-cost time slice, is Round Robin always better than FIFO for ART? No! For tasks with same size, RR hurts ART
17 Round Robin vs. FIFO and SJF Tasks Round Robin (1 ms time slice) (1) (2) (3) (4) (5) Tasks FIFO and SJF (1) (2) (3) (4) (5) Time Everything is fair, but ART is bad: all threads finish very late! If we are running streaming video, RR results in predictable, stable rate of progress FIFO is optimal in this case SJF maximizes variance, but RR minimizes it
18 Is Round Robin Always Fair? Tasks I/O Bound Issues I/O Request I/O Completes Issues I/O Request I/O Completes CPU Bound CPU Bound Time One iteratively needs I/O, others only need CPU I/O task has to wait its turn for CPU It gets a tiny fraction of the performance it could optimally get Other tasks get almost as much as they would if the I/O task wasn t there Shorter quantum helps, but it increases overhead
19 What is Fairness? FIFO? Equal share of the CPU? What if some tasks don t need their full share? Minimize worst case divergence? Performance if no one else was running Performance under scheduling algorithm
20 Max-Min Fairness (MMF) Maximize the minimum allocation given to a task If any task needs less than an equal share, schedule the smallest of these first Split the remaining time using max-min If all remaining tasks need at least equal share, split evenly Max-min could lead to too many context switches For tasks with same size, run one instruction of each task We can approximate Max-Min by allowing tasks to get ahead of their fair share by one time quantum At the end of each quantum, schedule the task with least accumulated allocation
21 Multi-level Feedback Queue (MFQ) Goals: Responsiveness: run short tasks quickly (like SJF) Low overhead: minimize preemptions (like FIFO) Starvation freedom: make progress on all tasks (like RR) High/low priority: differ maintenance tasks Fairness: Assign max-min fair share to equal priority tasks Not perfect at any of them! Used in Linux (and probably Windows, MacOS)
22 Multi-level Feedback Queue (cont.) MFQ is an extension of Round Robin Instead of one, set of queues each with a separate priority High priority queues have short time slices Low priority queues have long time slices Scheduler picks first thread in highest priority queue Tasks at higher priority levels preempt lower priority tasks Tasks start in highest priority queue If time slice expires, task drops one level Tasks stay at same level if they yield CPU because of I/O Tasks receiving less than their fair share go up one level
23 Multi-level Feedback Queue (cont.) Priority 1 Time Slice (ms) 10 Round Robin Queues New or I/O Bound Task 2 20 Time Slice Expiration
