RNA-seq data analysis. Eija Korpelainen, Maria Lehtivaara CSC IT Center for Science, Finland
|
|
|
- Coleen Hill
- 5 years ago
- Views:
Transcription
1 RNA-seq data analysis Eija Korpelainen, Maria Lehtivaara CSC IT Center for Science, Finland
2 Understanding data analysis - why? Bioinformaticians might not always be available when needed Biologists know their own experiments best Biology involved (e.g. genes, pathways, etc) Potential batch effects etc Allows you to design experiments better Enough replicates, reads etc less money wasted Allows you to discuss more easily with bioinformaticians
3 What will I learn? Introduction to RNA sequencing How to operate the Chipster software used in the exercises RNA-seq data analysis Central concepts Analysis steps File formats Things to take into account when designing experiments
4 Introduction to RNA-seq
5 What can I investigate with RNA-seq? Differential expression Isoform switching New genes and isoforms New transcript(ome)s Variants Allele-specific expression Etc etc

6 Is RNA-seq better than microarrays? + Wider detection range + Can detect new genes and isoforms - Data analysis is not as established as for microarrays - Data is voluminous
7 Development of sequencing methods


8 Sequencing technologies Sequencing by synthesis Illumina Pyrosequencing Sanger, 454 Ion semiconductor sequencing Ion Proton Sequencing by ligation SOLiD system Single molecule real time sequencing PacBio Illumina MiSeq Illumina HiSeq 454 Sequencer SOLiD system Ion Proton PacBio
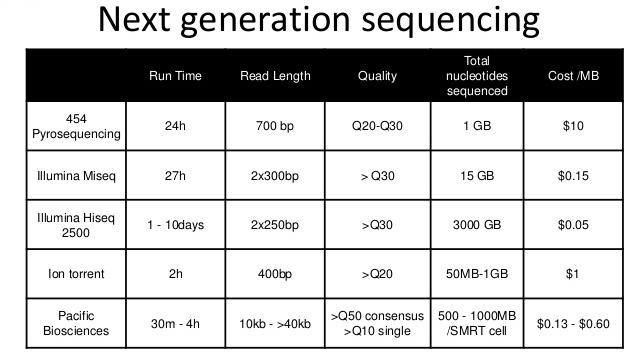
9




10 Semiconductor sequencing Ion Proton / Ion Torrent /Illumina


11 How was the data produced? Isolate RNAs -generate cdna -amplify -fragment -size select -add adapters Samples (replicates) RNA Data analysis DNA fragments with adapters Raw data TGCTAC AATGCG GTGACA CACTAG Reads (FASTQ files) sequencing sequencer

")


12 Sequencing by synthesis (Illumina) cluster flow cell flow cell 1 sequencing cycle = 1 base
 1)")


13 Sequencing by synthesis (Illumina) From images to FASTQ file 2) Intensity table (4 values for each cluster & each cycle) 1) Image files (4 images per cycle) FASTQ name 3) FASTQ file with the read sequences & quality values for each base GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT + read name!''*((((***+))%%%++)(%%%%).1***-+*''))**55ccf>>>>>>ccccccc65

14 Sequencing by synthesis (Illumina) Now, how the flowcell and cluster ACTUALLY look like
15 Illumina devices What is it How long Reads per Max read Lanes good for it takes run lengt (bp) MiSeq MiSeq (microbes, Microbes, viruses, 4-55 h targeted 25 Mpanels) 4-55 viruses, h targeted 25 M reads per run panels max. 2 x 300 bp 2 x NextSeq (exomes, transcriptomes) NextSeq Exomes, h 400 M 2 x transcripto h (all 400 mes M reads per run samples to 4 lanes (each sample goes to all 4 lanes) all 4 lanes) HiSeq 2500 max. Whole 2 x 150 bp Up to 6 HiSeq 2500 genomes (whole genomes) days Up to 6 days max. 2 x 250 bp 300 M 4 G NovaSeq 300 Whole M 4 G reads 20 per 40 run h G 2 x 150 (2017) genomes, scalable 2 x (different samples to different lanes)
16 How was the data produced? Isolate RNAs -generate cdna -amplify -fragment -size select -add adapters Samples (replicates) RNA Data analysis DNA fragments with adapters Raw data TGCTAC AATGCG GTGACA CACTAG Reads (FASTQ files) sequencing sequencer
17 How was your data produced? PolyA purification cdna generation & fragmentation Library construction Size selection
18 Illumina Tru-Seq stranded protocol As an example
19 When planning an experiment, consider The number of biological replicates needed. Depends on Biological variability and technical noise Expression level, fold change and sequencing depth Sample pairing Sequencing decisions Number of reads per sample (~sequencing depth) Read length (longer is better) Paired end or single end (PE is better) Stranded or un-stranded (stranded is better) Batch effects
20 Relevant concepts Read depth = coverage = how many reads per each nucleotide, on average? Read length? bp? Paired end, single end? Sequencing capacity = how many cycles, how many reads per flow cell, how many lanes in the flow cell? => depends on the device. Heterogeneity of the sample material (cell line vs. tumor sample)
, 20-40 M (broad) https://genohub.")
21 Coverage Whole Genome Sequencing (WGS): Genotype calls 35x, INDELs 60x, SNVs 30x RNASeq: Differential expression profiling M reads, allele specific expression M Alternative splicing M De novo assembly >100 M ChiP-Seq: M (sharp peaks), M (broad)

22 Paired-end vs single-end reads Insert length

 Read 1: CGTGGATCACTCGCTACTGCACTACGACTACGACA Read")
23 Read length = number of sequencing cycles mrna molecule (3000 bases) ACTCACGTGTACGTAGCTAGTTTACGACTGACTCGCAGTAC ATGCGCTCGTGGATCACTCGCTACTGCACTACGACTACGACAT ATCAGCGGCATCGTGATCGGGCATGCATCGTACGCACTGATA TACGCATAATCAGCTACGATCAGCATTATTCACCTACTATCACTC CACATCACTTTAACCTGCGGGACTGACGTGACGTCACAAAAA mrna fragment (500 bases) ADAPTER-CGTGGATCACTCGCTACTGCACTACGACTACGACAT ATCAGCGGCATCGTGATCGGGCATGCATCGTACGCACTGATA TACGCATAATCAGCTACGATCAGCATTAT-ADAPTER Reads (100 bases each) Read 1: CGTGGATCACTCGCTACTGCACTACGACTACGACA Read 2: CTGATATACGCATAATCAGCTACGATCAGCATTATA Question: In our example, what is the insert length? insert

24 Strandedness Several methods Stranded/directional method = you have the information of which strand the sequence originally came from
25 Introduction to Chipster
26 Chipster Provides an easy access to over 360 analysis tools Command line tools R/Bioconductor packages Free, open source software What can I do with Chipster? analyze and integrate high-throughput data visualize data efficiently share analysis sessions save and share automatic workflows
27 Technical aspects Client-server system Enough CPU and memory for large analysis jobs Centralized maintenance Easy to install Client uses Java Web Start Server available as a virtual machine
28

29

30 Mode of operation Select: data tool category tool run visualize

31 Job manager You can run many analysis jobs at the same time Use Job manager to view status cancel jobs view time view parameters

32 Analysis history is saved automatically -you can add tool source code to reports if needed
33 Analysis sessions Remember to save the analysis session. Session includes all the files, their relationships and metadata (what tool and parameters were used to produce each file). Session is a single.zip file. You can save a session locally (on your computer) and in the cloud but note that the cloud sessions are not stored forever!
")
34 Workflow panel Shows the relationships of the files You can move the boxes around, and zoom in and out. Several files can be selected by keeping the Ctrl key down Right clicking on the data file allows you to Save an individual result file ( Export ) Delete Link to another data file Save workflow
35 Workflow reusing and sharing your analysis pipeline You can save your analysis steps as a reusable automatic macro, which you can apply to another dataset When you save a workflow, all the analysis steps and their parameters are saved as a script file, which you can share with other users

36 Saving and using workflows Select the starting point for your workflow Select Workflow/ Save starting from selected Save the workflow file on your computer with a meaningful name Don t change the ending (.bsh) To run a workflow, select Workflow->Open and run Workflow->Run recent (if you saved the workflow recently).
37 Analysis tools 160 NGS tools for 140 microarray tools for RNA-seq gene expression mirna-seq mirna expression exome/genome-seq protein expression ChIP-seq acgh FAIRE/DNase-seq SNP CNA-seq integration of different data 16S rrna sequencing Single cell RNA-seq 60 tools for sequence analysis BLAST, EMBOSS, MAFFT Phylip


38 Tools for QC, processing and mapping FastQC PRINSEQ FastX TagCleaner Trimmomatic Bowtie HISAT2 BWA Picard SAMtools BEDTools



39 RNA-seq tools Quality control RseQC Counting HTSeq express Transcript discovery Cufflinks Differential expression edger DESeq Cuffdiff DEXSeq Pathway analysis ConsensusPathDB

40 Virus detection tools for srna-seq data VirusDetect pipeline BWA Samtools Velvet BLAST
41 mirna-seq tools Differential expression edger DESeq Retrieve target genes PicTar mirbase TargetScan miranda Pathway analysis for targets GO KEGG Correlate mirna and target expression
 Variant Effect")
42 Exome/genome-seq tools Variant calling Samtools, bcftools GATK coming soon Variant filtering and reporting VCFtools Variant annotation AnnotateVariant (Bioconductor) Variant Effect Predictor


43 ChIP-seq and DNase-seq tools Peak detection MACS F-seq Peak filtering P-value, no of reads, length Detect motifs, match to JASPAR MotIV, rgadem Dimont Retrieve nearby genes Pathway analysis GO, ConsensusPathDB
44 CNA-seq tools Count reads in bins Correct for GC content Segment and call CNA Filter for mappability Plot profiles Group comparisons Clustering Detect genes in CNA GO enrichment Integrate with expression
45 Metagenomics / 16 S rrna tools Taxonomy assignment with Mothur package Align reads to 16 S rrna template Filter alignment for empty columns Keep unique aligned reads Precluster aligned reads Remove chimeric reads Classify reads to taxonomic units Statistical analyses using R Compare diversity or abundance between groups using several ANOVA-type of analyses
46 Visualizing the data Data visualization panel Maximize and redraw for better viewing Detach = open in a separate window, allows you to view several images at the same time Two types of visualizations 1. Interactive visualizations produced by the client program Select the visualization method from the pulldown menu Save by right clicking on the image 2. Static images produced by analysis tools Select from Analysis tools/ Visualisation View by double clicking on the image file Save by right clicking on the file name and choosing Export

47 Interactive visualizations by the client Genome browser Spreadsheet Histogram Venn diagram Scatterplot 3D scatterplot Volcano plot Expression profiles Clustered profiles Hierarchical clustering SOM clustering Available actions: Select genes and create a gene list Change titles, colors etc Zoom in/out

48
49 Static images produced by R/Bioconductor Dispersion plot MA plot MDS plot Box plot Histogram Heatmap Idiogram Chromosomal position Correlogram Dendrogram K-means clustering SOM-clustering etc
50 Options for importing data to Chipster Import files/ Import folder Import from URL Utilities / Download file from URL directly to server Open an analysis session Files / Open session Import from SRA database Utilities / Retrieve FASTQ or BAM files from SRA Import from Ensembl database Utilities / Retrieve data for a given organism in Ensembl What kind of RNA-seq data files can I use in Chipster? Compressed files (.gz) are ok FASTQ, BAM, read count files (.tsv), GTF

