Data Science is a Team Sport and an Iterative Process
|
|
|
- Jared Hudson
- 5 years ago
- Views:
Transcription





1 Data Science is a Team Sport and an Iterative Process Data Engineer Data Scientist Biz Analyst Dev Ops App Developer Dev Ops Extract Data Prepare Data Build models Train Models Evaluate Deploy Use models Monetize $$$ Monitor Building cognitive apps using deep learning requires multiple skillsets. 1

2 enterprise-ready software distribution built on open source performance faster training times for data scientists tools for ease of development

3 PowerAI Enterprise-Ready Software Distribution Built on Open Source Precompiled and current open source frameworks


4 PowerAI Enterprise-Ready Software Distribution Built on Open Source Available enterprise support for the entire stack 4

5 POWER9 An acceleration superhighway. The only processor specifically designed for the AI era. P9 OpenCAPI NVLink 2.0 PCIe Gen4 Faster PowerAccel Interconnect for Accelerators 4x 9.5x 2.6x 1st Threads per core vs x86 Up to 9.5x more I/O bandwidth than x86 More RAM possible vs. x86 CPU to deliver PCIe gen 4 OpenCAPI / NVLink x vs. Intel


6 Server Design X86 Server

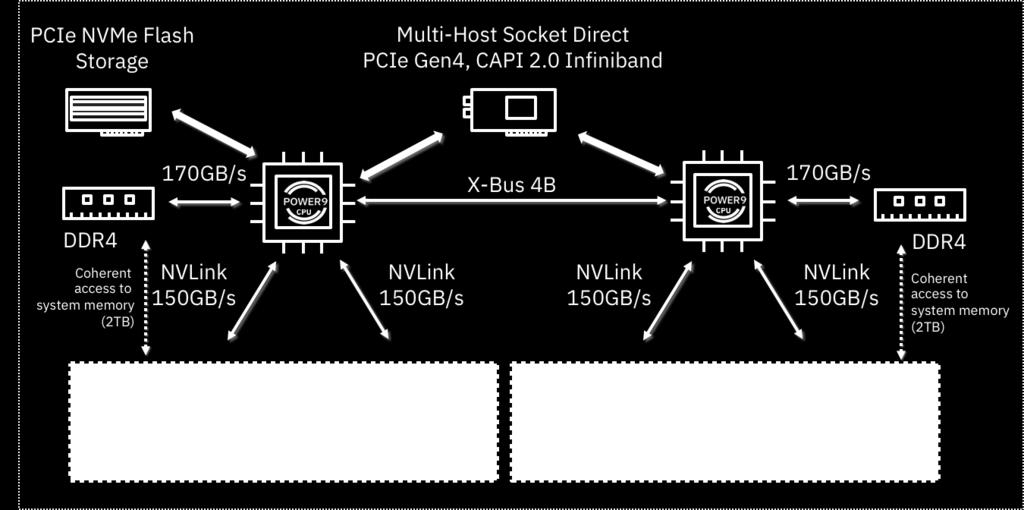
7 Server Design POWER9 Server




8 PowerAI Performance Faster Training and Inferencing Faster training times for data scientists Traditional Model Support Limited memory on GPU forces trade-off in model size / data resolution Large Model Support Use system memory and GPU to support more complex and higher resolution data POWER NVLink Data Pipe DDR4 CPU System Bottleneck Here DDR4 POWER CPU NVLink PCIe Graphics Memory GPU Graphics Memory GPU 8


9 Designed for the AI era: Caffe provides a 3.8X reduction in AI model training vs tested x86 systems Maximize research productivity running training for medical/satellite images with Caffe with the AC X reduction vs tested x86 systems 1000 iterations running on competing systems to train on 2k x 2k images Critical machine learning (ML) capabilities such as regression, nearest neighbor, recommendation systems, clustering, etc. operate on more than just the GPU memory NVLink 2.0 enables enhanced Host to GPU communication Large Model Support - use system memory and GPU memory to support more complex and higher resolution data Caffe: More Accuracy (3.8 iterations vs 1) + 80% iteration Three Iterations Two Iterations 4 run Accuracy 3 run Accuracy 2 run Accuracy One Iteration One Iteration 1 run Accuracy Results are based IBM Internal Measurements running 1000 iterations of Enlarged GoogleNet model (mini-batch size=5) on Enlarged Imagenet Dataset (2240x2240). Power AC922; 40 cores (2 x 20c chips), POWER9 with NVLink 2.0; 2.25 GHz, 1024 GB memory, 4xTesla V100 GPU ; Red Hat Enterprise Linux 7.4 for Power Little Endian (POWER9) with CUDA 9.1/ CUDNN 7;. Competitive stack: 2x Xeon E v4; 20 cores (2 x 10c chips) / 40 threads; Intel Xeon E v4; 2.4 GHz; 1024 GB memory, 4xTesla V100 GPU, Ubuntu with CUDA.9.0/ CUDNN 7. 9 Software: IBM Caffe with LMS Source code Xeon 4xV100 AC922 4xV100
")

