HTCaaS: Leveraging Distributed Supercomputing Infrastructures for Large- Scale Scientific Computing
|
|
|
- Clinton Sharp
- 6 years ago
- Views:
Transcription



1 HTCaaS: Leveraging Distributed Supercomputing Infrastructures for Large- Scale Scientific Computing Jik-Soo Kim, Ph.D National Institute of Supercomputing and Networking(NISN) at KISTI
2 Table of Contents Introduction HTCaaS: High-Throughput Computing as a Service Evaluation Conclusions & Discussions Slide #2
![Introduction From HTC to Many-Task Computing (MTC) [MTAGS 08] A very large number](/docs-images/72/66719724/images/3-0.jpg "of tasks (millions or even billions) Relatively short per task execution times")
 Communication-intensive,")

3 Introduction From HTC to Many-Task Computing (MTC) [MTAGS 08] A very large number of tasks (millions or even billions) Relatively short per task execution times (sec to min) Data intensive tasks (i.e., tens of MB of I/O per second) A large variance of task execution times (i.e., ranging from hundreds of milliseconds to hours) Communication-intensive, however, not based on message passing interface (such as MPI) but through files astronomy, physics, pharmaceuticals, chemistry, etc. Slide #3
4 Introduction Middleware Systems for HTC/MTC applications Ease of Use Minimize user overhead for handling jobs and resources Efficient Task Dispatching The overhead of task dispatching should be low enough Adaptiveness adjust acquired resources according to changing load Fairness ensure fairness among multiple users submitting various numbers of tasks Reliability Failed or suspended tasks should be automatically resubmitted and managed Resource Integration effectively integrate as many computing resources as possible Slide #4




5 Introduction Our Approach High-Throughput Computing As a Service Meta-Job based automatic job split & submission e.g., parameter sweeps or N-body calculations Agent-based multi-level scheduling User-level Scheduling and Dynamic Fairness Pluggable interface to heterogeneous computing resources Supporting many client interfaces Native WS-interface, Java API Easy-to-use client tools (CLI/GUI/Web portal) HTCaaS is currently running as a pilot service on top of PLSI supporting a number of scientific applications from pharmaceutical domain and high-energy physics Slide #5
6 Table of Contents Introduction HTCaaS: High-Throughput Computing as a Service Evaluation Conclusions & Discussions Slide #6


7 High-Throughput Computing as a Service System Architecture Slide #7


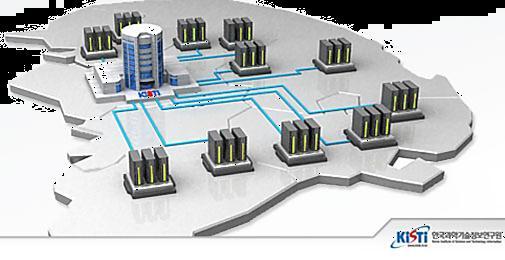





8 High-Throughput Computing as a Service > htcaas Account Manager Certificate Monitoring Manager Job Manager Agent Job Queue Agent Agent JSDL: Parameter Sweep Job Extension User Data Manager Agent Manager Agent Agent Agent submission HTCaaS 8
9 High-Throughput Computing as a Service Job Queues and Agents Management maintains separate job queues and agents per user reducing complexities of accounting and scheduling track and meter the usage of PLSI computing resources per user carefully calibrating the number of agents per user can address the problem of fair resource sharing among multiple users Each agent actively pulls the tasks from its dedicated job queue which corresponds to a specific user if there are no more tasks to be processed, it automatically releases the acquired resources and exits Monitoring and Fault-tolerance periodically checks the status of agents and tasks If some of agents or tasks fail, the Monitoring Manager informs the Agent Manager (or the Job Manager) to resubmit the failed agents (tasks) and manage them (addressing Reliability) Slide #9
10 High-Throughput Computing as a Service User-level Scheduling and Dynamic Fairness Dynamic fair resource sharing algorithm divides all available computing resources fairly across all demanding users in the system (when the system is heavily loaded) and exploits dynamic adjustment of acquired resources as free computing resources become available (as the overall system becomes lightly loaded) Resource Allotment Function Weight(p) represents the weight of a user p» can consider many different factors such as the number of tasks submitted by the user p, task running time, priority, etc.» Weighted Fairness addressing Fairness and Adaptiveness Slide #10
11 High-Throughput Computing as a Service Timeline & Events Computing Resources RA Job Queues t 0 All 100 cores are free 100 free cores t 1 User A arrives and submits 200 tasks RA(A)=100 t 2 User B arrives and submits 50 tasks User A s 100 tasks RA(A)=50 RA(B)=50 A: 100 tasks(du) t 3 t 4 t 5 User A release 50 cores User B acquires 50 cores User C arrives and submits 20 tasks User A s 50 tasks User B s 50 tasks RA(A)=50 RA(C)=20 A: 50 tasks(du) B: 0 tasks(su) A: 50 tasks(du) t 6 User B s tasks finish C: 20 tasks(du) t 7 t 8 User C acquires 20 cores User A acquires additional 30 cores User A s 50 tasks C s 20 tasks User A s 80 tasks 30 free cores C s 20 tasks A: 20 tasks(du) C: 0 tasks(su) Slide #11
12 Table of Contents Introduction HTCaaS: High-Throughput Computing as a Service Evaluation Conclusions & Discussions Slide #12

13 Evaluation PLSI (Partnership & Leadership for the nationwide Supercomputing Infrastructure) provide researchers with an integrated view of geographically distributed supercomputing infrastructures to solve complex and demanding scientific problems consisting of multiple organizations connected via a dedicated 1Gbps network [100TFLops of computing power, 1,115 nodes with 8,508 CPU cores] Slide #13

14 Evaluation PLSI provides a common software stack Accounting (based on LDAP), Monitoring (via Nagios), Global scheduling (based on LoadLeveler) and a Global shared storage system (based on GPFS) utilize the LoadLeveler as a job submission system to available computing nodes in the PLSI configured as a multi-cluster environment exploits a total 400TB of global home/scratch directories mounted at every computing node as a shared storage system for input/output data and executables Slide #14
15 Evaluation Micro-Benchmark Experiments simulating a large number of short-running tasks (sleep 10) and relatively long-running tasks (sleep 100) glory cluster in KISTI (300 cores) Performance Metrics Makespan (time to complete a bag of tasks) Efficiency (comparison with ideal parallelism) Comparison Models HTCaaS with DB Manager connections (HTCaaS(DB)) HTCaaS without DB Manager interactions (HTCaaS(No DB)) LoadLeveler+GPFS (LoadLeveler) Slide #15


16 Evaluation Micro-Benchmark Experiments For short running tasks, HTCaaS clearly outperforms LoadLeveler For relatively long running tasks, overheads of task dispatching can be effectively countervailed 57% 35% sleep 10 sleep 100 HTCaaS are still being improved 5% improvements Slide #16

17 Evaluation Micro-Benchmark Experiments Job holding problem during the course of LoadLeveler dispatching due to multiple simultaneous I/O operations on the GPFS HTCaaS can effectively leverage the local storage of the computing resource User Data Manager manages overall input/output data staging support data-intensive HTC/MTC applications where typical size of a single input data is relatively small (from hundreds of KBs to MBs) sleep 10 sleep 100 Slide #17