51 Problems? Send us a support request -request includes the error message and link to analysis session (optional)

52 Acknowledgements to Chipster users and contibutors

53 More info Chipster tutorials in YouTube
54 RNA-seq data analysis
55 Control 1 Control 2 Control 3 Sample 1 Sample 2 Sample 3 RNA-seq data analysis: typical steps Raw data (reads) Align reads to reference genome Gene A Gene B Match alignment positions with known gene positions A = 6 B = 11 Count how many reads each gene has Gene A Gene B Gene C Gene D Compare sample groups: differential expression analysis
56 Control 1 Control 2 Control 3 Sample 1 Sample 2 Sample 3 RNA-seq data analysis: steps, tools and files STEP TOOL FILE Quality control FastQC FASTQ FASTQ FASTQ Preprocessing Trimmomatic FASTQ FASTQ FASTQ Alignment HISAT2 BAM BAM BAM gene A gene B Quality control Quantitation RSeQC HTSeq Read Read count file Read count file (TSV) count file (TSV) (TSV) Combine count files to table Define NGS experiment Read count table (TSV) Gene A Quality control PCA, clustering Gene B Gene C Gene D Differential expression analysis DESeq2, edger Gene lists (TSV)
57 RNA-seq data analysis workflow
58 The steps we practise during the course
59 RNA-seq data analysis workflow Quality control of raw reads Preprocessing if needed Alignment (=mapping) to reference genome Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
60 What and why? Potential problems low confidence bases, Ns sequence specific bias, GC bias adapters sequence contamination Knowing about potential problems in your data allows you to correct for them before you spend a lot of time on analysis take them into account when interpreting results
61 Software packages for quality control FastQC FastX PRINSEQ TagCleaner...
62 Raw reads: FASTQ file format Four lines per name GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT + read name!''*((((***+))%%%++)(%%%%).1***-+*''))**55ccf>>>>>>ccccccc65 Attention: Do not unzip FASTQ files Chipster s analysis tools can cope with zipped files (.gz)
63 Base qualities If the quality of a base is 20, the probability that it is wrong is Phred quality score Q = -10 * log 10 (probability that the base is wrong) T C A G T A C T C G Sanger encoding: numbers are shown as ASCII characters so that 33 is added to the Phred score E.g. 39 is encoded as H, the 72nd ASCII character (39+33 = 72) Note that older Illumina data uses different encoding Illumina1.3: add 64 to Phred Illumina : add 64 to Phred, ASCII 66 B means that the whole read segment has low quality

64 Base quality encoding systems
 good")
65 Per position base quality (FastQC) good ok bad

66 Per position base quality (FastQC)

67 Per position sequence content (FastQC)

68 Per position sequence content (FastQC) Enrichment of k-mers at the 5 end due to use of random hexamers or transposases in the library preparation Typical for RNA-seq data Can t be corrected, doesn t usually effect the analysis
69 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Manipulation of alignment files Alignment level quality control Quantitation Experiment level quality control Visualization of reads and results in genomic context Differential expression analysis
70 Filtering vs trimming Filtering removes the entire read Trimming removes only the bad quality bases It can remove the entire read, if all bases are bad Trimming makes reads shorter This might not be optimal for some applications Paired end data: the matching order of the reads in the two files has to be preserved If a read is removed, its pair has to removed as well


71 What base quality threshold should be used? No consensus yet Trade-off between having good quality reads and having enough sequence
72 Software packages for preprocessing FastX PRINSEQ TagCleaner Trimmomatic Cutadapt TrimGalore!...
73 Trimmomatic options in Chipster Adapters Minimum quality Per base, one base at a time or in a sliding window, from 3 or 5 end Per base adaptive quality trimming (balance length and errors) Minimum (mean) read quality Trim x bases from left/ right Minimum read length after trimming Copes with paired end data
74 Was your data made with stranded protocol? You need to select the right parameters in tools later on! HISAT2, HTSeq See The tool Quality control / RNA-seq strandedness inference and inner distance estimation using RseQC allows you to check the type of strandedness in your fastq files
75 Stranded / directional RNA-seq data Several protocols available TruSeq stranded, NEB Ultra Directional, Agilent SureSelect Strand-Specific Important to indicate in alignment and quantification! Parameter naming differs in different tools HISAT2 / Cuffdiff HTSeq --stranded reverse --stranded yes --stranded no
76 Quality control : RNA-seq strandedness inference and inner distance estimation using RseQC
77 What does this ++, - - mean? Single end: ++,-- read mapped to + strand indicates parental gene on + strand read mapped to - strand indicates parental gene on - strand +-,-+ read mapped to + strand indicates parental gene on - strand read mapped to - strand indicates parental gene on + strand Paired end: 1++,1,2+-,2-+ read1 mapped to + strand indicates parental gene on + strand read1 mapped to - strand indicates parental gene on - strand read2 mapped to + strand indicates parental gene on - strand read2 mapped to - strand indicates parental gene on + strand 1+-,1-+,2++,2-- read1 mapped to + strand indicates parental gene on - strand read1 mapped to - strand indicates parental gene on + strand read2 mapped to + strand indicates parental gene on + strand read2 mapped to - strand indicates parental gene on - strand read gene gene read
78 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Manipulation of alignment files Alignment level quality control Quantitation Experiment level quality control Visualization of reads and results in genomic context Differential expression analysis
79 Alignment to reference genome Goal is to find out where a read originated from Challenge: variants, sequencing errors, repetitive sequence Many organisms have introns, so RNA-seq reads map to genome non-contiguously spliced alignments needed But sequence signals at splice sites are limited and introns can be thousands of bases long Splice-aware aligners HISAT2, TopHat STAR
80 HISAT2 HISAT = Hierarchical Indexing for Spliced Alignment of Transcripts Fast spliced aligner with low memory requirement Reference genome is indexed for fast searching Uses two types of indexes One global index: used to anchor each alignment (28 bp is enough) Thousands of small local indexes, each covering a genomic region of 56 Kbp: used for rapid extension of alignments (good for reads with short anchors over splice sites) Uses splice site information found during the alignment of earlier reads in the same run You can use the reference genomes available in Chipster, or provide your own in fasta format 87
 if you are going to do transcript assembly Note that there can an alignment that is better than the 5 reported ones Soft-clipping")
81 HISAT2 parameters Remember to set the strandedness (library type) correctly! Require long anchors (> 16 bp) if you are going to do transcript assembly Note that there can an alignment that is better than the 5 reported ones Soft-clipping 88 = read ends don t need to align to the genome, if this maximizes the alignment score
 FASTQ files for the sample Paired end data: Make filename lists first Select all read1 files and run the tool Utilities /")
82 Do you have several FASTQ files per sample? Align all of them in one HISAT2 run Single end data: Select all the (zipped) FASTQ files for the sample Paired end data: Make filename lists first Select all read1 files and run the tool Utilities / Make a list of file names Select all read2 files and and do as above Select the FASTQ files and the filename lists and run HISAT2 (check that the files have been assigned correctly)
83 STAR STAR (Spliced Transcripts Alignment to a Reference) uses a 2-pass mapping process splice junctions found during the 1 st pass are inserted into the genome index, and all reads are re-mapped in the 2nd mapping pass this doesn't increase the number of detected novel junctions, but it allows more spliced reads mapping to novel junctions. Maximum alignments per read -parameter sets the maximum number of loci the read is allowed to map to Alignments (all of them) will be output only if the read maps to no more loci than this. Otherwise no alignments will be output. Chipster offers an Ensembl GTF file to detect annotated splice junctions you can also give your own. For example the GENCODE GTF Two log files Log_final.txt lists the percentage of uniquely mapped reads etc. Log_progress.txt contains process summary
84 Mapping quality Confidence in read s point of origin Depends on many things, including uniqueness of the aligned region in the genome length of alignment number of mismatches and gaps Expressed in Phred scores, like base qualities Q = -10 * log 10 (probability that mapping location is wrong) Values differ in different aligners. E. g. unique mapping is 60 in HISAT2 255 in STAR 50 in TopHat
85 File format for mapped reads: BAM/SAM SAM (Sequence Alignment/Map) is a tab-delimited text file containing aligned reads. BAM is a binary (and hence more compact) form of SAM. optional header section alignment section: one line per read, containing 11 mandatory fields, followed by optional tags
86 Fields in BAM/SAM files read name flag 272 reference name 1 position mapping quality 0 CIGAR mate name * mate position 0 insert size 0 HWI-EAS229_1:2:40:1280:283 49M6183N26M sequence AGGGCCGATCTTGGTGCCATCCAGGGGGCCTCTACAAGGAT AATCTGACCTGCTGAAGATGTCTCCAGAGACCTT base qualities ECC@EEF@EB:EECFEECCCBEEEE;>5;2FBB@FBFEEFCF@F FFFCEFFFFEE>FFEFC=@A;@>1@6.+5/5 tags MD:Z:75 NH:i:7 AS:i:-8 XS:A:-
87 CIGAR string M = match or mismatch I = insertion D = deletion N = intron (in RNA-seq read alignments) S = soft clip (ignore these bases) H = hard clip (ignore and remove these bases) VN:1.3 SN:ref LN:45 r ref M2I4M1D3M = TTAGATAAAGGATACTG * The corresponding alignment Ref AGCATGTTAGATAA**GATAGCTGTGCTAGTAGGCAGTCAGCGCCAT r001 TTAGATAAAGGATA*CTG
88 Flag field in BAM Read s flag number is a sum of values E.g. 4 = unmapped, 1024 = duplicate Explained in detail at You can interpret them at
89 BAM index file (.bai) BAM files can be sorted by chromosomal coordinates and indexed for efficient retrieval of reads for a given region. The index file must have a matching name. (e.g. reads.bam and reads.bam.bai) Genome browser requires both BAM and the index file. The alignment tools in Chipster automatically produce sorted and indexed BAMs. When you import BAM files, Chipster asks if you would like to preproces them (convert SAM to BAM, sort and index BAM).
90 Alignment level quality checks How many reads mapped to the reference? How many of them mapped uniquely? How many pairs mapped? How many pairs mapped concordantly? Mapping quality distribution? Example report from Samtools Flagstat command in total (QC-passed reads + QC-failed reads) duplicates mapped (100.00%:-nan%) paired in sequencing read read properly paired (80.74%:-nan%) with itself and mate mapped singletons (15.02%:-nan%) with mate mapped to a different chr with mate mapped to a different chr (mapq>=5)
91 Manipulating BAM files (SAMtools, Picard) Convert SAM to BAM, sort and index BAM Preprocessing when importing SAM/BAM, runs on your computer. The tool available in the Utilities category runs on the server. Index BAM Count alignments in BAM How many alignments does the BAM contain. Includes an optional mapping quality filter. Count alignments per chromosome in BAM Count alignment statistics for BAM Collect multiple metrics for BAM Retrieve alignments for a given chromosome/region Makes a subset of BAM, e.g. chr1: , inc quality filter.
92 Control 1 Control 2 Control 3 Sample 1 Sample 2 Sample 3 RNA-seq data analysis: steps, tools and files STEP TOOL FILE Quality control FastQC FASTQ FASTQ FASTQ Preprocessing Trimmomatic FASTQ FASTQ FASTQ Alignment HISAT2 BAM BAM BAM gene A gene B Quality control Quantitation RSeQC HTSeq Read Read count file Read count file (TSV) count file (TSV) (TSV) Combine count files to table Define NGS experiment Read count table (TSV) Gene A Quality control PCA, clustering Gene B Gene C Gene D Differential expression analysis DESeq2, edger Gene lists (TSV)
93 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
94 Annotation-based quality metrics Saturation of sequencing depth Would more sequencing detect more genes and splice junctions? Read distribution between different genomic features Exonic, intronic, intergenic regions Coding, 3 and 5 UTR exons Protein coding genes, pseudogenes, rrna, mirna, etc Is read coverage uniform along transcripts? Biases introduced in library construction and sequencing polya capture and polyt priming can cause 3 bias random primers can cause sequence-specific bias GC-rich and GC-poor regions can be under-sampled Genomic regions have different mappabilities (uniqueness)
95 Quality control programs for aligned reads RseQC (available in Chipster) RNA-seqQC Qualimap Picards s CollectRnaSeqMetrics

96 Quality assessment with RseQC Checks coverage uniformity, saturation of sequencing depth, novelty of splice junctions, read distribution between different genomic regions, etc. Takes a BAM file and a BED file Chipster has BED files available for several organisms You can also use your own BED if you prefer
 in a genome 5 obligatory columns: chr, start, end, name, score 0-based, like")
97 BED file format BED (Browser extensible data) file format is used for reporting location of features (e.g. genes and exons) in a genome 5 obligatory columns: chr, start, end, name, score 0-based, like BAM
98 Own BED? Check chromosome names RseQC needs the same chromosome naming in BAM and BED Chromosome names in BED files can have the prefix chr e.g. chr1 Chipster BAM files are Ensembl-based and don t have the prefix If you use your own BED (e.g. from UCSC Table browser) you need to remove the prefix (chr1 1) Use the tool Utilities / Modify text with the following parameters: Operation = Replace text Search string = chr Input file format = BED
99 QC tables by RseQC (alignment, actually ) Default=30 Total records: 7 Non primary hits: 4 Total reads: 3 Total tags: 8 Read B Read B Read A Read A Read A Read A Read C Reference
100 Did I accidentally sequence ribosomal RNA? The majority of RNA in cells is rrna Typically we want to sequence protein coding genes, so we try to avoid rrna polya capture Ribominus kit (may not work consistently between samples) How to check if we managed to avoid rrna? RseQC might not be able to tell, if the rrna genes are not in the BED file (e.g. in human the rrna gene repeating unit has not been assigned to any chromosome yet) You can map the reads to human ribosomal DNA repeating unit sequence (instead of the genome) with the Bowtie aligner, and check the alignment percentage
101 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
102 Software for counting aligned reads per genomic features (genes/exons/transcripts) HTSeq Cufflinks StringTie Kallisto Salmon express BEDTools...
103 Counting reads per genes with HTSeq Given a BAM file and a list of gene locations, counts how many reads map to each gene. A gene is considered as the union of all its exons. Reads can be counted also per exons. Locations need to be supplied in GTF file Note that GTF and BAM must use the same chromosome naming Multimapping reads and ambiguous reads are not counted 3 modes to handle reads which overlap several genes Union (default), Intersection-strict, Intersection-nonempty Attention: was your data made with stranded protocol? You need to select the right counting mode!


