Bioinformatic analysis of Illumina sequencing data for comparative genomics Part I
|
|
|
- Della Joseph
- 5 years ago
- Views:
Transcription

1 Bioinformatic analysis of Illumina sequencing data for comparative genomics Part I Dr David Studholme. 18 th February BIO1033 theme lecture February

2 28 February 2

 (Post-doc) (PhD) 28 February 2014")
3 (Head of Bioinformatics) (Computational biologist) (Post-doc) (Post-doc) (PhD) 28 February 3


4 28 February 4

5 28 February 5

6 The plan Part I: bacteria Part II: eukaryotes 28 February 6


7 What we will cover in the next hour Examples of how we use bacterial genomes Short-read sequence data Alignment of short reads against reference Calling single-nucleotide variation Assembly? 28 February 7
8 SINGLE-NUCLEOTIDE VARIATION 28 February 8


9 Example: fowl typhoid 28 February 9


10 Salmonella enterica subspecies enterica serotype Gallinarum FOWL TYPHOID Photo credit: 28 February 10



11 Live vaccines: Salmonella strain SG9R 28 February 11
12 What do we know about attenuated strain SG9R? SG9 (wild type) SG9R (vaccine) Pathogenic Attenuated Smooth colonies Rough colonies rfaj TCA [Ser] rfaj TAA [Stop] 28 February 12

 28 February 2014")
13 Outbreaks linked to the vaccine strain SG9R? Spleen, Farm A Faeces, Farm H Faeces, Farm A Vaccine MLVA (multi-locus variable number of tandem repeats analysis) 28 February 13
 Photo: http://www.timpestridge.co.")
14 Whole-genome sequencing of Salmonella Gallinarum Strain Comments Depth of coverage SG9 Wild type, UK, x SG9Ra Vaccine 342 x SG9Rb Vaccine, x MB4523 Outbreak, Belgium, x Illumina GAIIx paired reads ( nt) Photo: 28 February 14

15 Single-nucleotide differences SG9 wild type SG 287/ SG9R vaccine 9 MB4523 outbreak 28 February 15
16 Single-nucleotide substitutions: Basis of attenuation? 28 February 16

17 Single-nucleotide substitutions: Basis of attenuation 28 February 17

18 Single-nucleotide substitutions: Reversal of attenuation? vaccine outbreak 28 February 18


19 Fowl typhoid project - conclusions Concern over undefined live vaccines Possibility of reversal by a few substitutions 28 February 19
20 Example II KIWIFRUIT CANKER 28 February 20



21 Example: kiwi-fruit canker 28 February 21



22 28 February 22

23 Genetic relationships between PSA outbreaks 28 February 23

24 Genetic relationships between PSA outbreaks 28 February 24
25 Genetic relationships between PSA outbreaks 28 February 25
 28 February 2014")
26 Genetic relationships between PSA outbreaks (single-nucleotide differences) 28 February 26
27 Example III BANANA XANTHOMONAS WILT 28 February 27


28 Example: Banana Xanthomonas wilt 28 February 28

29 Example: banana Xanthomonas wilt 28 February 29
 28 February 2014 @davidjstudholme 30")
30 Causal agent of BXW disease: Xanthomonas campestris pv. musacearum (Xcm) 28 February 30


31 28 February 31

32 BXW is a recently emerging disease February 32

33 Xcm is closely related to X. vasicola 28 February 33
34 28 February 34


35 Genetic homogeneity 28 February 35
36 Whole-genome sequencing of Xvm isolates 28 February 36
37 Xvm isolates fall into two major sequence types (based on single-nucleotide differences) NCPPB4379 Uganda (Kayunga) 2007 NCPPB4394 Tanzania 2007 NCPPB4433 Burundi 2008 NCPPB4434 Kenya NCPPB4383 NCPPB4384 Uganda (Wakiso) 2007 Uganda (Nakasongola) 2007 Red type Xcm Sub-lineage II 100 NCPPB4380 Uganda (Kiboga) % identical NCPPB4381 Uganda (Luwero) 2007 NCPPB4395 Tanzania NCPPB4392 Tanzania NCPPB2005 Ethiopia 1967 (Enset) NCPPB2251 Ethiopia 1969 NCPPB4387 D. R. Congo 2007 Blue type Xcm Sub-lineage I 99 NCPPB4389 Rwanda February 37
38 The spread of banana Xanthomonas wilt disease (BXW) 28 February 38
39 The spread of banana Xanthomonas wilt disease (BXW) 28 February 39
40 Exemplar projects: single-nucleotide variation 28 February 40