10 TensorFlow 1.4 on IBM POWER9 + NVidia V100 Single node 35% more images processed per second ResNet50 testing on ILSVRC 2012 dataset (aka Imagenet 2012) Training on 1.2M images Validation on 50K images 1000 iterations of HPM Resnet50 on 1.2M images and validation on 50K images with Dataset from ILSVRC 2012 also known as Imagenet Software: Tensorflow framework and HPM Resnet50 (com mit: f5d85aef) Parameters: Batch-Size: 64 per GPU; Iterations: 1100; Data: Imagenet; local-parameter-device: gpu; variable-update: replicated
.")
11 PowerAI Performance Faster Training and Inferencing Faster training times for data scientists Distributed Deep Learning IBM Research beat Facebook s time by training the model in 50 minutes, versus the 1 hour Facebook took. Using this software, IBM Research achieved a new image recognition accuracy of 33.8% for a neural network trained on a very large data set (7.5M images). The previous record published by Microsoft demonstrated 29.8% accuracy. Training time: IBM=7 hours, MS=240 hours For developers and data scientists, the IBM Research (DDL) software presents an API (application programming interface) that each of the deep learning frameworks can hook into, to scale to multiple servers. 11 ResNet-50, ImageNet-1K, Caffe with PowerAI DDL, Running on Minsky (S822Lc) Power System Source: Source: PowerAI DDL -

 Training on 1.")
12 Designed for the AI era: TensorFlow provides a 2.3X reduction in AI model training vs tested x86 systems Maximize research productivity running training for medical/satellite images with TensorFlow with the AC X more images processed per second vs tested x86 systems PowerAI Distributed Deep Learning (DDL) library provides innovative distribution methods enabling AI frameworks to scale to multiple servers leveraging all attached GPUs ResNet50 testing on ILSVRC 2012 dataset (aka Imagenet 2012) Training on 1.2M images, Validation on 50K images Large Model Support - use system memory and GPU memory to support more complex and higher resolution data Results are based IBM Internal Measurements running 1000 iterations of HPM Resnet50 on 1.2M images and validation on 50K images with Dataset from ILSVRC 2012 aka Imagenet Hardware: 4 nodes of Power AC922; 40 cores (2 x 20c chips), POWER9 with NVLink 2.0; 2.25 GHz, 1024 GB memory, 4xTesla V100 GPU ; Red Hat Enterprise Linux 7.4 for Power Little Endian (POWER9). Competitive stack: 4 nodes of 2x Xeon E v4; 20 cores (2 x 10c chips) / 40 threads; Intel Xeon E v4; 2.4 GHz; 1024 GB memory, 4xTesla V100 GPU, Ubuntu Software: Tensorflow framework and HPM Resnet50 (commit: f5d85aef) and with the following parameters:batch-size: 64 per GPU ; Iterations: 1100; Data: Imagenet; local-parameter-device: gpu; variable-update: replicated TensorFlow: More Accuracy (2.3 iterations vs 1) One Iteration Xeon 4xV100 30% iteration Two Iterations One Iteration AC922 4xV100 3 run Accuracy 2 run Accuracy 1 run Accuracy






13 Tools for Ease of Development Rich advisory and building toolsets to flatten time to value automated deep learning toolkit data preparation 13 IBM DL Impact for hyper parameter tuning, visualization, monitoring
 CPU + GPU cluster Deep Learning frameworks Model pool Deep Learning frameworks Application servers, DB service, messaging, etc.")