104 Stranded / directional RNA-seq data Several protocols available TruSeq stranded, NEB Ultra Directional, Agilent SureSelect Strand-Specific Make sure that you set the strandedness parameter correctly HISAT2 / Cuffdiff HTSeq --stranded reverse --stranded yes --stranded no
105 Not unique or ambiguous? read Ambiguous read Stranded data Not ambiguous read A read A Multimapping (not unique)

106 HTSeq count modes

107 GTF file format 9 obligatory columns: chr, source, name, start, end, score, strand, frame, attribute 1-based For HTSeq to work, all exons of a gene must have the same gene_id Use GTFs from Ensembl, avoid UCSC
108 Estimating gene expression at gene level - the isoform switching problem Trapnell et al. Nature Biotechnology 2013
109 Control 1 Control 2 Control 3 Sample 1 Sample 2 Sample 3 Control 1 Control 1 Control 1 Control 1 Control 1 Control 1 Combine individual count files into a count table Select all the count files and run Utilities / Define NGS experiment This creates a table of counts and a phenodata file, where you can describe experimental groups Gene A 6 Gene A 6 Gene A 6 Gene AGene A Gene 6 A 6 6 Gene B 11 Gene B 11 Gene B 11 Gene BGene B Gene 11 B Gene C 200 Gene C 200 Gene C 200 Gene CGene C Gene 200 C Gene D 0 Gene D 0 Gene DGene D Gene 0 DGene D Read Read counts Read counts Read (TSV, counts (TSV, counts Read table) (TSV, table) (TSV, counts table) table) (TSV, table) table) Gene A Gene B Gene C Gene D Read table (TSV, table) phenodata

110 Phenodata file: describe the experiment Describe experimental groups, time, pairing etc with numbers e.g. 1 = control, 2 = cancer Define sample names for visualizations in the Description column

111 What if somebody gives you a count table? Make sure that the filename ending is tsv When importing the file to Chipster select Use Import tool In Import tool Mark the title row Mark the identifier column and the count columns Select the imported files and run the tool Utilities / Preprocess count table This creates a count table and a phenodata file for it
112 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
113 Experiment level quality control Getting an overview of similarities and dissimilarities between samples allows you to check Do the experimental groups separate from each other? Is there a confounding factor (e.g. batch effect) that should be taken into account in the statistical analysis? Are there sample outliers that should be removed? Several methods available MDS (multidimensional scaling) PCA (principal component analysis) Clustering
114 2 nd principle component (5%) 2 nd principle component (25%) What are we looking for? Do the experimental groups separate from each other? Is there a confounding factor (e.g. batch effect)? If the 2 nd component explains only little variance, it can ignored Outliers? 4 Outlier? Cancer Normal Gender? Age? Method? st principle component (40%) 1 st principle component (40%)
115 PCA plot by DESeq2 The first two principal components, calculated after variance stabilizing transformation Indicates the proportion of variance explained by each component If PC2 explains only a small percentage of variance, it can be ignored
116 MDS plot by edger Distances correspond to the logfc or biological coefficient of variation (BCV) between each pair of samples Calculated using 500 most heterogenous genes (that have largest dispersion when treating all samples as one group)
117 Sample heatmap by DESeq2 Euclidean distances between the samples, calculated after variance stabilizing transformation
118 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Manipulation of alignment files Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
119 Statistical testing for differential expression: things to take into account Biological replicates are important! Normalization is required in order to compare expression between samples Different library sizes RNA composition bias caused by sampling approach Raw counts are needed to assess measurement precision Counts are the the units of evidence for expression No FPKMs thanks! Multiple testing problem
120 Software packages for DE analysis edger DESeq sleuth DEXSeq Cuffdiff, Ballgown SAMseq NOIseq Limma + voom, limma + vst...
121
122 Differential gene expression analysis Normalization Dispersion estimation Log fold change estimation Statistical testing Filtering Multiple testing correction
123 Differential expression analysis: Normalization
124 Normalization For comparing gene expression between (groups of) samples, normalize for Library size (number of reads obtained) RNA composition effect The number of reads for a gene is also affected by transcript length and GC content When studying differential expression you assume that they stay the same
125 FPKM and TC are ineffective and should be definitely abandoned in the context of differential analysis In the presence of high count genes, only DESeq and TMM (edger) are able to maintain a reasonable false positive rate without any loss of power
126 Do not use RPKM/FPKM for differential expression analysis with edger and DESeq2! Reads (or fragments) per kilobase per million mapped reads. Normalizes for gene length and library size: 20 kb transcript has 400 counts, library size is 20 million reads RPKM = (400/20) / 20 = kb transcript has 10 counts, library size is 20 million reads RPKM = (10/0.5) / 20 = 1 RPKM/FPKM can be used only for reporting expression values, not for testing differential expression In DE analysis raw counts are needed to assess the measurement precision correctly
127 Normalization by edger and DESeq Aim to make normalized counts for non-differentially expressed genes similar between samples Do not aim to adjust count distributions between samples Assume that Most genes are not differentially expressed Differentially expressed genes are divided equally between up- and down-regulation Do not transform data, but use normalization factors within statistical testing
128 Normalization by edger and DESeq how? DESeq(2) Take geometric mean of gene s counts across all samples Divide gene s counts in a sample by the geometric mean Take median of these ratios sample s normalization factor (applied to read counts) edger Select as reference the sample whose upper quartile is closest to the mean upper quartile Log ratio of gene s counts in sample vs reference M value Take weighted trimmed mean of M-values (TMM) normalization factor (applied to library sizes) Trim: Exclude genes with high counts or large differences in expression Weights are from the delta method on binomial data
129 Differential expression analysis: Dispersion estimation
130 Dispersion When comparing gene s expression levels between groups, it is important to know also its within-group variability Dispersion = (BCV) 2 BCV = gene s biological coefficient of variation E.g. if gene s expression typically differs from replicate to replicate by 20% (so BCV = 0.2), then this gene s dispersion is = 0.04 Note that the variability seen in counts is a sum of 2 things: Sample-to-sample variation (dispersion) Uncertainty in measuring expression by counting reads
131 How to estimate dispersion reliably? RNA-seq experiments typically have only few replicates it is difficult to estimate within-group variability Solution: pool information across genes which are expressed at similar level assumes that genes of similar average expression strength have similar dispersion Different approaches edger DESeq2
132 Dispersion estimation by DESeq2 Estimates genewise dispersions using maximum likelihood Fits a curve to capture the dependence of these estimates on the average expression strength Shrinks genewise values towards the curve using an empirical Bayes approach The amount of shrinkage depends on several things including sample size Genes with high gene-wise dispersion estimates are dispersion outliers (blue circles above the cloud) and they are not shrunk
133 Differential expression analysis: Statistical testing
134 Generalized linear models Model the expression of each gene as a linear combination of explanatory factors (eg. group, time, patient) y = a + (b. group) + (c. time) + (d. patient) + e y = gene s expression a, b, c and d = parameters estimated from the data a = intercept (expression when factors are at reference level) e = error term Generalized linear model (GLM) allows the expression value distribution to be different from normal distribution Negative binomial distribution used for count data
135 Statistical testing edger Two group comparisons Exact test for negative binomial distribution. Multifactor experiments DESeq2 Generalized linear model, likelyhood ratio test. Shrinks log fold change estimates toward zero using an empirical Bayes method Shrinkage is stronger when counts are low, dispersion is high, or there are only a few samples Generalized linear model, Wald test for significance Shrunken estimate of log fold change is divided by its standard error and the resulting z statistic is compared to a standard normal distribution
136 Fold change shrinkage by DESeq2
137 Multiple testing correction We tests thousands of genes, so it is possible that some genes get good p-values just by chance To control this problem of false positives, p-values need to be corrected for multiple testing Several methods are available, the most popular one is the Benjamini-Hochberg correction (BH) largest p-value is not corrected second largest p = (p *n)/ (n-1) third largest p = (p * n)/(n-2) smallest p = (p * n)/(n- n+1) = p * n The adjusted p-value is FDR (false discovery rate)
138 Filtering Reduces the severity of multiple testing correction by removing some genes (makes n smaller) Filter out genes which have little chance of showing evidence for significant differential expression genes which are not expressed genes which are expressed at very low level (low counts are unreliable) Should be independent do not use information on what group the sample belongs to DESeq2 selects filtering threshold automatically
139 Summary of differential expression analysis Means of the raw counts within groups can t be compared Because library size varies & the RNA composition effect messes things up NORMALIZATION Expression values don t follow normal distribution GLM, NEGATIVE BINOMIAL DISTRIBUTION Direct (gene-wise) estimation of dispersion is not good Because there are too few replicates POOL DISPERSION INFORMATION ACROSS GENES We are doing many comparisons MULTIPLE TESTING CORRECTION, FDR
140 edger result table logfc = log2 fold change logcpm = average log2 counts per million Pvalue = raw p-value FDR = false discovery rate (Benjamini-Hochberg adjusted p- value)
141 DESeq2 result table basemean = mean of counts (divided by size factors) taken over all samples log2foldchange = log2 of the ratio meanb/meana lfcse = standard error of log2 fold change stat = Wald statistic pvalue = raw p-value padj = Benjamini-Hochberg adjusted p-value
142 Summary of differential expression analysis steps and files Quality control / Read quality with FastQC html report (Preprocessing / Trim reads with Trimmomatic FASTQ) (Utilities / Make a list of file names txt) Alignment / HISAT2 for paired end reads BAM Quality control / RNA-seq quality metrics with RseQC pdf RNA-seq / Count aligned reads per genes with HTSeq tsv Utilities / Define NGS experiment tsv Quality control / PCA and heatmap of samples with DESeq2 pdf RNA-seq / Differential expression using DESeq2 tsv Utilities / Annotate Ensembl identifiers tsv
143 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
144 Software packages for visualization Chipster genome browser IGV UCSC genome browser... Differences in memory consumption, interactivity, annotations, navigation,...
145 Chipster Genome Browser Integrated with Chipster analysis environment Automatic sorting and indexing of BAM, BED and GTF files Automatic coverage calculation (total and strand-specific) Zoom in to nucleotide level Highlight variants Jump to locations using BED, GTF, VCF and tsv files View details of selected BED, GTF and VCF features Several views (reads, coverage profile, density graph)

146

147

148
149 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
150 Experiment level quality control Getting an overview of similarities and dissimilarities between samples allows you to check Do the experimental groups separate from each other? Is there a confounding factor (e.g. batch effect) that should be taken into account in the statistical analysis? Are there sample outliers that should be removed? Several methods available MDS (multidimensional scaling) PCA (principal component analysis) Clustering
151 2 nd principle component (5%) 2 nd principle component (25%) What are we looking for? Do the experimental groups separate from each other? Is there a confounding factor (e.g. batch effect)? If the 2 nd component explains only little variance, it can ignored Outliers? 4 Outlier? Cancer Normal Gender? Age? Method? st principle component (40%) 1 st principle component (40%)

152 PCA plot by DESeq2 The first two principal components, calculated after variance stabilizing transformation Indicates the proportion of variance explained by each component If PC2 explains only a small percentage of variance, it can be ignored
153 MDS plot by edger Distances correspond to the logfc or biological coefficient of variation (BCV) between each pair of samples Calculated using 500 most heterogenous genes (that have largest dispersion when treating all samples as one group)

154 Sample heatmap by DESeq2 Euclidean distances between the samples, calculated after variance stabilizing transformation
155 RNA-seq data analysis workflow Quality control of raw reads Preprocessing (trimming / filtering) if needed Alignment (=mapping) to reference genome Manipulation of alignment files Alignment level quality control Quantitation Experiment level quality control Differential expression analysis Visualization of reads and results in genomic context
156 Statistical testing for differential expression: things to take into account Biological replicates are important! Normalization is required in order to compare expression between samples Different library sizes RNA composition bias caused by sampling approach Raw counts are needed to assess measurement precision Counts are the the units of evidence for expression No FPKMs thanks! Multiple testing problem
157 Software packages for DE analysis edger DESeq sleuth DEXSeq Cuffdiff, Ballgown SAMseq NOIseq Limma + voom, limma + vst...