41 28 February 41
42 SINGLE NUCLEOTIDE VARIATION: HOW WE DO IT 28 February 42

43 28 February 43
44 28 February 44

45 28 February 45

46 28 February 46
.")

47 ... previously Now (in Exeter) February 47


48 28 February 48
49 How much data? 28 February 49
50 Shotgun DNA sequencing Genomic DNA Fragmented DNA 28 February 50
51 DNA sequencing 5' 3' 3' 5' 900 bp Sanger 100 bp (Illumina) 450 bp (Roche 454) 28 February 51
52 DNA sequencing: paired reads 5' 3' 3' 5' 900 bp Sanger 100 bp (Illumina) 450 bp (Roche 454) 28 February 52
53 What do the data look like? 28 February 53

54 What do the data look like? 28 February 54
55 FastQ format 28 February 55
56 FastQ format 1. Title line 2. Sequence line 4. Quality line 28 February 56

57 Quality scores encoded in ASCII 28 February 57

58 Alignment of sequence reads versus a reference genome sequence 28 February 58
59 Alignment of sequence reads versus a reference genome sequence 28 February 59
60 DNA sequencing: paired reads 5' 3' 3' 5' 900 bp Sanger 100 bp (Illumina) 450 bp (Roche 454) 28 February 60

61 Alignment of sequence reads versus a reference genome sequence 28 February 61


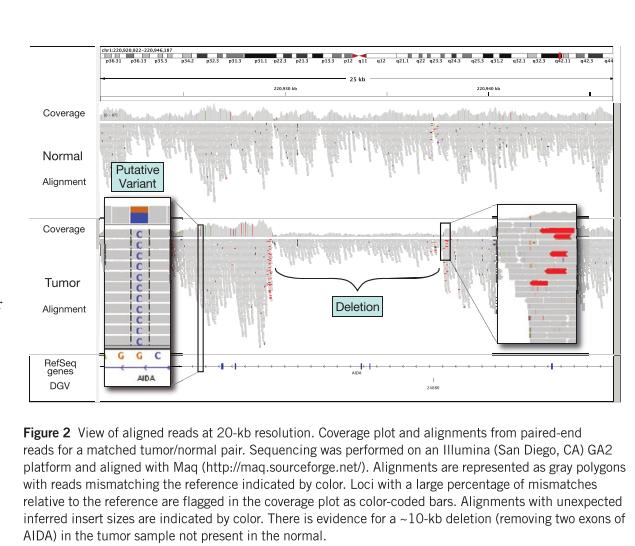
62 Visualisation of alignments 28 February 62

63 The alignment-tool deluge 28 February 63

64 My favourite short-read aligner 28 February 64
65 Short-read alignment: Some considerations How to handle non-unique matches? Mask repetitive sequences? Splicing-aware? 28 February 65
66 Nielsen R, Paul JS, Albrechtsen A, Song YS. Genotype and SNP calling from next-generation sequencing data. Nat Rev Genet : doi: /nrg February 66

67 28 February 67

68 Alignment of sequence reads versus a reference genome sequence 28 February 68

69 SAMtools Pileup format 28 February 69
70 SNP calling Assuming that false positives follow a binomial distribution with a 1.00 % probability of a single base-call being incorrect. 28 February 70
71 A word about SNP calling Base pairs Unambiguous Ambiguous Unambiguous: 95% consensus in each dataset >= 10 x depth in each dataset 28 February 71