14 Managing DL workflows Training (Research/Development) Inference (Deployment/Production) Data Cleaning Feature Engineering Modeling Trained model Recognition, classification Application Data Management Big data frameworks (Hadoop, Spark) CPU + GPU cluster Deep Learning frameworks Model pool Deep Learning frameworks Application servers, DB service, messaging, etc. CPU + GPU/FPGA cluster Scalable data ingest, transformation, labeling, augmentation Support of different DL frameworks Performance and accuracy Parallel distribution & communication bottleneck GPU and topology aware scheduling Model and data set management Hyper-parameter selection and tuning Monitoring and execution optimization Resilience and elasticity Production deployment Support data pipeline & workflow Mixture of micro-services, batch and real time jobs GPU vs. CPU mixed scheduling Different data sources, e.g., HDFS, Object, Posix, Non- SQL, SQL Multi-tenancy, QoS for data preprocessing, training and prediction Shared resource pool of heterogeneous resources GPU, Power, FPGA Different Spark, DL framework, notebooks and versions & Deployment Security, governance Scalable data management
15 IBM Spectrum Conductor & PowerAI Data Preparation Model Training Inference Raw Data Pre-processing (parallel) Hyper-parameter selection & optimization Deploy in Production using Trained Model Monitor & Advise Network Model Hyper- parameters New Data Training Dataset Testing Dataset Train Test Instrumentation DL Frameworks (Tensorflow & IBM Caffe) Distributed DL (Fabric) IBM CL Iterate Trained Model PowerAI Inferencing Engine (PIE) Session scheduler Data Connector Crail, RDMA, CAPI FPGA Notebook Spark ELK Conductor with Spark GPU Accelerated Mllib, Graphx Service management (ASC/K8s) GPU and Acceleration Security Report/log management Multi-tenancy Container Spectrum Conductor Deep Learning Impact Existing Spectrum Conductor Third Party/Open source PowerAI 15

16 Deep Learning Impact: Monitor, Adviser and Optimizer

17 Enabling Deep Learning workflows with PowerAI, Conductor for SPARK and DL Impact Data Up & Running Data Pre- Processing Build, Train, Optimize Deploy & Infer Maintain Model Accuracy Discovery Workshops Lab Services PowerAI: 3 CLs for deployment PowerAI Support: L1-L3 across stack CwS: Multi Tenancy, Shared Services DL Impact: Distributed data processing & transformation CwS: Integrated SPARK for data management & ETL DL Impact: Visualization, Hyper-paramer, Accuracy monitoring PowerAI: Distributed DL, Large Model Support DL Impact: Single click REST API DL Impact: Model management & accuracy monitoring 17







18 PowerAI Vision: End to End Computer Vision Platform Computer Vision Services Image Labeling and Preprocessing Video Labeling Service Custom Learning for Image Classification Custom Learning for Object Detection Self-defined Training with visualized monitoring Inference API deployment Data Up & Running Data Pre- Processing Build, Train, Optimize Deploy & Infer Maintain Model Accuracy 18







19 Object Detection Example with AI Vision Want to develop an application to automatically monitor the safety in field Define the regulation requirement through data labeling Click to finish all the steps, and get the API for detection










20 IBM AI & Data Science Workbench Democratizing ML Operationalizing ML Model Builder SPSS Flows Fit-for-purpose Integration with Watson functions Machine Learning Runtimes Deep Learning Runtimes Cloud Infrastructure as a Service Model Lifecycle Management Cognitive Systems Data Stores 20

21 Data Science Experience brings all the tools you need into one place IBM Data Science Experience Community Open Source IBM Added Value Find tutorials and datasets Connect with Data Scientists Ask questions Read articles and papers Fork and share projects Code in Scala/Python/R/SQL Jupyter Notebooks RStudio IDE and Shiny Apache Spark Your favorite libraries Projects and Version Control Spark Service and Remote Spark IBM Machine Learning Platform Manager 21

22 22 PowerAI: Open-Source AI Offering Ease of Use & Performance
23 Summary IBM PowerAI & Spectrum Conductor have Business Value Efficiency: Reduced training time, allows data scientist to iterate and improve models Accuracy: Higher performance, more runs (ensemble), larger data sets Beyond deep learning: Run other accelerated workloads (simulation, analytics, HPC) Ease of implementation: Widely tested & accepted frameworks plus IBM support Innovation: NVLink & OpenCAPI for faster and efficient interconnect with accelerators Democratizing ML: IBM Data Science Experience supports the data scientist community to learn, create, and collaborate

24 Thanks for the attention! Luca Sangiorgi Cognitive Solutions Sales Leader IBM Systems it.linkedin.com/in/sangiorgiluca 2017 IBM Corporation