158
159 Comments from comparisons Methods based on negative binomial modeling have improved specificity and sensitivity as well as good control of false positive errors Cuffdiff performance has reduced sensitivity and specificity. We postulate that the source of this is related to the normalization procedure that attempts to account for both alternative isoform expression and length of transcripts
160 Differential gene expression analysis Normalization Dispersion estimation Log fold change estimation Statistical testing Filtering Multiple testing correction
161 Differential expression analysis: Normalization
162 Normalization For comparing gene expression between (groups of) samples, normalize for Library size (number of reads obtained) RNA composition effect The number of reads for a gene is also affected by transcript length and GC content When studying differential expression you assume that they stay the same
 are able to maintain a reasonable false positive rate without any loss of")
163 FPKM and TC are ineffective and should be definitely abandoned in the context of differential analysis In the presence of high count genes, only DESeq and TMM (edger) are able to maintain a reasonable false positive rate without any loss of power
164 Do not use RPKM/FPKM for differential expression analysis with edger and DESeq2! Reads (or fragments) per kilobase per million mapped reads. Normalizes for gene length and library size: 20 kb transcript has 400 counts, library size is 20 million reads RPKM = (400/20) / 20 = kb transcript has 10 counts, library size is 20 million reads RPKM = (10/0.5) / 20 = 1 RPKM/FPKM can be used only for reporting expression values, not for testing differential expression In DE analysis raw counts are needed to assess the measurement precision correctly
165 Normalization by edger and DESeq Aim to make normalized counts for non-differentially expressed genes similar between samples Do not aim to adjust count distributions between samples Assume that Most genes are not differentially expressed Differentially expressed genes are divided equally between up- and down-regulation Do not transform data, but use normalization factors within statistical testing
166 Normalization by edger and DESeq how? DESeq(2) Take geometric mean of gene s counts across all samples Divide gene s counts in a sample by the geometric mean Take median of these ratios sample s normalization factor (applied to read counts) edger Select as reference the sample whose upper quartile is closest to the mean upper quartile Log ratio of gene s counts in sample vs reference M value Take weighted trimmed mean of M-values (TMM) normalization factor (applied to library sizes) Trim: Exclude genes with high counts or large differences in expression Weights are from the delta method on binomial data
167 Differential expression analysis: Dispersion estimation
168 Dispersion When comparing gene s expression levels between groups, it is important to know also its within-group variability Dispersion = (BCV) 2 BCV = gene s biological coefficient of variation E.g. if gene s expression typically differs from replicate to replicate by 20% (so BCV = 0.2), then this gene s dispersion is = 0.04 Note that the variability seen in counts is a sum of 2 things: Sample-to-sample variation (dispersion) Uncertainty in measuring expression by counting reads
169 How to estimate dispersion reliably? RNA-seq experiments typically have only few replicates it is difficult to estimate within-group variability Solution: pool information across genes which are expressed at similar level assumes that genes of similar average expression strength have similar dispersion Different approaches edger DESeq2
170 Dispersion estimation by DESeq2 Estimates genewise dispersions using maximum likelihood Fits a curve to capture the dependence of these estimates on the average expression strength Shrinks genewise values towards the curve using an empirical Bayes approach The amount of shrinkage depends on several things including sample size Genes with high gene-wise dispersion estimates are dispersion outliers (blue circles above the cloud) and they are not shrunk
171 Differential expression analysis: Statistical testing
172 Generalized linear models Model the expression of each gene as a linear combination of explanatory factors (eg. group, time, patient) y = a + (b. group) + (c. time) + (d. patient) + e y = gene s expression a, b, c and d = parameters estimated from the data a = intercept (expression when factors are at reference level) e = error term Generalized linear model (GLM) allows the expression value distribution to be different from normal distribution Negative binomial distribution used for count data
173 Statistical testing edger Two group comparisons Exact test for negative binomial distribution. Multifactor experiments DESeq2 Generalized linear model, likelyhood ratio test. Shrinks log fold change estimates toward zero using an empirical Bayes method Shrinkage is stronger when counts are low, dispersion is high, or there are only a few samples Generalized linear model, Wald test for significance Shrunken estimate of log fold change is divided by its standard error and the resulting z statistic is compared to a standard normal distribution

174 Fold change shrinkage by DESeq2
175 Multiple testing correction We tests thousands of genes, so it is possible that some genes get good p-values just by chance To control this problem of false positives, p-values need to be corrected for multiple testing Several methods are available, the most popular one is the Benjamini-Hochberg correction (BH) largest p-value is not corrected second largest p = (p *n)/ (n-1) third largest p = (p * n)/(n-2) smallest p = (p * n)/(n- n+1) = p * n The adjusted p-value is FDR (false discovery rate)
176 Filtering Reduces the severity of multiple testing correction by removing some genes (makes n smaller) Filter out genes which have little chance of showing evidence for significant differential expression genes which are not expressed genes which are expressed at very low level (low counts are unreliable) Should be independent do not use information on what group the sample belongs to DESeq2 selects filtering threshold automatically
177 Summary of differential expression analysis Means of the raw counts within groups can t be compared Because library size varies & the RNA composition effect messes things up NORMALIZATION Expression values don t follow normal distribution GLM, NEGATIVE BINOMIAL DISTRIBUTION Direct (gene-wise) estimation of dispersion is not good Because there are too few replicates POOL DISPERSION INFORMATION ACROSS GENES We are doing many comparisons MULTIPLE TESTING CORRECTION, FDR

178 edger result table logfc = log2 fold change logcpm = average log2 counts per million Pvalue = raw p-value FDR = false discovery rate (Benjamini-Hochberg adjusted p- value)

179 DESeq2 result table basemean = mean of counts (divided by size factors) taken over all samples log2foldchange = log2 of the ratio meanb/meana lfcse = standard error of log2 fold change stat = Wald statistic pvalue = raw p-value padj = Benjamini-Hochberg adjusted p-value
180 Summary of differential expression analysis steps and files Quality control / Read quality with FastQC html report (Preprocessing / Trim reads with Trimmomatic FASTQ) (Utilities / Make a list of file names txt) Alignment / HISAT2 for paired end reads BAM Quality control / RNA-seq quality metrics with RseQC pdf RNA-seq / Count aligned reads per genes with HTSeq tsv Utilities / Define NGS experiment tsv Quality control / PCA and heatmap of samples with DESeq2 pdf RNA-seq / Differential expression using DESeq2 tsv Utilities / Annotate Ensembl identifiers tsv
181 Design of experiments
182 When planning an experiment, consider The number of biological replicates needed. Depends on Biological variability and technical noise Expression level, fold change and sequencing depth Sample pairing Sequencing decisions Number of reads per sample (~sequencing depth) Read length (longer is better) Paired end or single end (PE is better) Stranded or unstranded (stranded is better) Batch effects
183 Relevant concepts Read depth = coverage = how many reads per each nucleotide, on average? It depends 30X 300X? With RNASeq we count reads per sample M? Read length? bp? Paired end, single end? Sequencing capacity = how many cycles, how many reads per flow cell, how many lanes in the flow cell? => depends on the device. Heterogeneity of the sample material (cell line vs. tumor sample)
184 Coverage Whole Genome Sequencing (WGS): Genotype calls 35x, INDELs 60x, SNVs 30x RNASeq: Differential expression profiling M reads, allele specific expression M Alternative splicing M De novo assembly >100 M ChiP-Seq: M (sharp peaks), M (broad)



185 Relevant concepts The device The question Read length = max. number of cycles Reads per flow cell Lanes per flow cell Multiplexing Paired end option Targeted sequencing = sequencing panels Requirement for coverage / read depth SNP, indels, de novo assembly, variant discovery, novel mutation discovery, expression analysis Mitochondria? Highly expressing genes active? The sample Tumor sample, blood sample, model organism, cell line Possible contaminations? How many samples available? Time, money, experience, availability?
186 Technical vs. biological replicates Biological replicates are separate individuals/samples Necessary for a properly controlled experiment Technical replicates are repeated sequencing runs using the same RNA isolate or sample Waste of resources? Can cause unnecessary variance reduction increases number of false positives Avoid mixing of biological and technical replicates!

187 Technical vs. biological replicates Distinction between technical and biological replicates is fuzzy. Where do we stand with cell lines?







188 Replicate number Publication quality data needs at least 3 biological replicates per sample group. This can be sufficient for cell-cultures and/or test animals More reasonable numbers: Cell cultures / test animals: 3 is minimum, 4-5 OK, >7 excellent Patients: 3 is minimum, OK, >50 good Power analysis can be used to estimate sample sizes
189 How many reads per sample do I need? Depends on the transcriptome and what you want to investigate Differential expression M reads Allele specific expression M Alternative splicing M De novo assembly >100 M More reads or more replicates?
190 Read depth / number of reads per sample Some recommendations available Heterogeneous sample => more depth needed For example tumor samples or when there is a doubt of contamination RNASeq: some highly expressed transcript may hoard all the resources Targeted panels: how well are they targeting More depth or more replicates?
191 Balance sample groups across batches You can t account for a batch effect if all your control samples were run in one batch and the drug samples in the other DESeq2 would give an error The model matrix is not full rank sample batch treatment 1 1 control 2 1 control 3 1 control 4 2 drug 5 2 drug 6 2 drug Balance sample groups cross batches sample batch treatment 1 1 control 2 1 drug 3 1 sport 4 2 control 5 2 drug 6 2 sport
192 Paired samples Use of matched samples reduces variance, as individual variation can be tackled using a matched control Pre vs. post treatment samples Tumor vs. normal samples from the same patient Example: 6 patients, 2 samples from each. Enough resources to sequence only 6 samples. Which option do you choose? Pre treatment samples P1 P2 P3 P4 P5 P6 P1 P2 P3 P4 P5 P6 VS Post treatment samples P1 P2 P3 P4 P5 P6 P1 P2 P3 P4 P5 P6
193 Pooling When possible, measure each sample on its own. If this is not possible (too expensive or not enough material), samples can be pooled to reduce variance Risk: If some of the samples are outliers, the pool is unusable Make pools as similar as possible Cell culture:
194 Pooling Make pools as similar as possible Avoid pooling of similar kinds of samples into one pool F F F M M M F M F M F M VS
195 Pooling Something to consider: What if some of your samples are outliers, or have a contamination? Cell culture:
196 Reference samples Don t compare apples to oranges! Cancer sample vs. normal sample where do you get the normal sample? Same tissue, healthy parts from the same patient? Same, healthy tissue from another patient? Similar tissue from the same patient? Blood sample from the same patient? Cell line?