72 Ambiguous single-nucleotide variation 28 February 72
73 GENE CONTENT 28 February 73

74 Gene content: global overview Xcm Xcm Xoo 28 February 74


75 28 February 75

76 Incorporating short-read assembly 28 February 76
77 Alignment is safer than assembly 28 February 77

78 Evolutionary events inferred from comparative genomics 28 February 78

79 Gene presence/absence These genes are unique to the banana pathogenic bacterial isolates 28 February 79

80 Inferring gene content from alignment 28 February 80
81 Gene content workflow Alignment 1 Alignment 2 Alignment 3 Alignment 4 CovereageBed CovereageBed CovereageBed CovereageBed Spreadsheet 1 Spreadsheet 2 Spreadsheet 3 Spreadsheet 4 Custom Perl script R, pheatmap Heatmap 28 February 81
82 DE NOVO ASSEMBLY 28 February 82

83 Photo credit: Ben Casey 28 February 83

84 Sequencing and assembling a genome 28 February 84

85 Shotgun DNA sequencing Genomic DNA Fragmented DNA 28 February 85
86 DNA sequencing 5' 3' 3' 5' 900 bp Sanger 100 bp (Illumina) 450 bp (Roche 454) 28 February 86
87 DNA sequencing: paired reads 5' 3' 3' 5' 900 bp Sanger 100 bp (Illumina) 450 bp (Roche 454) 28 February 87
88 The de novo sequence assembly problem 28 February 88


89 28 February 89

90 28 February 90

91 28 February 91
92 28 February 92
93 28 February 93




94 Illumina sequence read 100 bp Sanger / capillary sequence read 900 bp Human genome 3,200,000 bp 28 February 2014 Wheat genome 16,000,000,000 94
95 GATGGATAAGTTTTCTGACA CTGAATACAGGGATGTCTAT TTTTCTGACAAGCACTTCAG AAGCACTTCAGGGCTGAGCA TCAGGGCTGAGCATCCTGAA AGGGCTGAGCATCCTGAATA GACGATTTGATGGATAAGTT GGGATGTCTATCCGGAGGAA TCCGGAGGAATGTTCTGCCA Sequence reads GACGATTTGATGGATAAGTT GATGGATAAGTTTTCTGACA TTTTCTGACAAGCACTTCAG AAGCACTTCAGGGCTGAGCA TCAGGGCTGAGCATCCTGAA AGGGCTGAGCATCCTGAATA CTGAATACAGGGATGTCTAT GGGATGTCTATCCGGAGGAA TCCGGAGGAATGTTCTGCCA Contiguous sequence ( contig ) GACGATTTGATGGATAAGTTTTCTGACAAGCACTTCAGGGCTGAGCATCCTGAATACAGGGATGTCTATCCGGAGGAATGTTCTGCCA 28 February 95
96 The greedy algorithm (for de novo sequence assembly) 28 February 96
97 Simple greedy approach 28 February 97
98 Simple greedy approach 28 February 98
99 Simple greedy approach 28 February 99
100 Simple greedy approach 28 February 100
101 Simple greedy approach...acaggaggt GAGGTCCAGA......ACAGGAGGTCCAGA February 101
102 Simple greedy approach 28 February 102
103 Simple greedy approach 28 February 103
104 Simple greedy approach 28 February 104
105 Simple greedy approach 28 February 105
106 Simple greedy approach 28 February 106
107 Simple greedy approach 28 February 107
108 Simple greedy approach 28 February 108
109 Simple greedy approach 28 February 109
110 Simple greedy approach 28 February 110
111 The problem of repeat sequences 28 February 111
112 The problem of repetitive sequences CGCGCATATATATATATATATATATATATATATATATATATATATATATATATATATATGCCGATTGA 28 February 112
113 The problem of repetitive sequences CGCGCATATATATATATATATATATATATATATATATATATATATATATATATATATATGCCGATTGA CGCATATATATATAT TATATATATATATATA ATATATATATATATA CGCGCATATATATAT TATATATATATATATA TATATATATATATATA TATATATATATATATA TATATGCCGATT ATGCCGATTGA 28 February 113
114 The problem of repetitive sequences TATATATATATATATA TATATATATATATATA ATATATATATATATA CGCGCATATATATAT ATGCCGATTGA CGCATATATATATAT TATATGCCGATT TATATATATATATATA TATATATATATATATA 28 February 114
115 The problem of repetitive sequences TATATATATATATATA TATATATATATATATA ATATATATATATATA CGCGCATATATATAT ATGCCGATTGA CGCATATATATATAT TATATGCCGATT TATATATATATATATA TATATATATATATATA CGCGCATATATATATATATATATGCCGATTGA 28 February 115