18 Evaluation Protein Docking Experiments Autodock, a suite of automated docking tools perform the docking of ligands to a set of target proteins to discover new drugs for several serious diseases such as SARS or Malaria Experimental setup Clusters: glory, kobic, gene and helix Four different users are sequentially arriving at our system and submit various numbers of tasks (ligands) with an average inter-arrival time of 10 minutes from 1000 down to 100 for the single cluster from 2000 down to 250 for the multi-cluster Comparison Models HTCaaS with dynamic fair resource sharing algorithm dynamic fairness (DF) Simple resource partitioning algorithm strict fairness (Simple) Slide #18


19 Evaluation Protein Docking Experiments HTCaaS can reduce the performance gap among users with various numbers of tasks HTCaaS can seamlessly integrate multiple geographically distributed clusters fully utilize available computing resources as they become available, while Simple inevitably wastes idle computing resources resource waste improving fairness 64% Slide #19
20 Table of Contents Introduction HTCaaS: High-Throughput Computing as a Service Evaluation Conclusions & Discussions Slide #20
21 Conclusion HTCaaS to provide researchers with ease of exploring large-scale and complex HTC/MTC problems by integrating distributed national supercomputers Employing the concept of Meta-Job (with easy-to-use client tools) and a fault-tolerant agent-based multi-level scheduling mechanism (Ease of Use, Efficient Task Dispatching and Reliability) Employing dynamic fair resource sharing mechanism (Fairness and Adaptiveness) HTCaaS effectively leverages local disks of geographically distributed computing resources support data-intensive HTC/MTC applications HTCaaS can seamlessly utilize all of available computing resources without resource wastage (Resource Integration) Slide #21
22 Discussion Future Work supporting more complex workloads consisting of HTC and HPC tasks improving the scalability of HTCaaS, and applying job profiling technique to realize the weighted form of fairness How we can more efficiently support data-intensive MTC applications on top of geographically distributed computing environments such as PLSI? Shared storage system such as GPFS will be performance bottleneck Data caching may work but it depends on the workload characteristics Slide #22
23 Thank you! National Institute of Supercomputing and Networking 2013
High Performance Computing(HPC) & Software Stack
 & Software Stack") IBM HPC Developer Education @ TIFR, Mumbai High Performance Computing(HPC) & Software Stack January 30-31, 2012 Pidad D'Souza (pidsouza@in.ibm.com) IBM, System & Technology Group 2002 IBM Corporation Agenda
IBM HPC Developer Education @ TIFR, Mumbai High Performance Computing(HPC) & Software Stack January 30-31, 2012 Pidad D'Souza (pidsouza@in.ibm.com) IBM, System & Technology Group 2002 IBM Corporation Agenda
Computer clusters using commodity processors, network interconnects, and operating systems.
 Computer clusters using commodity processors, network interconnects, and operating systems. Supercomputers are highly-tuned computer clusters using commodity processors combined with custom network interconnects
Computer clusters using commodity processors, network interconnects, and operating systems. Supercomputers are highly-tuned computer clusters using commodity processors combined with custom network interconnects
<Insert Picture Here> Oracle Exalogic Elastic Cloud: Revolutionizing the Datacenter
 Oracle Exalogic Elastic Cloud: Revolutionizing the Datacenter Mike Piech Senior Director, Product Marketing The following is intended to outline our general product direction. It
Oracle Exalogic Elastic Cloud: Revolutionizing the Datacenter Mike Piech Senior Director, Product Marketing The following is intended to outline our general product direction. It
IBM Tivoli Workload Automation View, Control and Automate Composite Workloads
 Tivoli Workload Automation View, Control and Automate Composite Workloads Mark A. Edwards Market Manager Tivoli Workload Automation Corporation Tivoli Workload Automation is used by customers to deliver
Tivoli Workload Automation View, Control and Automate Composite Workloads Mark A. Edwards Market Manager Tivoli Workload Automation Corporation Tivoli Workload Automation is used by customers to deliver
IBM Power Systems. Bringing Choice and Differentiation to Linux Infrastructure
 IBM Power Systems Bringing Choice and Differentiation to Linux Infrastructure Stefanie Chiras, Ph.D. Vice President IBM Power Systems Offering Management Client initiatives Cognitive Cloud Economic value
IBM Power Systems Bringing Choice and Differentiation to Linux Infrastructure Stefanie Chiras, Ph.D. Vice President IBM Power Systems Offering Management Client initiatives Cognitive Cloud Economic value
Metrics & Benchmarks
 Metrics & Benchmarks Task 2.3 Marios Dikaiakos George Tsouloupas Dept. of Computer Science University of Cyprus Nicosia, CYPRUS Benchmarks 101 X# Synthetic Codes and Application Kernels with well-defined
Metrics & Benchmarks Task 2.3 Marios Dikaiakos George Tsouloupas Dept. of Computer Science University of Cyprus Nicosia, CYPRUS Benchmarks 101 X# Synthetic Codes and Application Kernels with well-defined
On Cloud Computational Models and the Heterogeneity Challenge
 On Cloud Computational Models and the Heterogeneity Challenge Raouf Boutaba D. Cheriton School of Computer Science University of Waterloo WCU IT Convergence Engineering Division POSTECH FOME, December
On Cloud Computational Models and the Heterogeneity Challenge Raouf Boutaba D. Cheriton School of Computer Science University of Waterloo WCU IT Convergence Engineering Division POSTECH FOME, December
Accelerate Insights with Topology, High Throughput and Power Advancements
 Accelerate Insights with Topology, High Throughput and Power Advancements Michael A. Jackson, President Wil Wellington, EMEA Professional Services May 2014 1 Adaptive/Cray Example Joint Customers Cray
Accelerate Insights with Topology, High Throughput and Power Advancements Michael A. Jackson, President Wil Wellington, EMEA Professional Services May 2014 1 Adaptive/Cray Example Joint Customers Cray
CLOUD MANAGEMENT PACK FOR ORACLE FUSION MIDDLEWARE
 CLOUD MANAGEMENT PACK FOR ORACLE FUSION MIDDLEWARE Oracle Enterprise Manager is Oracle s strategic integrated enterprise IT management product line. It provides the industry s first complete cloud lifecycle
CLOUD MANAGEMENT PACK FOR ORACLE FUSION MIDDLEWARE Oracle Enterprise Manager is Oracle s strategic integrated enterprise IT management product line. It provides the industry s first complete cloud lifecycle
Guide to Modernize Your Enterprise Data Warehouse How to Migrate to a Hadoop-based Big Data Lake
 White Paper Guide to Modernize Your Enterprise Data Warehouse How to Migrate to a Hadoop-based Big Data Lake Motivation for Modernization It is now a well-documented realization among Fortune 500 companies