197 More info & help: Example sessions in Chipster Manuals and tutorials Video tutorials in YouTube Course materials
RNA-seq data analysis with Chipster. Eija Korpelainen CSC IT Center for Science, Finland
 RNA-seq data analysis with Chipster Eija Korpelainen CSC IT Center for Science, Finland chipster@csc.fi What will I learn? 1. What you can do with Chipster and how to operate it 2. What RNA-seq can be
RNA-seq data analysis with Chipster Eija Korpelainen CSC IT Center for Science, Finland chipster@csc.fi What will I learn? 1. What you can do with Chipster and how to operate it 2. What RNA-seq can be
RNA-seq data analysis with Chipster. Eija Korpelainen CSC IT Center for Science, Finland
 RNA-seq data analysis with Chipster Eija Korpelainen CSC IT Center for Science, Finland chipster@csc.fi What will I learn? How to operate the Chipster software Short introduction to RNA-seq Analyzing RNA-seq
RNA-seq data analysis with Chipster Eija Korpelainen CSC IT Center for Science, Finland chipster@csc.fi What will I learn? How to operate the Chipster software Short introduction to RNA-seq Analyzing RNA-seq
RNA-Seq Analysis. Simon Andrews, Laura v
 RNA-Seq Analysis Simon Andrews, Laura Biggins simon.andrews@babraham.ac.uk @simon_andrews v2018-10 RNA-Seq Libraries rrna depleted mrna Fragment u u u u NNNN Random prime + RT 2 nd strand synthesis (+
RNA-Seq Analysis Simon Andrews, Laura Biggins simon.andrews@babraham.ac.uk @simon_andrews v2018-10 RNA-Seq Libraries rrna depleted mrna Fragment u u u u NNNN Random prime + RT 2 nd strand synthesis (+
ChIP-seq data analysis with Chipster. Eija Korpelainen CSC IT Center for Science, Finland
 ChIP-seq data analysis with Chipster Eija Korpelainen CSC IT Center for Science, Finland chipster@csc.fi What will I learn? Short introduction to ChIP-seq Analyzing ChIP-seq data Central concepts Analysis
ChIP-seq data analysis with Chipster Eija Korpelainen CSC IT Center for Science, Finland chipster@csc.fi What will I learn? Short introduction to ChIP-seq Analyzing ChIP-seq data Central concepts Analysis
Experimental Design. Sequencing. Data Quality Control. Read mapping. Differential Expression analysis
 -Seq Analysis Quality Control checks Reproducibility Reliability -seq vs Microarray Higher sensitivity and dynamic range Lower technical variation Available for all species Novel transcript identification
-Seq Analysis Quality Control checks Reproducibility Reliability -seq vs Microarray Higher sensitivity and dynamic range Lower technical variation Available for all species Novel transcript identification
Transcriptomics analysis with RNA seq: an overview Frederik Coppens
 Transcriptomics analysis with RNA seq: an overview Frederik Coppens Platforms Applications Analysis Quantification RNA content Platforms Platforms Short (few hundred bases) Long reads (multiple kilobases)
Transcriptomics analysis with RNA seq: an overview Frederik Coppens Platforms Applications Analysis Quantification RNA content Platforms Platforms Short (few hundred bases) Long reads (multiple kilobases)
Sequence Analysis 2RNA-Seq
 Sequence Analysis 2RNA-Seq Lecture 10 2/21/2018 Instructor : Kritika Karri kkarri@bu.edu Transcriptome Entire set of RNA transcripts in a given cell for a specific developmental stage or physiological
Sequence Analysis 2RNA-Seq Lecture 10 2/21/2018 Instructor : Kritika Karri kkarri@bu.edu Transcriptome Entire set of RNA transcripts in a given cell for a specific developmental stage or physiological
Sanger vs Next-Gen Sequencing
 Tools and Algorithms in Bioinformatics GCBA815/MCGB815/BMI815, Fall 2017 Week-8: Next-Gen Sequencing RNA-seq Data Analysis Babu Guda, Ph.D. Professor, Genetics, Cell Biology & Anatomy Director, Bioinformatics
Tools and Algorithms in Bioinformatics GCBA815/MCGB815/BMI815, Fall 2017 Week-8: Next-Gen Sequencing RNA-seq Data Analysis Babu Guda, Ph.D. Professor, Genetics, Cell Biology & Anatomy Director, Bioinformatics
Analysis of RNA-seq Data. Feb 8, 2017 Peikai CHEN (PHD)
") Analysis of RNA-seq Data Feb 8, 2017 Peikai CHEN (PHD) Outline What is RNA-seq? What can RNA-seq do? How is RNA-seq measured? How to process RNA-seq data: the basics How to visualize and diagnose your
Analysis of RNA-seq Data Feb 8, 2017 Peikai CHEN (PHD) Outline What is RNA-seq? What can RNA-seq do? How is RNA-seq measured? How to process RNA-seq data: the basics How to visualize and diagnose your
Transcriptome analysis
 Statistical Bioinformatics: Transcriptome analysis Stefan Seemann seemann@rth.dk University of Copenhagen April 11th 2018 Outline: a) How to assess the quality of sequencing reads? b) How to normalize
Statistical Bioinformatics: Transcriptome analysis Stefan Seemann seemann@rth.dk University of Copenhagen April 11th 2018 Outline: a) How to assess the quality of sequencing reads? b) How to normalize
Introduction of RNA-Seq Analysis
 Introduction of RNA-Seq Analysis Jiang Li, MS Bioinformatics System Engineer I Center for Quantitative Sciences(CQS) Vanderbilt University September 21, 2012 Goal of this talk 1. Act as a practical resource
Introduction of RNA-Seq Analysis Jiang Li, MS Bioinformatics System Engineer I Center for Quantitative Sciences(CQS) Vanderbilt University September 21, 2012 Goal of this talk 1. Act as a practical resource
RNA-Seq analysis using R: Differential expression and transcriptome assembly
 RNA-Seq analysis using R: Differential expression and transcriptome assembly Beibei Chen Ph.D BICF 12/7/2016 Agenda Brief about RNA-seq and experiment design Gene oriented analysis Gene quantification
RNA-Seq analysis using R: Differential expression and transcriptome assembly Beibei Chen Ph.D BICF 12/7/2016 Agenda Brief about RNA-seq and experiment design Gene oriented analysis Gene quantification
RNAseq Applications in Genome Studies. Alexander Kanapin, PhD Wellcome Trust Centre for Human Genetics, University of Oxford
 RNAseq Applications in Genome Studies Alexander Kanapin, PhD Wellcome Trust Centre for Human Genetics, University of Oxford RNAseq Protocols Next generation sequencing protocol cdna, not RNA sequencing
RNAseq Applications in Genome Studies Alexander Kanapin, PhD Wellcome Trust Centre for Human Genetics, University of Oxford RNAseq Protocols Next generation sequencing protocol cdna, not RNA sequencing
Gene Expression analysis with RNA-Seq data
 Gene Expression analysis with RNA-Seq data C3BI Hands-on NGS course November 24th 2016 Frédéric Lemoine Plan 1. 2. Quality Control 3. Read Mapping 4. Gene Expression Analysis 5. Splicing/Transcript Analysis
Gene Expression analysis with RNA-Seq data C3BI Hands-on NGS course November 24th 2016 Frédéric Lemoine Plan 1. 2. Quality Control 3. Read Mapping 4. Gene Expression Analysis 5. Splicing/Transcript Analysis
How to deal with your RNA-seq data?
 How to deal with your RNA-seq data? Rachel Legendre, Thibault Dayris, Adrien Pain, Claire Toffano-Nioche, Hugo Varet École de bioinformatique AVIESAN-IFB 2017 1 Rachel Legendre Bioinformatics 27/11/2018
How to deal with your RNA-seq data? Rachel Legendre, Thibault Dayris, Adrien Pain, Claire Toffano-Nioche, Hugo Varet École de bioinformatique AVIESAN-IFB 2017 1 Rachel Legendre Bioinformatics 27/11/2018
Quantifying gene expression
 Quantifying gene expression Genome GTF (annotation)? Sequence reads FASTQ FASTQ (+reference transcriptome index) Quality control FASTQ Alignment to Genome: HISAT2, STAR (+reference genome index) (known
Quantifying gene expression Genome GTF (annotation)? Sequence reads FASTQ FASTQ (+reference transcriptome index) Quality control FASTQ Alignment to Genome: HISAT2, STAR (+reference genome index) (known
Applications of short-read
 Applications of short-read sequencing: RNA-Seq and ChIP-Seq BaRC Hot Topics March 2013 George Bell, Ph.D. http://jura.wi.mit.edu/bio/education/hot_topics/ Sequencing applications RNA-Seq includes experiments
Applications of short-read sequencing: RNA-Seq and ChIP-Seq BaRC Hot Topics March 2013 George Bell, Ph.D. http://jura.wi.mit.edu/bio/education/hot_topics/ Sequencing applications RNA-Seq includes experiments
Next Generation Sequencing
 Next Generation Sequencing Complete Report Catalogue # and Service: IR16001 rrna depletion (human, mouse, or rat) IR11081 Total RNA Sequencing (80 million reads, 2x75 bp PE) Xxxxxxx - xxxxxxxxxxxxxxxxxxxxxx
Next Generation Sequencing Complete Report Catalogue # and Service: IR16001 rrna depletion (human, mouse, or rat) IR11081 Total RNA Sequencing (80 million reads, 2x75 bp PE) Xxxxxxx - xxxxxxxxxxxxxxxxxxxxxx
Introduction to RNA sequencing
 Introduction to RNA sequencing Bioinformatics perspective Olga Dethlefsen NBIS, National Bioinformatics Infrastructure Sweden November 2017 Olga (NBIS) RNA-seq November 2017 1 / 49 Outline Why sequence
Introduction to RNA sequencing Bioinformatics perspective Olga Dethlefsen NBIS, National Bioinformatics Infrastructure Sweden November 2017 Olga (NBIS) RNA-seq November 2017 1 / 49 Outline Why sequence
Ecole de Bioinforma(que AVIESAN Roscoff 2014 GALAXY INITIATION. A. Lermine U900 Ins(tut Curie, INSERM, Mines ParisTech
 GALAXY INITIATION A. Lermine U900 Ins(tut Curie, INSERM, Mines ParisTech How does Next- Gen sequencing work? DNA fragmentation Size selection and clonal amplification Massive parallel sequencing ACCGTTTGCCG
GALAXY INITIATION A. Lermine U900 Ins(tut Curie, INSERM, Mines ParisTech How does Next- Gen sequencing work? DNA fragmentation Size selection and clonal amplification Massive parallel sequencing ACCGTTTGCCG
Sequencing applications. Today's outline. Hands-on exercises. Applications of short-read sequencing: RNA-Seq and ChIP-Seq
 Sequencing applications Applications of short-read sequencing: RNA-Seq and ChIP-Seq BaRC Hot Topics March 2013 George Bell, Ph.D. http://jura.wi.mit.edu/bio/education/hot_topics/ RNA-Seq includes experiments
Sequencing applications Applications of short-read sequencing: RNA-Seq and ChIP-Seq BaRC Hot Topics March 2013 George Bell, Ph.D. http://jura.wi.mit.edu/bio/education/hot_topics/ RNA-Seq includes experiments
Introduction to transcriptome analysis using High Throughput Sequencing technologies. D. Puthier 2012
 Introduction to transcriptome analysis using High Throughput Sequencing technologies D. Puthier 2012 A typical RNA-Seq experiment Library construction Protocol variations Fragmentation methods RNA: nebulization,
Introduction to transcriptome analysis using High Throughput Sequencing technologies D. Puthier 2012 A typical RNA-Seq experiment Library construction Protocol variations Fragmentation methods RNA: nebulization,
RNA-Seq Module 2 From QC to differential gene expression.
 RNA-Seq Module 2 From QC to differential gene expression. Ying Zhang Ph.D, Informatics Analyst Research Informatics Support System (RISS) MSI Apr. 24, 2012 RNA-Seq Tutorials Tutorial 1: Introductory (Mar.
RNA-Seq Module 2 From QC to differential gene expression. Ying Zhang Ph.D, Informatics Analyst Research Informatics Support System (RISS) MSI Apr. 24, 2012 RNA-Seq Tutorials Tutorial 1: Introductory (Mar.
Introduction to RNA-Seq in GeneSpring NGS Software
 Introduction to RNA-Seq in GeneSpring NGS Software Dipa Roy Choudhury, Ph.D. Strand Scientific Intelligence and Agilent Technologies Learn more at www.genespring.com Introduction to RNA-Seq In a few years,
Introduction to RNA-Seq in GeneSpring NGS Software Dipa Roy Choudhury, Ph.D. Strand Scientific Intelligence and Agilent Technologies Learn more at www.genespring.com Introduction to RNA-Seq In a few years,
10/06/2014. RNA-Seq analysis. With reference assembly. Cormier Alexandre, PhD student UMR8227, Algal Genetics Group
 RNA-Seq analysis With reference assembly Cormier Alexandre, PhD student UMR8227, Algal Genetics Group Summary 2 Typical RNA-seq workflow Introduction Reference genome Reference transcriptome Reference