116 The problem of repetitive sequences CGCGCATATATATATATATATATATATATATATATATATATATATATATATATATATATGCCGATTGA CGCGCATATATATATATATATATGCCGATTGA 28 February 116
117 OLC and k-mer graphs GRAPH-BASED METHODS 28 February 117

118 What is a graph? undirected directed 28 February 118
119 OVERLAP LAYOUT CONSENSUS (OLC) 28 February 119


120 Overlap-consensus-Layout (OLC) ATGCCGTTGAACTTCGTTGAACACATGGTCATAC Genome sequence ATGCCGTT GCCGTTGAA GAACACATGG GAACTTCGTTGA CACATGGTCAT TTGAACACAT Sequence reads 28 February 120
121 Overlap-consensus-Layout (OLC) ATGCCGTT GCCGTTGAA GAACACATGG CACATGGTCAT GAACTTCGTTGA TTGAACACAT 28 February 121
122 Is there a Hamiltonian path? (passes through every node exactly once) ATGCCGTT GCCGTTGAA GAACACATGG CACATGGTCAT GAACTTCGTTGA TTGAACACAT 28 February 122
123 Hamiltonian path ATGCCGTT GCCGTTGAA GAACACATGG CACATGGTCAT GAACTTCGTTGA TTGAACACAT ATGCCGTT GCCGTTGAA GAACTTCGTTGA TTGAACACAT GAACACATGG CACATGGTCAT ATGCCGTTGAACTTCGTTGAACACATGGTCAT 28 February 123

124 OLC requires all-versus-all comparisons ATGCCGTT GCCGTTGAA CACATGGTCAT GAACACATGG TTGAACACAT GAACTTCGTTGA 28 February 124
125 K-MER GRAPH METHOD 28 February 125

126 Genome size = 2,250,000,000 bp Average read length = 52 bp 176 Gb of sequence data 28 February 126
127 Building the k-mer graph aaccgg aacc accg ccgg K = 4 28 February 127
128 Building the k-mer graph 28 February 128
129 Reconstructing the original sequence from the k-mer graph Eulerian path: passes through every edge at least once 28 February 129

130 Finding the Eulerian path in a k-mer graph Ideal data Real data 28 February 130
131 From contigs to scaffolds 28 February 131
132 GATGGATAAGTTTTCTGACA CTGAATACAGGGATGTCTAT TTTTCTGACAAGCACTTCAG AAGCACTTCAGGGCTGAGCA TCAGGGCTGAGCATCCTGAA AGGGCTGAGCATCCTGAATA GACGATTTGATGGATAAGTT GGGATGTCTATCCGGAGGAA TCCGGAGGAATGTTCTGCCA Sequence reads GACGATTTGATGGATAAGTT GATGGATAAGTTTTCTGACA TTTTCTGACAAGCACTTCAG AAGCACTTCAGGGCTGAGCA TCAGGGCTGAGCATCCTGAA AGGGCTGAGCATCCTGAATA CTGAATACAGGGATGTCTAT GGGATGTCTATCCGGAGGAA TCCGGAGGAATGTTCTGCCA GACGATTTGATGGATAAGTTTTCTGACAAGCACTTCAGGGCTGAGCATCCTGAATACAGGGATGTCTATCCGGAGGAATGTTCTGCCA Contiguous sequence ( contig ) 28 February 132
133 Sequence reads Contig assembly Contig 1 Contig2 Contig3 Contig6 Contig4 Contig5 Contig3 Contig 1 Contig5 Contig2 Contig4 Contig6 Scaffold 28 February 133
134 Paired-end sequencing 5' 3' 3' 5' 900 bp Sanger 100 bp (Illumina) 450 bp (Roche 454) 500 bp 50 kbp 28 February 134

135 Scaffolding (using paired reads) 28 February 135

136 Software: assembly 28 February 136

137 28 February 137