White Paper Guide to Modernize Your Enterprise Data Warehouse How to Migrate to a Hadoop-based Big Data Lake Motivation for Modernization It is now a well-documented realization among Fortune 500 companies
A Examcollection.Premium.Exam.35q
 A2030-280.Examcollection.Premium.Exam.35q Number: A2030-280 Passing Score: 800 Time Limit: 120 min File Version: 32.2 http://www.gratisexam.com/ Exam Code: A2030-280 Exam Name: IBM Cloud Computing Infrastructure
A2030-280.Examcollection.Premium.Exam.35q Number: A2030-280 Passing Score: 800 Time Limit: 120 min File Version: 32.2 http://www.gratisexam.com/ Exam Code: A2030-280 Exam Name: IBM Cloud Computing Infrastructure
Introduction. DIRAC Project
 Introduction DIRAC Project Plan DIRAC Project DIRAC grid middleware DIRAC as a Service Tutorial plan 2 Grid applications HEP experiments collect unprecedented volumes of data to be processed on large amount
Introduction DIRAC Project Plan DIRAC Project DIRAC grid middleware DIRAC as a Service Tutorial plan 2 Grid applications HEP experiments collect unprecedented volumes of data to be processed on large amount
High-Performance Computing (HPC) Up-close
 Up-close") High-Performance Computing (HPC) Up-close What It Can Do For You In this InfoBrief, we examine what High-Performance Computing is, how industry is benefiting, why it equips business for the future, what
High-Performance Computing (HPC) Up-close What It Can Do For You In this InfoBrief, we examine what High-Performance Computing is, how industry is benefiting, why it equips business for the future, what
IBM Tivoli Workload Scheduler
 Manage mission-critical enterprise applications with efficiency IBM Tivoli Workload Scheduler Highlights Drive workload performance according to your business objectives Help optimize productivity by automating
Manage mission-critical enterprise applications with efficiency IBM Tivoli Workload Scheduler Highlights Drive workload performance according to your business objectives Help optimize productivity by automating
Integration of Titan supercomputer at OLCF with ATLAS Production System
 Integration of Titan supercomputer at OLCF with ATLAS Production System F Barreiro Megino 1, K De 1, S Jha 2, A Klimentov 3, P Nilsson 3, D Oleynik 1, S Padolski 3, S Panitkin 3, J Wells 4 and T Wenaus
Integration of Titan supercomputer at OLCF with ATLAS Production System F Barreiro Megino 1, K De 1, S Jha 2, A Klimentov 3, P Nilsson 3, D Oleynik 1, S Padolski 3, S Panitkin 3, J Wells 4 and T Wenaus
HPC in Bioinformatics and Genomics. Daniel Kahn, Clément Rezvoy and Frédéric Vivien Lyon 1 University & INRIA HELIX team LIP-ENS & INRIA GRAAL team
 HPC in Bioinformatics and Genomics Daniel Kahn, Clément Rezvoy and Frédéric Vivien Lyon 1 University & INRIA HELIX team LIP-ENS & INRIA GRAAL team Moore s law in genomics Exponential increase Doubling
HPC in Bioinformatics and Genomics Daniel Kahn, Clément Rezvoy and Frédéric Vivien Lyon 1 University & INRIA HELIX team LIP-ENS & INRIA GRAAL team Moore s law in genomics Exponential increase Doubling
[Header]: Demystifying Oracle Bare Metal Cloud Services
![[Header]: Demystifying Oracle Bare Metal Cloud Services](/thumbs/77/74649912.jpg "[Header]: Demystifying Oracle Bare Metal Cloud Services") [Header]: Demystifying Oracle Bare Metal Cloud Services [Deck]: The benefits and capabilities of Oracle s next-gen IaaS By Umair Mansoob Introduction As many organizations look to the cloud as a way to
[Header]: Demystifying Oracle Bare Metal Cloud Services [Deck]: The benefits and capabilities of Oracle s next-gen IaaS By Umair Mansoob Introduction As many organizations look to the cloud as a way to
Improve Your Productivity with Simplified Cluster Management. Copyright 2010 Platform Computing Corporation. All Rights Reserved.
 Improve Your Productivity with Simplified Cluster Management TORONTO 12/2/2010 Agenda Overview Platform Computing & Fujitsu Partnership PCM Fujitsu Edition Overview o Basic Package o Enterprise Package
Improve Your Productivity with Simplified Cluster Management TORONTO 12/2/2010 Agenda Overview Platform Computing & Fujitsu Partnership PCM Fujitsu Edition Overview o Basic Package o Enterprise Package
Achieving Agility and Flexibility in Big Data Analytics with the Urika -GX Agile Analytics Platform
 Achieving Agility and Flexibility in Big Data Analytics with the Urika -GX Agile Analytics Platform Analytics R&D and Product Management Document Version 1 WP-Urika-GX-Big-Data-Analytics-0217 www.cray.com
Achieving Agility and Flexibility in Big Data Analytics with the Urika -GX Agile Analytics Platform Analytics R&D and Product Management Document Version 1 WP-Urika-GX-Big-Data-Analytics-0217 www.cray.com
February 14, 2006 GSA-WG at GGF16 Athens, Greece. Ignacio Martín Llorente GridWay Project
 February 14, 2006 GSA-WG at GGF16 Athens, Greece GridWay Scheduling Architecture GridWay Project www.gridway.org Distributed Systems Architecture Group Departamento de Arquitectura de Computadores y Automática
February 14, 2006 GSA-WG at GGF16 Athens, Greece GridWay Scheduling Architecture GridWay Project www.gridway.org Distributed Systems Architecture Group Departamento de Arquitectura de Computadores y Automática
Powering Statistical Genetics with the Grid: Using GridWay to Automate R Workflows
 Powering Statistical Genetics with the Grid: Using GridWay to Automate R Workflows John-Paul Robinson Information Technology Purushotham Bangalore Department of Computer Science Jelai Wang, Tapan Mehta
Powering Statistical Genetics with the Grid: Using GridWay to Automate R Workflows John-Paul Robinson Information Technology Purushotham Bangalore Department of Computer Science Jelai Wang, Tapan Mehta
Table of Contents. 1. Executive Summary reasons to use UNICORE. 3. UNICORE Forum e.v. 4. Client Software/Web Portal
 Table of Contents 1. Executive Summary 2. 10 reasons to use UNICORE 3. UNICORE Forum e.v. 4. Client Software/Web Portal 5. Service and Architecture 6. Data Management 7. Workflows June 2016 Executive
Table of Contents 1. Executive Summary 2. 10 reasons to use UNICORE 3. UNICORE Forum e.v. 4. Client Software/Web Portal 5. Service and Architecture 6. Data Management 7. Workflows June 2016 Executive
HPC Solutions. Marc Mendez-Bermond
 HPC Solutions Marc Mendez-Bermond - 2017 50% HPC is mainstreaming into many verticals and converging with big data and Cloud Industry now accounts for almost half of HPC revenue. 1 HPC is moving mainstream.
HPC Solutions Marc Mendez-Bermond - 2017 50% HPC is mainstreaming into many verticals and converging with big data and Cloud Industry now accounts for almost half of HPC revenue. 1 HPC is moving mainstream.
Features and Capabilities. Assess.
 Features and Capabilities Cloudamize is a cloud computing analytics platform that provides high precision analytics and powerful automation to improve the ease, speed, and accuracy of moving to the cloud.
Features and Capabilities Cloudamize is a cloud computing analytics platform that provides high precision analytics and powerful automation to improve the ease, speed, and accuracy of moving to the cloud.