RNA-Seq analysis With reference assembly Cormier Alexandre, PhD student UMR8227, Algal Genetics Group Summary 2 Typical RNA-seq workflow Introduction Reference genome Reference transcriptome Reference
NGS Data Analysis and Galaxy
 NGS Data Analysis and Galaxy University of Pretoria Pretoria, South Africa 14-18 October 2013 Dave Clements, Emory University http://galaxyproject.org/ Fourie Joubert, Burger van Jaarsveld Bioinformatics
NGS Data Analysis and Galaxy University of Pretoria Pretoria, South Africa 14-18 October 2013 Dave Clements, Emory University http://galaxyproject.org/ Fourie Joubert, Burger van Jaarsveld Bioinformatics
C3BI. VARIANTS CALLING November Pierre Lechat Stéphane Descorps-Declère
 C3BI VARIANTS CALLING November 2016 Pierre Lechat Stéphane Descorps-Declère General Workflow (GATK) software websites software bwa picard samtools GATK IGV tablet vcftools website http://bio-bwa.sourceforge.net/
C3BI VARIANTS CALLING November 2016 Pierre Lechat Stéphane Descorps-Declère General Workflow (GATK) software websites software bwa picard samtools GATK IGV tablet vcftools website http://bio-bwa.sourceforge.net/
1. Introduction Gene regulation Genomics and genome analyses
 1. Introduction Gene regulation Genomics and genome analyses 2. Gene regulation tools and methods Regulatory sequences and motif discovery TF binding sites Databases 3. Technologies Microarrays Deep sequencing
1. Introduction Gene regulation Genomics and genome analyses 2. Gene regulation tools and methods Regulatory sequences and motif discovery TF binding sites Databases 3. Technologies Microarrays Deep sequencing
Deep Sequencing technologies
 Deep Sequencing technologies Gabriela Salinas 30 October 2017 Transcriptome and Genome Analysis Laboratory http://www.uni-bc.gwdg.de/index.php?id=709 Microarray and Deep-Sequencing Core Facility University
Deep Sequencing technologies Gabriela Salinas 30 October 2017 Transcriptome and Genome Analysis Laboratory http://www.uni-bc.gwdg.de/index.php?id=709 Microarray and Deep-Sequencing Core Facility University
ChIP-seq and RNA-seq. Farhat Habib
 ChIP-seq and RNA-seq Farhat Habib fhabib@iiserpune.ac.in Biological Goals Learn how genomes encode the diverse patterns of gene expression that define each cell type and state. Protein-DNA interactions
ChIP-seq and RNA-seq Farhat Habib fhabib@iiserpune.ac.in Biological Goals Learn how genomes encode the diverse patterns of gene expression that define each cell type and state. Protein-DNA interactions
Expression data analysis with Chipster. Eija Korpelainen, Massimiliano Gentile
 Expression data analysis with Chipster Eija Korpelainen, Massimiliano Gentile chipster@csc.fi Understanding data analysis - why? Bioinformaticians might not always be available when needed Biologists know
Expression data analysis with Chipster Eija Korpelainen, Massimiliano Gentile chipster@csc.fi Understanding data analysis - why? Bioinformaticians might not always be available when needed Biologists know
Introduction to RNA-Seq. David Wood Winter School in Mathematics and Computational Biology July 1, 2013
 Introduction to RNA-Seq David Wood Winter School in Mathematics and Computational Biology July 1, 2013 Abundance RNA is... Diverse Dynamic Central DNA rrna Epigenetics trna RNA mrna Time Protein Abundance
Introduction to RNA-Seq David Wood Winter School in Mathematics and Computational Biology July 1, 2013 Abundance RNA is... Diverse Dynamic Central DNA rrna Epigenetics trna RNA mrna Time Protein Abundance
RNA-Seq de novo assembly training
 RNA-Seq de novo assembly training Training session aims Give you some keys elements to look at during read quality check. Transcriptome assembly is not completely a strait forward process : Multiple strategies
RNA-Seq de novo assembly training Training session aims Give you some keys elements to look at during read quality check. Transcriptome assembly is not completely a strait forward process : Multiple strategies
RNA
 RNA sequencing Michael Inouye Baker Heart and Diabetes Institute Univ of Melbourne / Monash Univ Summer Institute in Statistical Genetics 2017 Integrative Genomics Module Seattle @minouye271 www.inouyelab.org
RNA sequencing Michael Inouye Baker Heart and Diabetes Institute Univ of Melbourne / Monash Univ Summer Institute in Statistical Genetics 2017 Integrative Genomics Module Seattle @minouye271 www.inouyelab.org
RNAseq Differential Gene Expression Analysis Report
 RNAseq Differential Gene Expression Analysis Report Customer Name: Institute/Company: Project: NGS Data: Bioinformatics Service: IlluminaHiSeq2500 2x126bp PE Differential gene expression analysis Sample
RNAseq Differential Gene Expression Analysis Report Customer Name: Institute/Company: Project: NGS Data: Bioinformatics Service: IlluminaHiSeq2500 2x126bp PE Differential gene expression analysis Sample
VM origin. Okeanos: Image Trinity_U16 (upgrade to Ubuntu16.04, thanks to Alexandros Dimopoulos) X2go: LXDE
 X2go: LXDE") VM origin Okeanos: Image Trinity_U16 (upgrade to Ubuntu16.04, thanks to Alexandros Dimopoulos) X2go: LXDE NGS intro + Genome-Based Transcript Reconstruction and Analysis Using RNA-Seq Data Based on material
VM origin Okeanos: Image Trinity_U16 (upgrade to Ubuntu16.04, thanks to Alexandros Dimopoulos) X2go: LXDE NGS intro + Genome-Based Transcript Reconstruction and Analysis Using RNA-Seq Data Based on material
BST 226 Statistical Methods for Bioinformatics David M. Rocke. March 10, 2014 BST 226 Statistical Methods for Bioinformatics 1
 BST 226 Statistical Methods for Bioinformatics David M. Rocke March 10, 2014 BST 226 Statistical Methods for Bioinformatics 1 NGS Technologies Illumina Sequencing HiSeq 2500 & MiSeq PacBio Sequencing PacBio
BST 226 Statistical Methods for Bioinformatics David M. Rocke March 10, 2014 BST 226 Statistical Methods for Bioinformatics 1 NGS Technologies Illumina Sequencing HiSeq 2500 & MiSeq PacBio Sequencing PacBio
Introduction to RNAseq Analysis. Milena Kraus Apr 18, 2016
 Introduction to RNAseq Analysis Milena Kraus Apr 18, 2016 Agenda What is RNA sequencing used for? 1. Biological background 2. From wet lab sample to transcriptome a. Experimental procedure b. Raw data
Introduction to RNAseq Analysis Milena Kraus Apr 18, 2016 Agenda What is RNA sequencing used for? 1. Biological background 2. From wet lab sample to transcriptome a. Experimental procedure b. Raw data
Differential gene expression analysis using RNA-seq
 https://abc.med.cornell.edu/ Differential gene expression analysis using RNA-seq Applied Bioinformatics Core, August 2017 Friederike Dündar with Luce Skrabanek & Ceyda Durmaz Day 3 QC of aligned reads
https://abc.med.cornell.edu/ Differential gene expression analysis using RNA-seq Applied Bioinformatics Core, August 2017 Friederike Dündar with Luce Skrabanek & Ceyda Durmaz Day 3 QC of aligned reads
RNA-seq Data Analysis
 Lecture 3. Clustering; Function/Pathway Enrichment analysis RNA-seq Data Analysis Qi Sun Bioinformatics Facility Biotechnology Resource Center Cornell University Lecture 1. Map RNA-seq read to genome Lecture
Lecture 3. Clustering; Function/Pathway Enrichment analysis RNA-seq Data Analysis Qi Sun Bioinformatics Facility Biotechnology Resource Center Cornell University Lecture 1. Map RNA-seq read to genome Lecture
Parts of a standard FastQC report
 FastQC FastQC, written by Simon Andrews of Babraham Bioinformatics, is a very popular tool used to provide an overview of basic quality control metrics for raw next generation sequencing data. There are
FastQC FastQC, written by Simon Andrews of Babraham Bioinformatics, is a very popular tool used to provide an overview of basic quality control metrics for raw next generation sequencing data. There are
ChIP-seq and RNA-seq
 ChIP-seq and RNA-seq Biological Goals Learn how genomes encode the diverse patterns of gene expression that define each cell type and state. Protein-DNA interactions (ChIPchromatin immunoprecipitation)
ChIP-seq and RNA-seq Biological Goals Learn how genomes encode the diverse patterns of gene expression that define each cell type and state. Protein-DNA interactions (ChIPchromatin immunoprecipitation)
QIAseq Targeted Panel Analysis Plugin USER MANUAL
 QIAseq Targeted Panel Analysis Plugin USER MANUAL User manual for QIAseq Targeted Panel Analysis 1.1 Windows, macos and Linux June 18, 2018 This software is for research purposes only. QIAGEN Aarhus Silkeborgvej
QIAseq Targeted Panel Analysis Plugin USER MANUAL User manual for QIAseq Targeted Panel Analysis 1.1 Windows, macos and Linux June 18, 2018 This software is for research purposes only. QIAGEN Aarhus Silkeborgvej
Mapping Next Generation Sequence Reads. Bingbing Yuan Dec. 2, 2010
 Mapping Next Generation Sequence Reads Bingbing Yuan Dec. 2, 2010 1 What happen if reads are not mapped properly? Some data won t be used, thus fewer reads would be aligned. Reads are mapped to the wrong
Mapping Next Generation Sequence Reads Bingbing Yuan Dec. 2, 2010 1 What happen if reads are not mapped properly? Some data won t be used, thus fewer reads would be aligned. Reads are mapped to the wrong
RNA-sequencing. Next Generation sequencing analysis Anne-Mette Bjerregaard. Center for biological sequence analysis (CBS)
") RNA-sequencing Next Generation sequencing analysis 2016 Anne-Mette Bjerregaard Center for biological sequence analysis (CBS) Terms and definitions TRANSCRIPTOME The full set of RNA transcripts and their
RNA-sequencing Next Generation sequencing analysis 2016 Anne-Mette Bjerregaard Center for biological sequence analysis (CBS) Terms and definitions TRANSCRIPTOME The full set of RNA transcripts and their
CBC Data Therapy. Metatranscriptomics Discussion
 CBC Data Therapy Metatranscriptomics Discussion Metatranscriptomics Extract RNA, subtract rrna Sequence cdna QC Gene expression, function Institute for Systems Genomics: Computational Biology Core bioinformatics.uconn.edu
CBC Data Therapy Metatranscriptomics Discussion Metatranscriptomics Extract RNA, subtract rrna Sequence cdna QC Gene expression, function Institute for Systems Genomics: Computational Biology Core bioinformatics.uconn.edu
Bioinformatics in next generation sequencing projects
 Bioinformatics in next generation sequencing projects Rickard Sandberg Assistant Professor Department of Cell and Molecular Biology Karolinska Institutet May 2013 Standard sequence library generation Illumina
Bioinformatics in next generation sequencing projects Rickard Sandberg Assistant Professor Department of Cell and Molecular Biology Karolinska Institutet May 2013 Standard sequence library generation Illumina
Introduction to RNA-Seq
 Introduction to RNA-Seq Monica Britton, Ph.D. Sr. Bioinformatics Analyst March 2015 Workshop Overview of RNA-Seq Activities RNA-Seq Concepts, Terminology, and Work Flows Using Single-End Reads and a Reference
Introduction to RNA-Seq Monica Britton, Ph.D. Sr. Bioinformatics Analyst March 2015 Workshop Overview of RNA-Seq Activities RNA-Seq Concepts, Terminology, and Work Flows Using Single-End Reads and a Reference
RNA-Seq Workshop AChemS Sunil K Sukumaran Monell Chemical Senses Center Philadelphia
 RNA-Seq Workshop AChemS 2017 Sunil K Sukumaran Monell Chemical Senses Center Philadelphia Benefits & downsides of RNA-Seq Benefits: High resolution, sensitivity and large dynamic range Independent of prior
RNA-Seq Workshop AChemS 2017 Sunil K Sukumaran Monell Chemical Senses Center Philadelphia Benefits & downsides of RNA-Seq Benefits: High resolution, sensitivity and large dynamic range Independent of prior
RNA-Seq Software, Tools, and Workflows
 RNA-Seq Software, Tools, and Workflows Monica Britton, Ph.D. Sr. Bioinformatics Analyst September 1, 2016 Some mrna-seq Applications Differential gene expression analysis Transcriptional profiling Assumption:
RNA-Seq Software, Tools, and Workflows Monica Britton, Ph.D. Sr. Bioinformatics Analyst September 1, 2016 Some mrna-seq Applications Differential gene expression analysis Transcriptional profiling Assumption:
RNA-Seq with the Tuxedo Suite
 RNA-Seq with the Tuxedo Suite Monica Britton, Ph.D. Sr. Bioinformatics Analyst September 2015 Workshop The Basic Tuxedo Suite References Trapnell C, et al. 2009 TopHat: discovering splice junctions with
RNA-Seq with the Tuxedo Suite Monica Britton, Ph.D. Sr. Bioinformatics Analyst September 2015 Workshop The Basic Tuxedo Suite References Trapnell C, et al. 2009 TopHat: discovering splice junctions with
RNA-Seq analysis workshop
 RNA-Seq analysis workshop Zhangjun Fei Boyce Thompson Institute for Plant Research USDA Robert W. Holley Center for Agriculture and Health Cornell University Outline Background of RNA-Seq Application of
RNA-Seq analysis workshop Zhangjun Fei Boyce Thompson Institute for Plant Research USDA Robert W. Holley Center for Agriculture and Health Cornell University Outline Background of RNA-Seq Application of
From Variants to Pathways: Agilent GeneSpring GX s Variant Analysis Workflow
 From Variants to Pathways: Agilent GeneSpring GX s Variant Analysis Workflow Technical Overview Import VCF Introduction Next-generation sequencing (NGS) studies have created unanticipated challenges with
From Variants to Pathways: Agilent GeneSpring GX s Variant Analysis Workflow Technical Overview Import VCF Introduction Next-generation sequencing (NGS) studies have created unanticipated challenges with
Introduction to RNA-Seq
 Introduction to RNA-Seq Monica Britton, Ph.D. Bioinformatics Analyst September 2014 Workshop Overview of Today s Activities Morning RNA-Seq Concepts, Terminology, and Work Flows Two-Condition Differential
Introduction to RNA-Seq Monica Britton, Ph.D. Bioinformatics Analyst September 2014 Workshop Overview of Today s Activities Morning RNA-Seq Concepts, Terminology, and Work Flows Two-Condition Differential
RNA Seq: Methods and Applica6ons. Prat Thiru
 RNA Seq: Methods and Applica6ons Prat Thiru 1 Outline Intro to RNA Seq Biological Ques6ons Comparison with Other Methods RNA Seq Protocol RNA Seq Applica6ons Annota6on Quan6fica6on Other Applica6ons Expression
RNA Seq: Methods and Applica6ons Prat Thiru 1 Outline Intro to RNA Seq Biological Ques6ons Comparison with Other Methods RNA Seq Protocol RNA Seq Applica6ons Annota6on Quan6fica6on Other Applica6ons Expression
Statistical Genomics and Bioinformatics Workshop. Genetic Association and RNA-Seq Studies
 Statistical Genomics and Bioinformatics Workshop: Genetic Association and RNA-Seq Studies RNA Seq and Differential Expression Analysis Brooke L. Fridley, PhD University of Kansas Medical Center 1 Next-generation
Statistical Genomics and Bioinformatics Workshop: Genetic Association and RNA-Seq Studies RNA Seq and Differential Expression Analysis Brooke L. Fridley, PhD University of Kansas Medical Center 1 Next-generation
SO YOU WANT TO DO A: RNA-SEQ EXPERIMENT MATT SETTLES, PHD UNIVERSITY OF CALIFORNIA, DAVIS
 SO YOU WANT TO DO A: RNA-SEQ EXPERIMENT MATT SETTLES, PHD UNIVERSITY OF CALIFORNIA, DAVIS SETTLES@UCDAVIS.EDU Bioinformatics Core Genome Center UC Davis BIOINFORMATICS.UCDAVIS.EDU DISCLAIMER This talk/workshop
SO YOU WANT TO DO A: RNA-SEQ EXPERIMENT MATT SETTLES, PHD UNIVERSITY OF CALIFORNIA, DAVIS SETTLES@UCDAVIS.EDU Bioinformatics Core Genome Center UC Davis BIOINFORMATICS.UCDAVIS.EDU DISCLAIMER This talk/workshop
Introduction to Next Generation Sequencing
 The Sequencing Revolution Introduction to Next Generation Sequencing Dena Leshkowitz,WIS 1 st BIOmics Workshop High throughput Short Read Sequencing Technologies Highly parallel reactions (millions to
The Sequencing Revolution Introduction to Next Generation Sequencing Dena Leshkowitz,WIS 1 st BIOmics Workshop High throughput Short Read Sequencing Technologies Highly parallel reactions (millions to
Analysis of data from high-throughput molecular biology experiments Lecture 6 (F6, RNA-seq ),
,") Analysis of data from high-throughput molecular biology experiments Lecture 6 (F6, RNA-seq ), 2012-01-26 What is a gene What is a transcriptome History of gene expression assessment RNA-seq RNA-seq analysis
Analysis of data from high-throughput molecular biology experiments Lecture 6 (F6, RNA-seq ), 2012-01-26 What is a gene What is a transcriptome History of gene expression assessment RNA-seq RNA-seq analysis
Francisco García Quality Control for NGS Raw Data
 Contents Data formats Sequence capture Fasta and fastq formats Sequence quality encoding Quality Control Evaluation of sequence quality Quality control tools Identification of artifacts & filtering Practical
Contents Data formats Sequence capture Fasta and fastq formats Sequence quality encoding Quality Control Evaluation of sequence quality Quality control tools Identification of artifacts & filtering Practical
Analysis Datasheet Exosome RNA-seq Analysis
 Analysis Datasheet Exosome RNA-seq Analysis Overview RNA-seq is a high-throughput sequencing technology that provides a genome-wide assessment of the RNA content of an organism, tissue, or cell. Small
Analysis Datasheet Exosome RNA-seq Analysis Overview RNA-seq is a high-throughput sequencing technology that provides a genome-wide assessment of the RNA content of an organism, tissue, or cell. Small
Galaxy for Next Generation Sequencing 初探次世代序列分析平台 蘇聖堯 2013/9/12
 Galaxy for Next Generation Sequencing 初探次世代序列分析平台 蘇聖堯 2013/9/12 What s Galaxy? Bringing Developers And Biologists Together. Reproducible Science Is Our Goal An open, web-based platform for data intensive
Galaxy for Next Generation Sequencing 初探次世代序列分析平台 蘇聖堯 2013/9/12 What s Galaxy? Bringing Developers And Biologists Together. Reproducible Science Is Our Goal An open, web-based platform for data intensive
Long and short/small RNA-seq data analysis
 Long and short/small RNA-seq data analysis GEF5, 4.9.2015 Sami Heikkinen, PhD, Dos. Topics 1. RNA-seq in a nutshell 2. Long vs short/small RNA-seq 3. Bioinformatic analysis work flows GEF5 / Heikkinen
Long and short/small RNA-seq data analysis GEF5, 4.9.2015 Sami Heikkinen, PhD, Dos. Topics 1. RNA-seq in a nutshell 2. Long vs short/small RNA-seq 3. Bioinformatic analysis work flows GEF5 / Heikkinen
The first thing you will see is the opening page. SeqMonk scans your copy and make sure everything is in order, indicated by the green check marks.
 Open Seqmonk Launch SeqMonk The first thing you will see is the opening page. SeqMonk scans your copy and make sure everything is in order, indicated by the green check marks. SeqMonk Analysis Page 1 Create
Open Seqmonk Launch SeqMonk The first thing you will see is the opening page. SeqMonk scans your copy and make sure everything is in order, indicated by the green check marks. SeqMonk Analysis Page 1 Create
Differential gene expression analysis using RNA-seq
 https://abc.med.cornell.edu/ Differential gene expression analysis using RNA-seq Applied Bioinformatics Core, March 2018 Friederike Dündar with Luce Skrabanek & Paul Zumbo Day 1: Introduction into high-throughput
https://abc.med.cornell.edu/ Differential gene expression analysis using RNA-seq Applied Bioinformatics Core, March 2018 Friederike Dündar with Luce Skrabanek & Paul Zumbo Day 1: Introduction into high-throughput
Experimental Design. Dr. Matthew L. Settles. Genome Center University of California, Davis
 Experimental Design Dr. Matthew L. Settles Genome Center University of California, Davis settles@ucdavis.edu What is Differential Expression Differential expression analysis means taking normalized sequencing
Experimental Design Dr. Matthew L. Settles Genome Center University of California, Davis settles@ucdavis.edu What is Differential Expression Differential expression analysis means taking normalized sequencing
measuring gene expression December 5, 2017
 measuring gene expression December 5, 2017 transcription a usually short-lived RNA copy of the DNA is created through transcription RNA is exported to the cytoplasm to encode proteins some types of RNA
measuring gene expression December 5, 2017 transcription a usually short-lived RNA copy of the DNA is created through transcription RNA is exported to the cytoplasm to encode proteins some types of RNA
Why QC? Next-Generation Sequencing: Quality Control. Illumina data format. Fastq format:
 Why QC? Next-Generation Sequencing: Quality Control BaRC Hot Topics January 2017 Bioinformatics and Research Computing Whitehead Institute Do you want to include the reads with low quality base calls?
Why QC? Next-Generation Sequencing: Quality Control BaRC Hot Topics January 2017 Bioinformatics and Research Computing Whitehead Institute Do you want to include the reads with low quality base calls?
Wheat CAP Gene Expression with RNA-Seq
 Wheat CAP Gene Expression with RNA-Seq July 9 th -13 th, 2018 Overview of the workshop, Alina Akhunova http://www.ksre.k-state.edu/igenomics/workshops/ RNA-Seq Workshop Activities Lectures Laboratory Molecular
Wheat CAP Gene Expression with RNA-Seq July 9 th -13 th, 2018 Overview of the workshop, Alina Akhunova http://www.ksre.k-state.edu/igenomics/workshops/ RNA-Seq Workshop Activities Lectures Laboratory Molecular
Next-Generation Sequencing: Quality Control
 Next-Generation Sequencing: Quality Control Bingbing Yuan BaRC Hot Topics January 2017 Bioinformatics and Research Computing Whitehead Institute http://barc.wi.mit.edu/hot_topics/ Why QC? Do you want to
Next-Generation Sequencing: Quality Control Bingbing Yuan BaRC Hot Topics January 2017 Bioinformatics and Research Computing Whitehead Institute http://barc.wi.mit.edu/hot_topics/ Why QC? Do you want to
Canadian Bioinforma3cs Workshops
 Canadian Bioinforma3cs Workshops www.bioinforma3cs.ca Module #: Title of Module 2 1 Module 3 Expression and Differen3al Expression (lecture) Obi Griffith & Malachi Griffith www.obigriffith.org ogriffit@genome.wustl.edu
Canadian Bioinforma3cs Workshops www.bioinforma3cs.ca Module #: Title of Module 2 1 Module 3 Expression and Differen3al Expression (lecture) Obi Griffith & Malachi Griffith www.obigriffith.org ogriffit@genome.wustl.edu
Incorporating Molecular ID Technology. Accel-NGS 2S MID Indexing Kits
 Incorporating Molecular ID Technology Accel-NGS 2S MID Indexing Kits Molecular Identifiers (MIDs) MIDs are indices used to label unique library molecules MIDs can assess duplicate molecules in sequencing
Incorporating Molecular ID Technology Accel-NGS 2S MID Indexing Kits Molecular Identifiers (MIDs) MIDs are indices used to label unique library molecules MIDs can assess duplicate molecules in sequencing
G E N OM I C S S E RV I C ES
 GENOMICS SERVICES ABOUT T H E N E W YOR K G E NOM E C E N T E R NYGC is an independent non-profit implementing advanced genomic research to improve diagnosis and treatment of serious diseases. Through
GENOMICS SERVICES ABOUT T H E N E W YOR K G E NOM E C E N T E R NYGC is an independent non-profit implementing advanced genomic research to improve diagnosis and treatment of serious diseases. Through
Novel methods for RNA and DNA- Seq analysis using SMART Technology. Andrew Farmer, D. Phil. Vice President, R&D Clontech Laboratories, Inc.
 Novel methods for RNA and DNA- Seq analysis using SMART Technology Andrew Farmer, D. Phil. Vice President, R&D Clontech Laboratories, Inc. Agenda Enabling Single Cell RNA-Seq using SMART Technology SMART
Novel methods for RNA and DNA- Seq analysis using SMART Technology Andrew Farmer, D. Phil. Vice President, R&D Clontech Laboratories, Inc. Agenda Enabling Single Cell RNA-Seq using SMART Technology SMART
NGS part 2: applications. Tobias Österlund