24 Uniprocessor Summary (1) FIFO is simple and minimizes overhead If tasks are variable in size, FIFO can have poor ART If tasks are equal in size, FIFO optimizes ART Considering only the processor, SJF optimizes ART SJF is pessimal in terms of variance in response time If tasks are variable in size, RR approximates SJF If tasks are equal in size, RR will have poor ART Tasks that intermix processor and I/O benefit from SJF and can do poorly under Round Robin
25 Uniprocessor Summary (2) MMF can improve response time for I/O-bound tasks RR and MMF both avoid starvation By manipulating the assignment of tasks to priority queues, an MFQ scheduler can achieve a balance between responsiveness, low overhead, and fairness
26 Main Points Definitions Response time, throughput, scheduling policy, Uniprocessor policies FIFO, SJF, Round Robin, Multiprocessor policies Scheduling sequential application Scheduling multithreaded applications
27 Multiprocessor Scheduling What would happen if we used MFQ on a multiprocessor? Contention for scheduler spinlock Cache slowdown due to ready list data structure pinging from one CPU to another Limited cache reuse: thread s data from last time it ran is often still in its old cache
28 Per-Processor Affinity Scheduling for Sequential Programs Each processor has its own ready list Protected by a per-processor spinlock Put threads back on the ready list where it had most recently run E.g., when I/O completes, or on CV.signal() Idle processors can steal work from other processors Only if queue lengths are persistent enough to compensate for cache reloading for the migrated threads Per-processor data structures must be protected by locks
29 Per-Processor Multi-level Feedback with Affinity Scheduling Processor 1 Processor 2 Processor 3
30 Oblivious Scheduling for Parallel Programs Processor 1 Processor 2 Processor 3 p1.4 p2.1 p1.2 Time p2.3 p3.4 p1.3 p3.1 p2.4 p2.2 px.y = Thread y in process x Each processor time-slices its ready list independently Each thread is treated as a separate entity If program uses locks and CVs, correctness is not affected Performance could be affected A thread could be time-sliced while others from same program are running
31 Bulk Synchronous Parallelism Processor 1 Processor 2 Processor 3 Processor 4 Local Computation Barrier Time Communication Barrier Local Computation At each step, the computation is limited by the slowest processor to complete that step
32 Preemption and Multithreaded Programs Processor 1 Processor 2 Processor 3 Processor 4 Preempting a thread in the middle of the chain can stall all of the processors in the chain More generally, preempting a thread on the critical path, however, will slow down the end result With spin-then-wait, preempting lock holder makes other tasks spin-wait until lock holder is re-scheduled