Open Science Grid Ecosystem
 Open Science Grid Ecosystem Consortium Infrastructures Project Satellites Services: Consulting Production Software Mission: The Open Science Grid aims to promote discovery and collaboration in data-intensive
Open Science Grid Ecosystem Consortium Infrastructures Project Satellites Services: Consulting Production Software Mission: The Open Science Grid aims to promote discovery and collaboration in data-intensive
Getting Started with vrealize Operations First Published On: Last Updated On:
 Getting Started with vrealize Operations First Published On: 02-22-2017 Last Updated On: 07-30-2017 1 Table Of Contents 1. Installation and Configuration 1.1.vROps - Deploy vrealize Ops Manager 1.2.vROps
Getting Started with vrealize Operations First Published On: 02-22-2017 Last Updated On: 07-30-2017 1 Table Of Contents 1. Installation and Configuration 1.1.vROps - Deploy vrealize Ops Manager 1.2.vROps
Towards Autonomic Virtual Applications in the In-VIGO System
 Towards Autonomic Virtual Applications in the In-VIGO System Jing Xu, Sumalatha Adabala, José A. B. Fortes Advanced Computing and Information Systems Electrical and Computer Engineering University of Florida
Towards Autonomic Virtual Applications in the In-VIGO System Jing Xu, Sumalatha Adabala, José A. B. Fortes Advanced Computing and Information Systems Electrical and Computer Engineering University of Florida
Grid Activities in KISTI. March 11, 2010 Soonwook Hwang KISTI, Korea
 Grid Activities in KISTI March 11, 2010 Soonwook Hwang KISTI, Korea 1 Outline Grid Operation and Infrastructure KISTI ALICE Tier2 Center FKPPL VO: Production Grid Infrastructure Grid Developments in collaboration
Grid Activities in KISTI March 11, 2010 Soonwook Hwang KISTI, Korea 1 Outline Grid Operation and Infrastructure KISTI ALICE Tier2 Center FKPPL VO: Production Grid Infrastructure Grid Developments in collaboration
Get The Best Out Of Oracle Scheduler
 Get The Best Out Of Oracle Scheduler Vira Goorah Oracle America Redwood Shores CA Introduction Automating the business process is a key factor in reducing IT operating expenses. The need for an effective
Get The Best Out Of Oracle Scheduler Vira Goorah Oracle America Redwood Shores CA Introduction Automating the business process is a key factor in reducing IT operating expenses. The need for an effective
IBM Spectrum Scale. Advanced storage management of unstructured data for cloud, big data, analytics, objects and more. Highlights
 IBM Spectrum Scale Advanced storage management of unstructured data for cloud, big data, analytics, objects and more Highlights Consolidate storage across traditional file and new-era workloads for object,
IBM Spectrum Scale Advanced storage management of unstructured data for cloud, big data, analytics, objects and more Highlights Consolidate storage across traditional file and new-era workloads for object,
2nd EUDAT User Forum
 2nd EUDAT User Forum Data staging to HPC Giuseppe Fiameni SuperComputing, Application and Innovation CINECA, Italy 2nd EUDAT User Forum, London 11, 12 March 2013 Agenda Topic Data Staging to HPC- Conveners:
2nd EUDAT User Forum Data staging to HPC Giuseppe Fiameni SuperComputing, Application and Innovation CINECA, Italy 2nd EUDAT User Forum, London 11, 12 March 2013 Agenda Topic Data Staging to HPC- Conveners:
RDMA Hadoop, Spark, and HBase middleware on the XSEDE Comet HPC resource.
 RDMA Hadoop, Spark, and HBase middleware on the XSEDE Comet HPC resource. Mahidhar Tatineni, SDSC ECSS symposium December 19, 2017 Collaborative project with Dr D.K. Panda s Network Based Computing lab
RDMA Hadoop, Spark, and HBase middleware on the XSEDE Comet HPC resource. Mahidhar Tatineni, SDSC ECSS symposium December 19, 2017 Collaborative project with Dr D.K. Panda s Network Based Computing lab
UAB Condor Pilot UAB IT Research Comptuing June 2012
 UAB Condor Pilot UAB IT Research Comptuing June 2012 The UAB Condor Pilot explored the utility of the cloud computing paradigm to research applications using aggregated, unused compute cycles harvested
UAB Condor Pilot UAB IT Research Comptuing June 2012 The UAB Condor Pilot explored the utility of the cloud computing paradigm to research applications using aggregated, unused compute cycles harvested
How Jukin Media Leverages Metricly for Performance and Capacity Monitoring
 CASE STUDY How Jukin Media Leverages Metricly for Performance and Capacity Monitoring Jukin Media is a global entertainment company powered by user-generated video content. Jukin receives more than 2.5
CASE STUDY How Jukin Media Leverages Metricly for Performance and Capacity Monitoring Jukin Media is a global entertainment company powered by user-generated video content. Jukin receives more than 2.5
How Oracle Uses Fusion Middleware: SOA, BPEL, BI, Identity Management, and ECM Inside Oracle
 ORACLE PRODUCT LOGO How Oracle Uses Fusion Middleware: SOA, BPEL, BI, Identity Management, and ECM Inside Oracle Presenters: Mark Field, VP, Oracle Application Labs Barry Geraghty, IT Director, Oracle
ORACLE PRODUCT LOGO How Oracle Uses Fusion Middleware: SOA, BPEL, BI, Identity Management, and ECM Inside Oracle Presenters: Mark Field, VP, Oracle Application Labs Barry Geraghty, IT Director, Oracle
The IBM and Oracle alliance. Power architecture
 IBM Power Systems, IBM PowerVM and Oracle offerings: a winning combination The smart virtualization platform for IBM AIX, Linux and IBM i clients using Oracle solutions Fostering smart innovation through
IBM Power Systems, IBM PowerVM and Oracle offerings: a winning combination The smart virtualization platform for IBM AIX, Linux and IBM i clients using Oracle solutions Fostering smart innovation through
Clairvoyant Site Allocation of Jobs with Highly Variable Service Demands in a Computational Grid
 Clairvoyant Site Allocation of Jobs with Highly Variable Service Demands in a Computational Grid Stylianos Zikos and Helen Karatza Department of Informatics Aristotle University of Thessaloniki 54124 Thessaloniki,
Clairvoyant Site Allocation of Jobs with Highly Variable Service Demands in a Computational Grid Stylianos Zikos and Helen Karatza Department of Informatics Aristotle University of Thessaloniki 54124 Thessaloniki,
Addressing the I/O bottleneck of HPC workloads. Professor Mark Parsons NEXTGenIO Project Chairman Director, EPCC
 Addressing the I/O bottleneck of HPC workloads Professor Mark Parsons NEXTGenIO Project Chairman Director, EPCC I/O is key Exascale challenge Parallelism beyond 100 million threads demands a new approach
Addressing the I/O bottleneck of HPC workloads Professor Mark Parsons NEXTGenIO Project Chairman Director, EPCC I/O is key Exascale challenge Parallelism beyond 100 million threads demands a new approach
Exalogic Elastic Cloud
 Exalogic Elastic Cloud Mike Piech Oracle San Francisco Keywords: Exalogic Cloud WebLogic Coherence JRockit HotSpot Solaris Linux InfiniBand Introduction For most enterprise IT organizations, years of innovation,
Exalogic Elastic Cloud Mike Piech Oracle San Francisco Keywords: Exalogic Cloud WebLogic Coherence JRockit HotSpot Solaris Linux InfiniBand Introduction For most enterprise IT organizations, years of innovation,
Microsoft Dynamics AX 2012 Day in the life benchmark summary
 Microsoft Dynamics AX 2012 Day in the life benchmark summary In August 2011, Microsoft conducted a day in the life benchmark of Microsoft Dynamics AX 2012 to measure the application s performance and scalability
Microsoft Dynamics AX 2012 Day in the life benchmark summary In August 2011, Microsoft conducted a day in the life benchmark of Microsoft Dynamics AX 2012 to measure the application s performance and scalability
InfoSphere DataStage Grid Solution
 InfoSphere DataStage Grid Solution Julius Lerm IBM Information Management 1 2011 IBM Corporation What is Grid Computing? Grid Computing doesn t mean the same thing to all people. GRID Definitions include:
InfoSphere DataStage Grid Solution Julius Lerm IBM Information Management 1 2011 IBM Corporation What is Grid Computing? Grid Computing doesn t mean the same thing to all people. GRID Definitions include:
DIET: New Developments and Recent Results
 A. Amar 1, R. Bolze 1, A. Bouteiller 1, A. Chis 1, Y. Caniou 1, E. Caron 1, P.K. Chouhan 1, G.L. Mahec 2, H. Dail 1, B. Depardon 1, F. Desprez 1, J. S. Gay 1, A. Su 1 LIP Laboratory (UMR CNRS, ENS Lyon,
A. Amar 1, R. Bolze 1, A. Bouteiller 1, A. Chis 1, Y. Caniou 1, E. Caron 1, P.K. Chouhan 1, G.L. Mahec 2, H. Dail 1, B. Depardon 1, F. Desprez 1, J. S. Gay 1, A. Su 1 LIP Laboratory (UMR CNRS, ENS Lyon,
RODOD Performance Test on Exalogic and Exadata Engineered Systems