 NGS part 2: applications Tobias Österlund tobiaso@chalmers.se NGS part of the course Week 4 Friday 13/2 15.15-17.00 NGS lecture 1: Introduction to NGS, alignment, assembly Week 6 Thursday 26/2 08.00-09.45
NGS part 2: applications Tobias Österlund tobiaso@chalmers.se NGS part of the course Week 4 Friday 13/2 15.15-17.00 NGS lecture 1: Introduction to NGS, alignment, assembly Week 6 Thursday 26/2 08.00-09.45
Lecture 7. Next-generation sequencing technologies
 Lecture 7 Next-generation sequencing technologies Next-generation sequencing technologies General principles of short-read NGS Construct a library of fragments Generate clonal template populations Massively
Lecture 7 Next-generation sequencing technologies Next-generation sequencing technologies General principles of short-read NGS Construct a library of fragments Generate clonal template populations Massively
RNA-Sequencing analysis
 RNA-Sequencing analysis Markus Kreuz 25. 04. 2012 Institut für Medizinische Informatik, Statistik und Epidemiologie Content: Biological background Overview transcriptomics RNA-Seq RNA-Seq technology Challenges
RNA-Sequencing analysis Markus Kreuz 25. 04. 2012 Institut für Medizinische Informatik, Statistik und Epidemiologie Content: Biological background Overview transcriptomics RNA-Seq RNA-Seq technology Challenges
Short Read Alignment to a Reference Genome
 Short Read Alignment to a Reference Genome Shamith Samarajiwa CRUK Summer School in Bioinformatics Cambridge, September 2018 Aligning to a reference genome BWA Bowtie2 STAR GEM Pseudo Aligners for RNA-seq
Short Read Alignment to a Reference Genome Shamith Samarajiwa CRUK Summer School in Bioinformatics Cambridge, September 2018 Aligning to a reference genome BWA Bowtie2 STAR GEM Pseudo Aligners for RNA-seq
Eucalyptus gene assembly
 Eucalyptus gene assembly ACGT Plant Biotechnology meeting Charles Hefer Bioinformatics and Computational Biology Unit University of Pretoria October 2011 About Eucalyptus Most valuable and widely planted
Eucalyptus gene assembly ACGT Plant Biotechnology meeting Charles Hefer Bioinformatics and Computational Biology Unit University of Pretoria October 2011 About Eucalyptus Most valuable and widely planted
UAB DNA-Seq Analysis Workshop. John Osborne Research Associate Centers for Clinical and Translational Science
 + UAB DNA-Seq Analysis Workshop John Osborne Research Associate Centers for Clinical and Translational Science ozborn@uab.,edu + Thanks in advance You are the Guinea pigs for this workshop! At this point
+ UAB DNA-Seq Analysis Workshop John Osborne Research Associate Centers for Clinical and Translational Science ozborn@uab.,edu + Thanks in advance You are the Guinea pigs for this workshop! At this point
Data Basics. Josef K Vogt Slides by: Simon Rasmussen Next Generation Sequencing Analysis
 Data Basics Josef K Vogt Slides by: Simon Rasmussen 2017 Generalized NGS analysis Sample prep & Sequencing Data size Main data reductive steps SNPs, genes, regions Application Assembly: Compare Raw Pre-
Data Basics Josef K Vogt Slides by: Simon Rasmussen 2017 Generalized NGS analysis Sample prep & Sequencing Data size Main data reductive steps SNPs, genes, regions Application Assembly: Compare Raw Pre-
DATA FORMATS AND QUALITY CONTROL
 HTS Summer School 12-16th September 2016 DATA FORMATS AND QUALITY CONTROL Romina Petersen, University of Cambridge (rp520@medschl.cam.ac.uk) Luigi Grassi, University of Cambridge (lg490@medschl.cam.ac.uk)
HTS Summer School 12-16th September 2016 DATA FORMATS AND QUALITY CONTROL Romina Petersen, University of Cambridge (rp520@medschl.cam.ac.uk) Luigi Grassi, University of Cambridge (lg490@medschl.cam.ac.uk)
measuring gene expression December 11, 2018
 measuring gene expression December 11, 2018 Intervening Sequences (introns): how does the cell get rid of them? Splicing!!! Highly conserved ribonucleoprotein complex recognizes intron/exon junctions and
measuring gene expression December 11, 2018 Intervening Sequences (introns): how does the cell get rid of them? Splicing!!! Highly conserved ribonucleoprotein complex recognizes intron/exon junctions and
Galaxy Platform For NGS Data Analyses
 Galaxy Platform For NGS Data Analyses Weihong Yan wyan@chem.ucla.edu Collaboratory Web Site http://qcb.ucla.edu/collaboratory http://collaboratory.lifesci.ucla.edu Workshop Outline ü Day 1 UCLA galaxy
Galaxy Platform For NGS Data Analyses Weihong Yan wyan@chem.ucla.edu Collaboratory Web Site http://qcb.ucla.edu/collaboratory http://collaboratory.lifesci.ucla.edu Workshop Outline ü Day 1 UCLA galaxy
Bioinformatics Monthly Workshop Series. Speaker: Fan Gao, Ph.D Bioinformatics Resource Office The Picower Institute for Learning and Memory
 Bioinformatics Monthly Workshop Series Speaker: Fan Gao, Ph.D Bioinformatics Resource Office The Picower Institute for Learning and Memory Schedule for Fall, 2015 PILM Bioinformatics Web Server (09/21/2015)
Bioinformatics Monthly Workshop Series Speaker: Fan Gao, Ph.D Bioinformatics Resource Office The Picower Institute for Learning and Memory Schedule for Fall, 2015 PILM Bioinformatics Web Server (09/21/2015)
Exercises: Analysing ChIP-Seq data
 Exercises: Analysing ChIP-Seq data Version 2018-03-2 Exercises: Analysing ChIP-Seq data 2 Licence This manual is 2018, Simon Andrews. This manual is distributed under the creative commons Attribution-Non-Commercial-Share
Exercises: Analysing ChIP-Seq data Version 2018-03-2 Exercises: Analysing ChIP-Seq data 2 Licence This manual is 2018, Simon Andrews. This manual is distributed under the creative commons Attribution-Non-Commercial-Share
NGS in Pathology Webinar
 NGS in Pathology Webinar NGS Data Analysis March 10 2016 1 Topics for today s presentation 2 Introduction Next Generation Sequencing (NGS) is becoming a common and versatile tool for biological and medical
NGS in Pathology Webinar NGS Data Analysis March 10 2016 1 Topics for today s presentation 2 Introduction Next Generation Sequencing (NGS) is becoming a common and versatile tool for biological and medical
High performance sequencing and gene expression quantification
 High performance sequencing and gene expression quantification Ana Conesa Genomics of Gene Expression Lab Centro de Investigaciones Príncipe Felipe Valencia aconesa@cipf.es Next Generation Sequencing NGS
High performance sequencing and gene expression quantification Ana Conesa Genomics of Gene Expression Lab Centro de Investigaciones Príncipe Felipe Valencia aconesa@cipf.es Next Generation Sequencing NGS
Reads to Discovery. Visualize Annotate Discover. Small DNA-Seq ChIP-Seq Methyl-Seq. MeDIP-Seq. RNA-Seq. RNA-Seq.
 Reads to Discovery RNA-Seq Small DNA-Seq ChIP-Seq Methyl-Seq RNA-Seq MeDIP-Seq www.strand-ngs.com Analyze Visualize Annotate Discover Data Import Alignment Vendor Platforms: Illumina Ion Torrent Roche
Reads to Discovery RNA-Seq Small DNA-Seq ChIP-Seq Methyl-Seq RNA-Seq MeDIP-Seq www.strand-ngs.com Analyze Visualize Annotate Discover Data Import Alignment Vendor Platforms: Illumina Ion Torrent Roche
Introduction to transcriptome analysis using High Throughput Sequencing technologies. D. Puthier 2012
 Introduction to transcriptome analysis using High Throughput Sequencing technologies D. Puthier 2012 Transcriptome: the old school Cyanine 5 (Cy5) Cy-3: - Excitation 550nm - Emission 570nm Cy-5: - Excitation
Introduction to transcriptome analysis using High Throughput Sequencing technologies D. Puthier 2012 Transcriptome: the old school Cyanine 5 (Cy5) Cy-3: - Excitation 550nm - Emission 570nm Cy-5: - Excitation
Mapping strategies for sequence reads
 Mapping strategies for sequence reads Ernest Turro University of Cambridge 21 Oct 2013 Quantification A basic aim in genomics is working out the contents of a biological sample. 1. What distinct elements
Mapping strategies for sequence reads Ernest Turro University of Cambridge 21 Oct 2013 Quantification A basic aim in genomics is working out the contents of a biological sample. 1. What distinct elements
ChIP-seq analysis 2/28/2018
 ChIP-seq analysis 2/28/2018 Acknowledgements Much of the content of this lecture is from: Furey (2012) ChIP-seq and beyond Park (2009) ChIP-seq advantages + challenges Landt et al. (2012) ChIP-seq guidelines
ChIP-seq analysis 2/28/2018 Acknowledgements Much of the content of this lecture is from: Furey (2012) ChIP-seq and beyond Park (2009) ChIP-seq advantages + challenges Landt et al. (2012) ChIP-seq guidelines
RNA Sequencing: Experimental Planning and Data Analysis. Nadia Atallah September 12, 2018
 RNA Sequencing: Experimental Planning and Data Analysis Nadia Atallah September 12, 2018 A Next Generation Sequencing (NGS) Refresher Became commercially available in 2005 Construction of a sequencing
RNA Sequencing: Experimental Planning and Data Analysis Nadia Atallah September 12, 2018 A Next Generation Sequencing (NGS) Refresher Became commercially available in 2005 Construction of a sequencing
Course Presentation. Ignacio Medina Presentation
 Course Index Introduction Agenda Analysis pipeline Some considerations Introduction Who we are Teachers: Marta Bleda: Computational Biologist and Data Analyst at Department of Medicine, Addenbrooke's Hospital
Course Index Introduction Agenda Analysis pipeline Some considerations Introduction Who we are Teachers: Marta Bleda: Computational Biologist and Data Analyst at Department of Medicine, Addenbrooke's Hospital
Introduction to bioinformatics (NGS data analysis)
") Introduction to bioinformatics (NGS data analysis) Alexander Jueterbock 2015-06-02 1 / 45 Got your sequencing data - now, what to do with it? File size: several Gb Number of lines: >1,000,000 @M02443:17:000000000-ABPBW:1:1101:12675:1533
Introduction to bioinformatics (NGS data analysis) Alexander Jueterbock 2015-06-02 1 / 45 Got your sequencing data - now, what to do with it? File size: several Gb Number of lines: >1,000,000 @M02443:17:000000000-ABPBW:1:1101:12675:1533
Introduction to NGS analyses
 Introduction to NGS analyses Giorgio L Papadopoulos Institute of Molecular Biology and Biotechnology Bioinformatics Support Group 04/12/2015 Papadopoulos GL (IMBB, FORTH) IMBB NGS Seminar 04/12/2015 1
Introduction to NGS analyses Giorgio L Papadopoulos Institute of Molecular Biology and Biotechnology Bioinformatics Support Group 04/12/2015 Papadopoulos GL (IMBB, FORTH) IMBB NGS Seminar 04/12/2015 1
RNA-Seq. Joshua Ainsley, PhD Postdoctoral Researcher Lab of Leon Reijmers Neuroscience Department Tufts University
 RNA-Seq Joshua Ainsley, PhD Postdoctoral Researcher Lab of Leon Reijmers Neuroscience Department Tufts University joshua.ainsley@tufts.edu Day five Alternative splicing Assembly RNA edits Alternative splicing
RNA-Seq Joshua Ainsley, PhD Postdoctoral Researcher Lab of Leon Reijmers Neuroscience Department Tufts University joshua.ainsley@tufts.edu Day five Alternative splicing Assembly RNA edits Alternative splicing
Integrative Genomics 1a. Introduction
 2016 Course Outline Integrative Genomics 1a. Introduction ggibson.gt@gmail.com http://www.cig.gatech.edu 1a. Experimental Design and Hypothesis Testing (GG) 1b. Normalization (GG) 2a. RNASeq (MI) 2b. Clustering
2016 Course Outline Integrative Genomics 1a. Introduction ggibson.gt@gmail.com http://www.cig.gatech.edu 1a. Experimental Design and Hypothesis Testing (GG) 1b. Normalization (GG) 2a. RNASeq (MI) 2b. Clustering
Data Analysis with CASAVA v1.8 and the MiSeq Reporter
 Data Analysis with CASAVA v1.8 and the MiSeq Reporter Eric Smith, PhD Bioinformatics Scientist September 15 th, 2011 2010 Illumina, Inc. All rights reserved. Illumina, illuminadx, Solexa, Making Sense
Data Analysis with CASAVA v1.8 and the MiSeq Reporter Eric Smith, PhD Bioinformatics Scientist September 15 th, 2011 2010 Illumina, Inc. All rights reserved. Illumina, illuminadx, Solexa, Making Sense