33 Gang Scheduling Processor 1 p1.1 Processor 2 p1.2 Processor 3 p1.3 Time p2.1 p2.2 p2.3 p3.1 p3.2 p3.3 px.y = Thread y in process x Threads from the same process are scheduled at exactly the same time Threads are time sliced together to provide a chance for other processes to run
34 Space Sharing Processor 1 Processor 2 Processor 3 Processor 4 Processor 5 Processor 6 Time Process 1 Process 2 Each process is assigned a subset of the processors Minimizes processor context switches
35 How Many Processors Does a Process Need? Perfectly Parallel Performance (Inverse Response Time) Diminishing Returns Limited Parallelism There are overheads E.g., creating extra threads, synchronization, communication Overheads shift the curve down Number of Processors
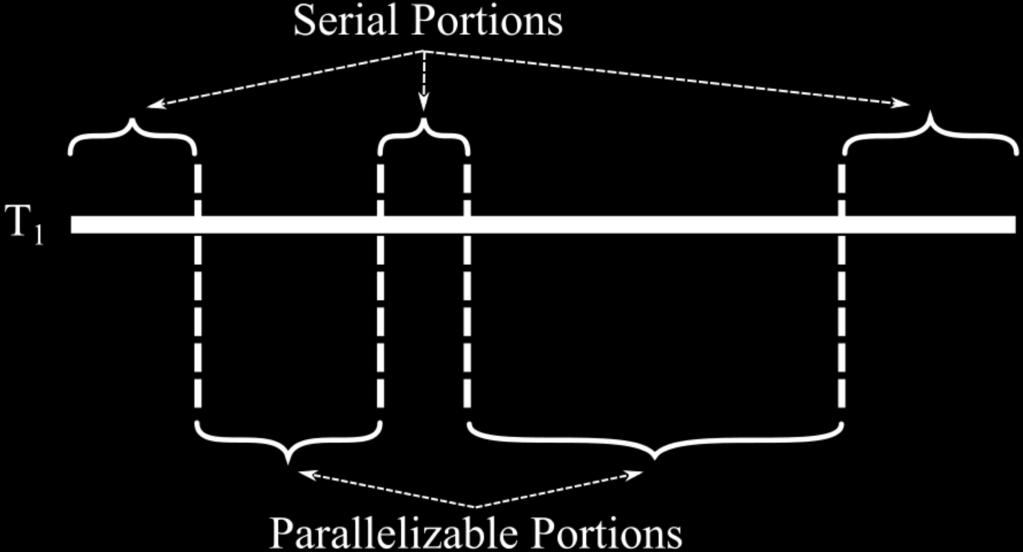

36 <latexit sha1_base64="immsh03zmrhejkmcj1tt4d09r88=">aaacqnicbvbnaxsxej1n0yz13nznjrmimojnqnntpc0hyfiwptrejknt42rl2ure+4e0w9ys+9966r/irx+glx7semgph8prf1indytevhndsm9pldtkuj+dtsfrt59tbd6vbfvfvhxve719yujuc+ylwmx61ocglyywt5iuniyaeegrhpgxn+b9wtfurszrj2yjjkn+fslack5wmts+jagzyo8txgmanljmwq7yknbc5l2jv9grkw7u1q3vxadp2d5c65rivvzzzlyolxudylkruy23bhtivcwptw+rt18bodupxy6msuhdjegobszqcxma51ytfaqlyig1mhbxwc9wagneqztjvmygyg+tmmvbro2jijxq/ymch8bmqt86q07nzru3fx/rdvmkpo5zgsupysqwi4jumyrzpfa2lrofqzklxghp38reobdhki29ykpwvr/8kptft/zb7penow0lbmiuviegepab2vazutahad/hf1zbh+eh89u5dm4w1jvnobmd/8g5+wst4rie</latexit> sha1_base64="xidd0c1tbn8/amshhbbgtogcwxg=">aaacqnicbvdlsgmxfm34tr6qlt0eraiizcanuhckqngpafvss8mkdzq08yc5i1og+qm/wk9x4w+48wfcufarxlkwnsr4opbw7rnncppjrljoto17a2bwahhkdgy8mde5nt1tnj071mgsonr4ken16jinugrqq4estimfzhclnlid3v7/5bkufmfwhn0imj47d4qnoemjtypndyqe08miob1hpwqlo9u04sng06owk5kryba/1svnrbpi2gpfq+zikn15elpkltvq1iou2wu7b/1lne+yvnmzfgmvv9f7rejdox3y2icauwra1x07wmbkfaouiss0yg0r4x12dnvda+adbqz5bhldnkqbeqeyj0caq98nuuzr3fvd4/qzxujfvz74x68eo7fzteuqxqgb7y/yykkxpl1aavso4ci7hjcuhhkr5rfmhiem9oijwfn95b+ktl7ektshjowk6womljbfuiio2savskf2sy1wckmeybn5tm6tr+vfeu1bb6zpmxnya9b7b+zjtdw=</latexit> Amdahl s Law (G. Amdahl 1967) Estimates upper bounds on speedups Speedup(x) = T 1 T x = T 1 (1 F )T 1 + FT 1 x = x x(1 F )+F


37 <latexit sha1_base64="f9zvgm5q2uujumfw66uwofcxkic=">aaacaxicbvdlsgnbeoynrxhfuu+ih8egjihh14t6uakb4dgcawljemyns8mq2qczs5kwbc/+ihcpkl79c2/e/bqnj4mmfjquvd10d7krz1kz5perwlhcwl5jr2bw1jc2t7lbo3cyjawhngl5kooulpszgnqkku7rkadydzmtub3yyk/duyfzgnyqquqdh3cc5jgclzza2t2z7xfqjwp6apokp0z6eeukujiudfvznfk0x0dzxjqsxonqopwnanvw9rpzdkns00arjqvswgaknaqlxqinw0wzljtcpic7tkfpgh0qnwt8whadaawnvfdochqaq78neuxlofbd3elj1zwz3kj8z2veyjt3ehzesaibmszyyo5uiez5odytlcg+0aqtwfstihsxdkpp1di6bgv25xlinxyviuandqmee6rhhw4hdxacqqmuoqo2ehiaj3ibv+predbejpdja8qyzuzchxgfp08slyy=</latexit> sha1_base64="1dlfmwgm00v+igotyomlaizgrte=">aaacaxicbvdlssnafj34rpuvdswkdbahrsxjn+pckrskywrwftpqj9njo3qyctmtaqnbjb/ixowkw//cnr/gfzh9llt1wixdofdy7z1uykhulvvlzm0vlc4tp1bsq2vrg5vm1vatdckbsruhlbb1f0nckcdvrruj9vaq5lum1nxeaejx7omqnoa3ahasx0cdtj2kkdjsy9yv2x4oxscmjxco+0ncz9on5dxxowmzgstvjqbnit0hmellfum7chbxazmfzxaai59whrmssmfboxjijbtfjctpzirjihapduhdu458ip149eicj7tshl4gdhefr+rvirj5ug58v3f6shxltdcu//makflonjjymfke4/eil2jqbxcyb2xtqbbia00qfltfcnex6tcuti2tq7cnx54l1ul+pg9d6zckyiwu2aohiatscaqk4apuqbvg8acewat4nr6nz+pneb+3zhmtmr3wb8bhd0awl9s=</latexit> <latexit sha1_base64="qqhte3ffpwsvixuju0fqbhig71i=">aaacjnicbzdjsgnbeizrxgpcoh69nayhorhmvkghjscixwhghuwipz2eplfnobtgdeoewzfw4lt49ik4in58fdubagjbw8//vvfdvxdlodg2p62p6znzufnmqnzxaxllnbe2fqgjrdfezzgm1jvhnzci5fuukplvrdgnpmkvvevjhr+84uqlkdzhtszraw2fwhemoreauamtckhcyx0soduuryhlnw6qc7ffrqteq43fesu75iffjmajl7dldr/iphcgil8+utopafbp5f7czsssgifijnw65tgx1loquddju1k30tym7jq2em3ikazc19p+nv2ybzwm8snlxoik7/6esgmgdsfwtgdasa3hwc/8j9us9pfrqqjjbhnibov8rbkmsc800hskm5qdiyhtwvyvsdy1yacjnmtccmzpnhtv3djbyt4zyzrhubnyhc0ogan7uiztqeavgnzde7zcm/vgpvvv1segdcoazmzan7k+vghn5qan</latexit> <latexit sha1_base64="iw7xth2dawm/jzjbcq+se9ukx08=">aaacjnicbzdlssnafiyn9vbrlerszwar6sksufexloiglhwmck0pk+mkhtq5mhmilshp0jdw41vo1o3gbxhng7hw2lrxdmdg5//o4cz5vvhwbzb1auqmjqemz/kzhbn5hculc3nltewjpmyhkyjkhucuezxkdnaq7ckwjaseyode52dazy+zvdwkt6exs3pawih3oswgryzzoct72bxmh5k95fqs0ntoulxqbmau5k02bi4p3sjfvdugdbnola1h4b/c/htfaqwvbm7f+8cn88ftrjqjwahuekvqthvdpsusobusk7ijyjghhdjins1dejbvt4d3znhdo03sr1k/epdq/t6rkkcpxudpzobaw/1ma/m/vkva362npiwtycedlfitgshcg9bwk0tgqfs0ifry/vdm20shatragg7b/n3yx+fsl/fk1okoo4pgludrab2vki12ubudowpkiiqu0b16re/gtxfvpbsvo9ac8tmzin6u8fyb3ygo2q==</latexit> <latexit sha1_base64="iw7xth2dawm/jzjbcq+se9ukx08=">aaacjnicbzdlssnafiyn9vbrlerszwar6sksufexloiglhwmck0pk+mkhtq5mhmilshp0jdw41vo1o3gbxhng7hw2lrxdmdg5//o4cz5vvhwbzb1auqmjqemz/kzhbn5hculc3nltewjpmyhkyjkhucuezxkdnaq7ckwjaseyode52dazy+zvdwkt6exs3pawih3oswgryzzoct72bxmh5k95fqs0ntoulxqbmau5k02bi4p3sjfvdugdbnola1h4b/c/htfaqwvbm7f+8cn88ftrjqjwahuekvqthvdpsusobusk7ijyjghhdjins1dejbvt4d3znhdo03sr1k/epdq/t6rkkcpxudpzobaw/1ma/m/vkva362npiwtycedlfitgshcg9bwk0tgqfs0ifry/vdm20shatragg7b/n3yx+fsl/fk1okoo4pgludrab2vki12ubudowpkiiqu0b16re/gtxfvpbsvo9ac8tmzin6u8fyb3ygo2q==</latexit> What Portion of Code is Parallelizable? Expert programmers may not know! Fortunately, we can measure speedup Measure Set Calculate s(x) = x x(1 F )+F Fig. criticallyrated.files.wordpress.com Karp-Flatt Metric [Allen Karp and Horace Flatt 1990] F = s(x) 1 x?
38 Acknowledgment This lecture is a slightly modified version of the one prepared by Tom Anderson