 An Oracle White Paper March 2014 RODOD Performance Test on Exalogic and Exadata Engineered Systems Introduction Oracle Communications Rapid Offer Design and Order Delivery (RODOD) is an innovative, fully
An Oracle White Paper March 2014 RODOD Performance Test on Exalogic and Exadata Engineered Systems Introduction Oracle Communications Rapid Offer Design and Order Delivery (RODOD) is an innovative, fully
Cray and Allinea. Maximizing Developer Productivity and HPC Resource Utilization. SHPCP HPC Theater SEG 2016 C O M P U T E S T O R E A N A L Y Z E 1
 Cray and Allinea Maximizing Developer Productivity and HPC Resource Utilization SHPCP HPC Theater SEG 2016 10/27/2016 C O M P U T E S T O R E A N A L Y Z E 1 History Cluster Computing to Super Computing
Cray and Allinea Maximizing Developer Productivity and HPC Resource Utilization SHPCP HPC Theater SEG 2016 10/27/2016 C O M P U T E S T O R E A N A L Y Z E 1 History Cluster Computing to Super Computing
Enabling Resource Sharing between Transactional and Batch Workloads Using Dynamic Application Placement
 Enabling Resource Sharing between Transactional and Batch Workloads Using Dynamic Application Placement David Carrera 1, Malgorzata Steinder 2, Ian Whalley 2, Jordi Torres 1, and Eduard Ayguadé 1 1 Technical
Enabling Resource Sharing between Transactional and Batch Workloads Using Dynamic Application Placement David Carrera 1, Malgorzata Steinder 2, Ian Whalley 2, Jordi Torres 1, and Eduard Ayguadé 1 1 Technical
IBM Accelerating Technical Computing
 IBM Accelerating Jay Muelhoefer WW Marketing Executive, IBM Technical and Platform Computing September 2013 1 HPC and IBM have long history driving research and government innovation Traditional use cases
IBM Accelerating Jay Muelhoefer WW Marketing Executive, IBM Technical and Platform Computing September 2013 1 HPC and IBM have long history driving research and government innovation Traditional use cases
CROWNBench: A Grid Performance Testing System Using Customizable Synthetic Workload
 CROWNBench: A Grid Performance Testing System Using Customizable Synthetic Workload Xing Yang, Xiang Li, Yipeng Ji, and Mo Sha School of Computer Science, Beihang University, Beijing, China {yangxing,
CROWNBench: A Grid Performance Testing System Using Customizable Synthetic Workload Xing Yang, Xiang Li, Yipeng Ji, and Mo Sha School of Computer Science, Beihang University, Beijing, China {yangxing,
Deep Learning Acceleration with
 Deep Learning Acceleration with powered by A Technical White Paper TABLE OF CONTENTS The Promise of AI The Challenges of the AI Lifecycle and Infrastructure MATRIX Powered by Bitfusion Flex Solution Architecture
Deep Learning Acceleration with powered by A Technical White Paper TABLE OF CONTENTS The Promise of AI The Challenges of the AI Lifecycle and Infrastructure MATRIX Powered by Bitfusion Flex Solution Architecture
100 Million Subscriber Performance Test Whitepaper:
 An Oracle White Paper April 2011 100 Million Subscriber Performance Test Whitepaper: Oracle Communications Billing and Revenue Management 7.4 and Oracle Exadata Database Machine X2-8 Oracle Communications
An Oracle White Paper April 2011 100 Million Subscriber Performance Test Whitepaper: Oracle Communications Billing and Revenue Management 7.4 and Oracle Exadata Database Machine X2-8 Oracle Communications
Job Scheduling Challenges of Different Size Organizations
 Job Scheduling Challenges of Different Size Organizations NetworkComputer White Paper 2560 Mission College Blvd., Suite 130 Santa Clara, CA 95054 (408) 492-0940 Introduction Every semiconductor design
Job Scheduling Challenges of Different Size Organizations NetworkComputer White Paper 2560 Mission College Blvd., Suite 130 Santa Clara, CA 95054 (408) 492-0940 Introduction Every semiconductor design
Top 5 Challenges for Hadoop MapReduce in the Enterprise. Whitepaper - May /9/11
 Top 5 Challenges for Hadoop MapReduce in the Enterprise Whitepaper - May 2011 http://platform.com/mapreduce 2 5/9/11 Table of Contents Introduction... 2 Current Market Conditions and Drivers. Customer
Top 5 Challenges for Hadoop MapReduce in the Enterprise Whitepaper - May 2011 http://platform.com/mapreduce 2 5/9/11 Table of Contents Introduction... 2 Current Market Conditions and Drivers. Customer
Moab and TORQUE Achieve High Utilization of Flagship NERSC XT4 System
 Moab and TORQUE Achieve High Utilization of Flagship NERSC XT4 System Michael Jackson, President Cluster Resources michael@clusterresources.com +1 (801) 717-3722 Cluster Resources, Inc. Contents 1. Introduction
Moab and TORQUE Achieve High Utilization of Flagship NERSC XT4 System Michael Jackson, President Cluster Resources michael@clusterresources.com +1 (801) 717-3722 Cluster Resources, Inc. Contents 1. Introduction
Delivering High Performance for Financial Models and Risk Analytics
 QuantCatalyst Delivering High Performance for Financial Models and Risk Analytics September 2008 Risk Breakfast London Dr D. Egloff daniel.egloff@quantcatalyst.com QuantCatalyst Inc. Technology and software
QuantCatalyst Delivering High Performance for Financial Models and Risk Analytics September 2008 Risk Breakfast London Dr D. Egloff daniel.egloff@quantcatalyst.com QuantCatalyst Inc. Technology and software
Oracle Financial Services Revenue Management and Billing V2.3 Performance Stress Test on Exalogic X3-2 & Exadata X3-2
 Oracle Financial Services Revenue Management and Billing V2.3 Performance Stress Test on Exalogic X3-2 & Exadata X3-2 O R A C L E W H I T E P A P E R J A N U A R Y 2 0 1 5 Table of Contents Disclaimer
Oracle Financial Services Revenue Management and Billing V2.3 Performance Stress Test on Exalogic X3-2 & Exadata X3-2 O R A C L E W H I T E P A P E R J A N U A R Y 2 0 1 5 Table of Contents Disclaimer
Grid 2.0 : Entering the new age of Grid in Financial Services
 Grid 2.0 : Entering the new age of Grid in Financial Services Charles Jarvis, VP EMEA Financial Services June 5, 2008 Time is Money! The Computation Homegrown Applications ISV Applications Portfolio valuation
Grid 2.0 : Entering the new age of Grid in Financial Services Charles Jarvis, VP EMEA Financial Services June 5, 2008 Time is Money! The Computation Homegrown Applications ISV Applications Portfolio valuation
Sizing SAP Central Process Scheduling 8.0 by Redwood
 Sizing SAP Central Process Scheduling 8.0 by Redwood Released for SAP Customers and Partners January 2012 Copyright 2012 SAP AG. All rights reserved. No part of this publication may be reproduced or transmitted
Sizing SAP Central Process Scheduling 8.0 by Redwood Released for SAP Customers and Partners January 2012 Copyright 2012 SAP AG. All rights reserved. No part of this publication may be reproduced or transmitted
CPU scheduling. CPU Scheduling
 EECS 3221 Operating System Fundamentals No.4 CPU scheduling Prof. Hui Jiang Dept of Electrical Engineering and Computer Science, York University CPU Scheduling CPU scheduling is the basis of multiprogramming
EECS 3221 Operating System Fundamentals No.4 CPU scheduling Prof. Hui Jiang Dept of Electrical Engineering and Computer Science, York University CPU Scheduling CPU scheduling is the basis of multiprogramming
OPERATING SYSTEMS. Systems and Models. CS 3502 Spring Chapter 03
 OPERATING SYSTEMS CS 3502 Spring 2018 Systems and Models Chapter 03 Systems and Models A system is the part of the real world under study. It is composed of a set of entities interacting among themselves
OPERATING SYSTEMS CS 3502 Spring 2018 Systems and Models Chapter 03 Systems and Models A system is the part of the real world under study. It is composed of a set of entities interacting among themselves
WHITE PAPER. CA Nimsoft APIs. keys to effective service management. agility made possible
 WHITE PAPER CA Nimsoft APIs keys to effective service management agility made possible table of contents Introduction 3 CA Nimsoft operational APIs 4 Data collection APIs and integration points Message
WHITE PAPER CA Nimsoft APIs keys to effective service management agility made possible table of contents Introduction 3 CA Nimsoft operational APIs 4 Data collection APIs and integration points Message
Integration of Titan supercomputer at OLCF with ATLAS Production System
 Integration of Titan supercomputer at OLCF with ATLAS Production System F. Barreiro Megino 1, K. De 1, S. Jha 2, A. Klimentov 3, P. Nilsson 3, D. Oleynik 1, S. Padolski 3, S. Panitkin 3, J. Wells 4 and
Integration of Titan supercomputer at OLCF with ATLAS Production System F. Barreiro Megino 1, K. De 1, S. Jha 2, A. Klimentov 3, P. Nilsson 3, D. Oleynik 1, S. Padolski 3, S. Panitkin 3, J. Wells 4 and
This presentation is for informational purposes only and may not be incorporated into a contract or agreement.
 This presentation is for informational purposes only and may not be incorporated into a contract or agreement. The following is intended to outline our general product direction. It is intended for information
This presentation is for informational purposes only and may not be incorporated into a contract or agreement. The following is intended to outline our general product direction. It is intended for information
ORACLE CLOUD MANAGEMENT PACK FOR MIDDLEWARE
 ORACLE CLOUD MANAGEMENT PACK FOR MIDDLEWARE Oracle Enterprise Manager is Oracle s strategic integrated enterprise IT management product line. It provides the industry s first complete cloud lifecycle management
ORACLE CLOUD MANAGEMENT PACK FOR MIDDLEWARE Oracle Enterprise Manager is Oracle s strategic integrated enterprise IT management product line. It provides the industry s first complete cloud lifecycle management
Using and Managing a Linux Cluster as a Server
 Using and Managing a Linux Cluster as a Server William Lu, Ph.D. 1 Cluster A cluster is complex To remove burden from users, IHV typically delivers the entire cluster as a system Some system is delivered
Using and Managing a Linux Cluster as a Server William Lu, Ph.D. 1 Cluster A cluster is complex To remove burden from users, IHV typically delivers the entire cluster as a system Some system is delivered
A Hybrid Scheduling Approach for Scalable Heterogeneous Hadoop Systems
 A Hybrid Scheduling Approach for Scalable Heterogeneous Hadoop Systems Aysan Rasooli Department of Computing and Software McMaster University Hamilton, Canada Email: rasooa@mcmaster.ca Douglas G. Down
A Hybrid Scheduling Approach for Scalable Heterogeneous Hadoop Systems Aysan Rasooli Department of Computing and Software McMaster University Hamilton, Canada Email: rasooa@mcmaster.ca Douglas G. Down
Oracle Cloud Blueprint and Roadmap Service. 1 Copyright 2012, Oracle and/or its affiliates. All rights reserved.
 Oracle Cloud Blueprint and Roadmap Service 1 Copyright 2012, Oracle and/or its affiliates. All rights reserved. Cloud Computing: Addressing Today s Business Challenges Business Flexibility & Agility Cost
Oracle Cloud Blueprint and Roadmap Service 1 Copyright 2012, Oracle and/or its affiliates. All rights reserved. Cloud Computing: Addressing Today s Business Challenges Business Flexibility & Agility Cost
ETL on Hadoop What is Required
 ETL on Hadoop What is Required Keith Kohl Director, Product Management October 2012 Syncsort Copyright 2012, Syncsort Incorporated Agenda Who is Syncsort Extract, Transform, Load (ETL) Overview and conventional
ETL on Hadoop What is Required Keith Kohl Director, Product Management October 2012 Syncsort Copyright 2012, Syncsort Incorporated Agenda Who is Syncsort Extract, Transform, Load (ETL) Overview and conventional
HPC Workload Management Tools: Tech Brief Update
 89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com @EdisonGroupInc 212.367.7400 HPC Workload Management Tools: Tech Brief Update IBM Platform LSF Meets Evolving High Performance Computing
89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com @EdisonGroupInc 212.367.7400 HPC Workload Management Tools: Tech Brief Update IBM Platform LSF Meets Evolving High Performance Computing
Services Guide April The following is a description of the services offered by PriorIT Consulting, LLC.
 SERVICES OFFERED The following is a description of the services offered by PriorIT Consulting, LLC. Service Descriptions: Strategic Planning: An enterprise GIS implementation involves a considerable amount
SERVICES OFFERED The following is a description of the services offered by PriorIT Consulting, LLC. Service Descriptions: Strategic Planning: An enterprise GIS implementation involves a considerable amount
Communication-Aware Job Placement Policies for the KOALA Grid Scheduler
 Communication-Aware Job Placement Policies for the KOALA Grid Scheduler Ozan Sonmez, Hashim Mohamed, Dick Epema Dept. of Computer Science, Delft University of Technology e-mail: {O.O.Sonmez,H.H.Mohamed,D.H.J.Epema}@tudelft.nl
Communication-Aware Job Placement Policies for the KOALA Grid Scheduler Ozan Sonmez, Hashim Mohamed, Dick Epema Dept. of Computer Science, Delft University of Technology e-mail: {O.O.Sonmez,H.H.Mohamed,D.H.J.Epema}@tudelft.nl
Learn How To Implement Cloud on System z. Delivering and optimizing private cloud on System z with Integrated Service Management
 Learn How To Implement Cloud on System z Delivering and optimizing private cloud on System z with Integrated Service Mike Baskey, Distinguished Engineer, Tivoli z Architecture IBM August 9th, 2012 Session:
Learn How To Implement Cloud on System z Delivering and optimizing private cloud on System z with Integrated Service Mike Baskey, Distinguished Engineer, Tivoli z Architecture IBM August 9th, 2012 Session:
CMS readiness for multi-core workload scheduling
 CMS readiness for multi-core workload scheduling Antonio Pérez-Calero Yzquierdo, on behalf of the CMS Collaboration, Computing and Offline, Submission Infrastructure Group CHEP 2016 San Francisco, USA
CMS readiness for multi-core workload scheduling Antonio Pérez-Calero Yzquierdo, on behalf of the CMS Collaboration, Computing and Offline, Submission Infrastructure Group CHEP 2016 San Francisco, USA
ORACLE DATABASE PERFORMANCE: VMWARE CLOUD ON AWS PERFORMANCE STUDY JULY 2018
 ORACLE DATABASE PERFORMANCE: VMWARE CLOUD ON AWS PERFORMANCE STUDY JULY 2018 Table of Contents Executive Summary...3 Introduction...3 Test Environment... 4 Test Workload... 6 Virtual Machine Configuration...
ORACLE DATABASE PERFORMANCE: VMWARE CLOUD ON AWS PERFORMANCE STUDY JULY 2018 Table of Contents Executive Summary...3 Introduction...3 Test Environment... 4 Test Workload... 6 Virtual Machine Configuration...
I/O Performance and I/O Performance Isolation
 I/O Performance and I/O Performance Isolation Sarala Arunagiri Representing the DAiSES Project at The University of Texas at El Paso 17 April 2007 HiPCAT Meeting at UTEP 1 Outline of the Talk What is I/O
I/O Performance and I/O Performance Isolation Sarala Arunagiri Representing the DAiSES Project at The University of Texas at El Paso 17 April 2007 HiPCAT Meeting at UTEP 1 Outline of the Talk What is I/O
In Cloud, Do MTC or HTC Service Providers Benefit from the Economies of Scale?
 In Cloud, Do MTC or HTC Service Providers Benefit from the Economies of Scale? Lei Wang, Jianfeng Zhan Chinese Academy of Sciences {wl, jfzhan}@ncic.ac.cn Weisong Shi Wayne State University weisong@wayne.edu
In Cloud, Do MTC or HTC Service Providers Benefit from the Economies of Scale? Lei Wang, Jianfeng Zhan Chinese Academy of Sciences {wl, jfzhan}@ncic.ac.cn Weisong Shi Wayne State University weisong@wayne.edu
Job co-allocation strategies for multiple high performance computing clusters
 Cluster Comput (2009) 12: 323 340 DOI 10.1007/s10586-009-0087-x Job co-allocation strategies for multiple high performance computing clusters Jinhui Qin Michael A. Bauer Received: 28 April 2008 / Accepted:
Cluster Comput (2009) 12: 323 340 DOI 10.1007/s10586-009-0087-x Job co-allocation strategies for multiple high performance computing clusters Jinhui Qin Michael A. Bauer Received: 28 April 2008 / Accepted:
OpenWLC: A Workload Characterization System. Hong Ong, Rajagopal Subramaniyan, R. Scott Studham ORNL July 19, 2005
 OpenWLC: A Workload Characterization System Hong Ong, Rajagopal Subramaniyan, R. Scott Studham ORNL July 19, 2005 Outline Background and Motivation Existing Tools and Services NWPerf OpenWLC Overview Goals
OpenWLC: A Workload Characterization System Hong Ong, Rajagopal Subramaniyan, R. Scott Studham ORNL July 19, 2005 Outline Background and Motivation Existing Tools and Services NWPerf OpenWLC Overview Goals
Azure Stack. Unified Application Management on Azure and Beyond
 Azure Stack Unified Application Management on Azure and Beyond Table of Contents Introduction...3 Deployment Models...4 Dedicated On-Premise Cloud... 4 Shared Application Hosting... 4 Extended Hosting
Azure Stack Unified Application Management on Azure and Beyond Table of Contents Introduction...3 Deployment Models...4 Dedicated On-Premise Cloud... 4 Shared Application Hosting... 4 Extended Hosting
A Practice of Cloud Computing for HPC & Other Applications. Matthew Huang Sun Microsystems, a subsidiary of Oracle Corp.
 A Practice of Cloud Computing for HPC & Other Applications Matthew Huang Sun Microsystems, a subsidiary of Oracle Corp. matthew.huang@sun.com 1 IT Transformation to Cloud Computing 2 Example: NY Times
A Practice of Cloud Computing for HPC & Other Applications Matthew Huang Sun Microsystems, a subsidiary of Oracle Corp. matthew.huang@sun.com 1 IT Transformation to Cloud Computing 2 Example: NY Times
White paper A Reference Model for High Performance Data Analytics(HPDA) using an HPC infrastructure
 using an HPC infrastructure") White paper A Reference Model for High Performance Data Analytics(HPDA) using an HPC infrastructure Discover how to reshape an existing HPC infrastructure to run High Performance Data Analytics (HPDA)
White paper A Reference Model for High Performance Data Analytics(HPDA) using an HPC infrastructure Discover how to reshape an existing HPC infrastructure to run High Performance Data Analytics (HPDA)
ECLIPSE 2012 Performance Benchmark and Profiling. August 2012
 ECLIPSE 2012 Performance Benchmark and Profiling August 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
ECLIPSE 2012 Performance Benchmark and Profiling August 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Architecting Microsoft Azure Solutions
 Architecting Microsoft Azure Solutions 20535A; 5 Days; Instructor-led Course Description This course is intended for architects who have experience building infrastructure and applications on the Microsoft
Architecting Microsoft Azure Solutions 20535A; 5 Days; Instructor-led Course Description This course is intended for architects who have experience building infrastructure and applications on the Microsoft
On the Comparison of CPLEX-Computed Job Schedules with the Self-Tuning dynp Job Scheduler
 On the Comparison of CPLEX-Computed Job Schedules with the Self-Tuning dynp Job Scheduler Sven Grothklags 1 and Achim Streit 2 1 Faculty of Computer Science, Electrical Engineering and Mathematics, Institute
On the Comparison of CPLEX-Computed Job Schedules with the Self-Tuning dynp Job Scheduler Sven Grothklags 1 and Achim Streit 2 1 Faculty of Computer Science, Electrical Engineering and Mathematics, Institute
Optimizing Fine-grained Communication in a Biomolecular Simulation Application on Cray XK6
 Optimizing Fine-grained Communication in a Biomolecular Simulation Application on Cray XK6 Yanhua Sun 1 Gengbin Zheng 1 Chao Mei 1 Eric J. Bohm 1 James C. Phillips 1 Terry Jones 2 Laxmikant(Sanjay) V.
Optimizing Fine-grained Communication in a Biomolecular Simulation Application on Cray XK6 Yanhua Sun 1 Gengbin Zheng 1 Chao Mei 1 Eric J. Bohm 1 James C. Phillips 1 Terry Jones 2 Laxmikant(Sanjay) V.
Load DynamiX Enterprise 5.2
 ENTERPRISE DATASHEET TECHNOLOGY VENDORS Load DynamiX Enterprise 5.2 The industry s only collaborative workload acquisition, modeling and performance validation solution for storage technology vendors Key
ENTERPRISE DATASHEET TECHNOLOGY VENDORS Load DynamiX Enterprise 5.2 The industry s only collaborative workload acquisition, modeling and performance validation solution for storage technology vendors Key
locuz.com Unified HPC Cluster Manager
 locuz.com Unified HPC Cluster Manager Ganana Cluster Manager makes it easier for Admins to build Linux based HPC Cluster, and to easily manage their clusters on any x64 hardware. The web-based Portal is
locuz.com Unified HPC Cluster Manager Ganana Cluster Manager makes it easier for Admins to build Linux based HPC Cluster, and to easily manage their clusters on any x64 hardware. The web-based Portal is
AI-Ckpt: Leveraging Memory Access Patterns for Adaptive Asynchronous Incremental Checkpointing
 AI-Ckpt: Leveraging Memory Access Patterns for Adaptive Asynchronous Incremental Checkpointing Bogdan Nicolae, Franck Cappello IBM Research Ireland Argonne National Lab USA IBM Corporation Outline Overview
AI-Ckpt: Leveraging Memory Access Patterns for Adaptive Asynchronous Incremental Checkpointing Bogdan Nicolae, Franck Cappello IBM Research Ireland Argonne National Lab USA IBM Corporation Outline Overview
Planning the Capacity of a Web Server: An Experience Report D. Menascé. All Rights Reserved.
 Planning the Capacity of a Web Server: An Experience Report Daniel A. Menascé George Mason University menasce@cs.gmu.edu Nikki Dinh SRA International, Inc. nikki_dinh@sra.com Robert Peraino George Mason
Planning the Capacity of a Web Server: An Experience Report Daniel A. Menascé George Mason University menasce@cs.gmu.edu Nikki Dinh SRA International, Inc. nikki_dinh@sra.com Robert Peraino George Mason
Oracle Cloud for the Enterprise John Mishriky Director, NAS Strategy & Business Development
 % Oracle Cloud for the Enterprise John Mishriky Director, NAS Strategy & Business Development john.mishriky@oracle.com Right Solution. Right Time. What We Built An Enterprise Cloud An integrated platform
% Oracle Cloud for the Enterprise John Mishriky Director, NAS Strategy & Business Development john.mishriky@oracle.com Right Solution. Right Time. What We Built An Enterprise Cloud An integrated platform
IBM WebSphere Front Office for Financial Markets delivers a flexible, high-throughput, low-latency, front-office platform
 Software Announcement June 27, 2006 IBM WebSphere Front Office for Financial Markets delivers a flexible, high-throughput, low-latency, front-office platform Overview WebSphere Front Office for Financial
Software Announcement June 27, 2006 IBM WebSphere Front Office for Financial Markets delivers a flexible, high-throughput, low-latency, front-office platform Overview WebSphere Front Office for Financial
IBM Tivoli Monitoring
 Monitor and manage critical resources and metrics across disparate platforms from a single console IBM Tivoli Monitoring Highlights Proactively monitor critical components Help reduce total IT operational
Monitor and manage critical resources and metrics across disparate platforms from a single console IBM Tivoli Monitoring Highlights Proactively monitor critical components Help reduce total IT operational
Comparing Application Performance on HPC-based Hadoop Platforms with Local Storage and Dedicated Storage
 Comparing Application Performance on HPC-based Hadoop Platforms with Local Storage and Dedicated Storage Zhuozhao Li *, Haiying Shen *, Jeffrey Denton and Walter Ligon * Department of Computer Science,
Comparing Application Performance on HPC-based Hadoop Platforms with Local Storage and Dedicated Storage Zhuozhao Li *, Haiying Shen *, Jeffrey Denton and Walter Ligon * Department of Computer Science,
Ch. 6: Understanding and Characterizing the Workload
 Ch. 6: Understanding and Characterizing the Workload Kenneth Mitchell School of Computing & Engineering, University of Missouri-Kansas City, Kansas City, MO 64110 Kenneth Mitchell, CS & EE dept., SCE,
Ch. 6: Understanding and Characterizing the Workload Kenneth Mitchell School of Computing & Engineering, University of Missouri-Kansas City, Kansas City, MO 64110 Kenneth Mitchell, CS & EE dept., SCE,
An IBM Proof of Technology IBM Workload Deployer Overview
 An IBM Proof of Technology IBM Workload Deployer Overview WebSphere Infrastructure: The Big Picture Vertically integrated and horizontally fit for purpose Operational Management & Efficiency IBM Workload
An IBM Proof of Technology IBM Workload Deployer Overview WebSphere Infrastructure: The Big Picture Vertically integrated and horizontally fit for purpose Operational Management & Efficiency IBM Workload
PRIORITY BASED SCHEDULING IN CLOUD COMPUTING BASED ON TASK AWARE TECHNIQUE
 RESEARCH ARTICLE OPEN ACCESS PRIORITY BASED SCHEDULING IN CLOUD COMPUTING BASED ON TASK AWARE TECHNIQUE Jeevithra.R *, Karthikeyan.T ** * (M.Phil Computer Science Student Department of Computer Science)
RESEARCH ARTICLE OPEN ACCESS PRIORITY BASED SCHEDULING IN CLOUD COMPUTING BASED ON TASK AWARE TECHNIQUE Jeevithra.R *, Karthikeyan.T ** * (M.Phil Computer Science Student Department of Computer Science)
SCALARi500. SCALAR i500. The Intelligent Midrange Library Platform FEATURES AND BENEFITS
 Intelligent Storage SCALARi500 SCALAR i500 The Intelligent Midrange Library Platform 1 TO 18 DRIVES 36 TO 404 CARTRIDGES MODULAR GROWTH, CONTINUOUS ROBOTICS CAPACITY-ON-DEMAND iplatform ARCHITECTURE AND
Intelligent Storage SCALARi500 SCALAR i500 The Intelligent Midrange Library Platform 1 TO 18 DRIVES 36 TO 404 CARTRIDGES MODULAR GROWTH, CONTINUOUS ROBOTICS CAPACITY-ON-DEMAND iplatform ARCHITECTURE AND
SAFE Resources. SAFE User Guide
 SAFE User Guide SAFE (Secure Access For Everyone) is a well-coordinated, usable, federated identity and access management system that supports trusted collaboration and sharing of compute and data resources
SAFE User Guide SAFE (Secure Access For Everyone) is a well-coordinated, usable, federated identity and access management system that supports trusted collaboration and sharing of compute and data resources
Optimizing Grid-Based Workflow Execution
 Journal of Grid Computing (2006) 3: 201 219 # Springer 2006 DOI: 10.1007/s10723-005-9011-7 Optimizing Grid-Based Workflow Execution Gurmeet Singh j, Carl Kesselman and Ewa Deelman Information Sciences
Journal of Grid Computing (2006) 3: 201 219 # Springer 2006 DOI: 10.1007/s10723-005-9011-7 Optimizing Grid-Based Workflow Execution Gurmeet Singh j, Carl Kesselman and Ewa Deelman Information Sciences
UAB Expanding the Campus Compu7ng Cloud
 Condor @ UAB Expanding the Campus Compu7ng Cloud Condor Week 2012 John- Paul Robinson jpr@uab.edu Poornima Pochana ppreddy@uab.edu Thomas Anthony tanthony@uab.edu Public University with 17,571 Student
Condor @ UAB Expanding the Campus Compu7ng Cloud Condor Week 2012 John- Paul Robinson jpr@uab.edu Poornima Pochana ppreddy@uab.edu Thomas Anthony tanthony@uab.edu Public University with 17,571 Student
ACCELERATING GENOMIC ANALYSIS ON THE CLOUD. Enabling the PanCancer Analysis of Whole Genomes (PCAWG) consortia to analyze thousands of genomes
 consortia to analyze thousands of genomes") ACCELERATING GENOMIC ANALYSIS ON THE CLOUD Enabling the PanCancer Analysis of Whole Genomes (PCAWG) consortia to analyze thousands of genomes Enabling the PanCancer Analysis of Whole Genomes (PCAWG) consortia
ACCELERATING GENOMIC ANALYSIS ON THE CLOUD Enabling the PanCancer Analysis of Whole Genomes (PCAWG) consortia to analyze thousands of genomes Enabling the PanCancer Analysis of Whole Genomes (PCAWG) consortia
Architecting Microsoft Azure Solutions
 Course 20535: Architecting Microsoft Azure Solutions Page 1 of 8 Architecting Microsoft Azure Solutions Course 20535: 4 days; Instructor-Led Introduction This course is intended for architects who have
Course 20535: Architecting Microsoft Azure Solutions Page 1 of 8 Architecting Microsoft Azure Solutions Course 20535: 4 days; Instructor-Led Introduction This course is intended for architects who have